本文主要是介绍数据结构(4)--循环链表的应用之约瑟夫环问题以及线性表总结之顺序表与链表的比较,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考书籍:数据结构(C语言版) 严蔚敏 吴伟民编著 清华大学出版社
本文中的代码可从这里下载:https://github.com/qingyujean/data-structure
1.循环链表应用--约瑟夫环问题
1.1问题说明
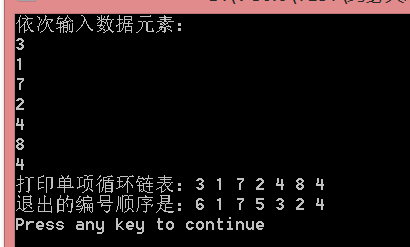
问题描述:编号为1,2,···,n的n个人围坐在一圆桌旁,每人持有一个正整数的密码。从第一个人开始报数,报到一个预先约定的正整数m时,停止报数,报m的人退席,下一个人又重新从1开始报数,依此重复,直至所有的人都退席。编一程序输出他们退席的编号序列。例如,设m=20,n=7,7个人的密码依次是3,1,7,2,4,8,4,则退席的人的编号依次为6,1,7,5,3,2,4。
基本要求:用不带表头结点的循环单链表表示围成圆圈的n个人;要求建立此循环单链表;某人离席相当于删除一个结点,要正确设置程序中循环终止的条件和删除结点时指针的修改变化。
1.2代码实现
#include<stdio.h>
#include<stdlib.h>
#define NULL 0
typedef int ElemType;
typedef struct LNode{ElemType data;ElemType sequence;LNode *next;
}LNode,*LinkList;//创建一个不带头节点的循环单向链表
void createCircularList(LinkList &L, int n){printf("依次输入数据元素:\n");//输入第一个元素,即头节点LinkList head = (LinkList)malloc(sizeof(LNode));head->sequence = 1;head->next = NULL;scanf("%d", &head->data);L = head;LinkList p = head;int i = 2;while(i <= n){LinkList s = (LinkList)malloc(sizeof(LNode));s->sequence = i;s->next = NULL;scanf("%d", &s->data);p->next = s;p = s;i++;}p->next = L;
}//打印输出单项循环链表
void printCircularList(LinkList L){printf("打印单项循环链表:");LinkList head = L;LinkList p = L->next;printf("%d ",head->data);while(p!=head){printf("%d ", p->data);p = p->next;}printf("\n");
}//约瑟夫环的实现
void josephRing(LinkList L, int m, int n){int *outNum = new int[n], num=0;//按退出顺序记录编号int count = 1;//报数LinkList p = L, q = L; while(p->next!=p){if(count%m == 0){q->next = p->next;outNum[num] = p->sequence;num++;free(p);p = q->next;count = 1;}else{q = p;p = p->next;count++;}}outNum[num] = p->sequence;printf("退出的编号顺序是:");for(int i = 0; i < n; i++){printf("%d ", outNum[i]);}printf("\n");
}//实例:设m=20,n=7,7个人的密码依次是3,1,7,2,4,8,4,
//则退席的人的编号依次为6,1,7,5,3,2,4。
int main(){LinkList L;createCircularList(L, 7);printCircularList(L);josephRing(L, 20, 7);return 0;
}
2.线性表总结之顺序表与链表的比较
线性表有两种存储结构:顺序表和链表,通过对它们的讨论可知它们各有优缺点。
顺序存储有三个优点:
(1) 方法简单,各种高级语言中都有数组,容易实现。
(2) 不用为表示结点间的逻辑关系而增加额外的存储开销。
(3) 顺序表具有按元素序号随机访问的特点。
但它也有两个缺点:
(1) 在顺序表中做插入删除操作时,平均移动大约表中一半的元素,因此对n较大的顺序表效率低。
(2) 需要预先分配足够大的存储空间,估计过大,可能会导致顺序表后部大量闲置;预先分配过小,又会造成溢出。
链表的优缺点恰好与顺序表相反。
在实际中怎样选取存储结构呢?通常有以下几点考虑:
1.基于存储的考虑
顺序表的存储空间是静态分配的,在程序执行之前必须明确规定它的存储规模,也就是说事先对“MAXSIZE(n0)"要有合适的设定,过大造成浪费,过小造成溢出。可见对线性表的长度或存储规模难以估计时,不宜采用顺序表;链表不用事先估计存储规模,但链表的存储密度较低,存储密度是指一个结点中数据元素所占的存储单元和整个结点所占的存储单元之比。显然链式存储结构的存储密度是小于1的。
2.基于运算的考虑
在顺序表中按序号访问ai的时间性能时O(1),而链表中按序号访问的时间性能O(n),所以如果经常做的运算是按序号访问数据元素,显然顺序表优于链表;而在顺序表中做插入、删除时平均移动表中一半的元素,当数据元素的信息量较大且表较长时,这一点是不应忽视的;在链表中作插入、删除,虽然也要找插入位置,但操作主要是比较操作,从这个角度考虑显然后者优于前者。
3.基于环境的考虑
顺序表容易实现,任何高级语言中都有数组类型,链表的操作是基于指针的,相对来讲前者简单些,也是用户考虑的一个因素。
总之,两中存储结构各有长短,选择那一种由实际问题中的主要因素决定。通常“较稳定”的线性表选择顺序存储,而频繁做插入删除的即动态性较强的线性表宜选择链式存储。
小结
线性表是一种最基本,最常用的数据结构。线性表有两种存储结构----顺序表和链表,以及在这两种存储结构上实现的基本运算。
顺序表是用数组实现的,链表是用指针或游标实现的。用指针来实现的链表,因为它的结点是动态分配的,故称之为动态链表;用游标模拟指针实现的链表,由于其结点空间是静态分配的,所以称之为静态链表。这两种链表又可按链接形式的不同,区分为单链表,双链表和循环链表。
在实际应用中,对线性表采用哪种存储结构,要视实际问题的要求而定,主要考虑求解算法的时间复杂度和空间复杂度。因此,建议熟练掌握在顺序表和链表上实现的各种基本运算及其时间,空间特性。
本文中的代码可从这里下载:https://github.com/qingyujean/data-structure
这篇关于数据结构(4)--循环链表的应用之约瑟夫环问题以及线性表总结之顺序表与链表的比较的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





