本文主要是介绍浏览器同源策略和CORS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
同源策略(Same origin policy)是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。可以说 Web 是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。
它的核心就在于它认为自任何站点装载的信赖内容是不安全的。当被浏览器半信半疑的脚本运行在沙箱时,它们应该只被允许访问来自同一站点的资源,而不是那些来自其它站点可能怀有恶意的资源。
所谓同源是指:域名、协议、端口相同。
下表是相对于 http://www.laixiangran.cn/home/index.html 的同源检测结果:

另外,同源策略又分为以下两种:
- DOM 同源策略:禁止对不同源页面 DOM 进行操作。这里主要场景是 iframe 跨域的情况,不同域名的 iframe 是限制互相访问的。
- XMLHttpRequest 同源策略:禁止使用 XHR 对象向不同源的服务器地址发起 HTTP 请求。
为什么要有跨域限制
因为存在浏览器同源策略,所以才会有跨域问题。那么浏览器是出于何种原因会有跨域的限制呢。其实不难想到,跨域限制主要的目的就是为了用户的上网安全。
如果浏览器没有同源策略,会存在什么样的安全问题呢。下面从 DOM 同源策略和 XMLHttpRequest 同源策略来举例说明:
如果没有 DOM 同源策略,也就是说不同域的 iframe 之间可以相互访问,那么黑客可以这样进行攻击:
- 做一个假网站,里面用 iframe 嵌套一个银行网站
http://mybank.com。 - 把 iframe 宽高啥的调整到页面全部,这样用户进来除了域名,别的部分和银行的网站没有任何差别。
- 这时如果用户输入账号密码,我们的主网站可以跨域访问到
http://mybank.com的 dom 节点,就可以拿到用户的账户密码了。
如果 XMLHttpRequest 同源策略,那么黑客可以进行 CSRF(跨站请求伪造) 攻击:
- 用户登录了自己的银行页面
http://mybank.com,http://mybank.com向用户的 cookie 中添加用户标识。 - 用户浏览了恶意页面
http://evil.com,执行了页面中的恶意 AJAX 请求代码。 http://evil.com向http://mybank.com发起 AJAX HTTP 请求,请求会默认把http://mybank.com对应 cookie 也同时发送过去。- 银行页面从发送的 cookie 中提取用户标识,验证用户无误,response 中返回请求数据。此时数据就泄露了。
- 而且由于 Ajax 在后台执行,用户无法感知这一过程。
因此,有了浏览器同源策略,我们才能更安全的上网。
跨域的解决方法
从上面我们了解到了浏览器同源策略的作用,也正是有了跨域限制,才使我们能安全的上网。但是在实际中,有时候我们需要突破这样的限制,因此下面将介绍几种跨域的解决方法。
CORS(跨域资源共享)
CORS(Cross-origin resource sharing,跨域资源共享)是一个 W3C 标准,定义了在必须访问跨域资源时,浏览器与服务器应该如何沟通。CORS 背后的基本思想,就是使用自定义的 HTTP 头部让浏览器与服务器进行沟通,从而决定请求或响应是应该成功,还是应该失败。
CORS 需要浏览器和服务器同时支持。目前,所有浏览器都支持该功能,IE 浏览器不能低于 IE10。
整个 CORS 通信过程,都是浏览器自动完成,不需要用户参与。对于开发者来说,CORS 通信与同源的 AJAX 通信没有差别,代码完全一样。浏览器一旦发现 AJAX 请求跨源,就会自动添加一些附加的头信息,有时还会多出一次附加的请求,但用户不会有感觉。
因此,实现 CORS 通信的关键是服务器。只要服务器实现了 CORS 接口,就可以跨源通信。
浏览器将CORS请求分成两类:简单请求(simple request)和非简单请求(not-so-simple request)。
只要同时满足以下两大条件,就属于简单请求。
- 请求方法是以下三种方法之一:
- HEAD
- GET
- POST
- HTTP的头信息不超出以下几种字段:
- Accept
- Accept-Language
- Content-Language
- Last-Event-ID
- Content-Type:只限于三个值 application/x-www-form-urlencoded、multipart/form-data、text/plain
凡是不同时满足上面两个条件,就属于非简单请求。
浏览器对这两种请求的处理,是不一样的。
简单请求
- 在请求中需要附加一个额外的 Origin 头部,其中包含请求页面的源信息(协议、域名和端口),以便服务器根据这个头部信息来决定是否给予响应。例如:
Origin: http://www.laixiangran.cn - 如果服务器认为这个请求可以接受,就在 Access-Control-Allow-Origin 头部中回发相同的源信息(如果是公共资源,可以回发 * ,如果要发送Cookie,
Access-Control-Allow-Origin就不能设为星号,必须指定明确的、与请求网页一致的域名)。例如:Access-Control-Allow-Origin:http://www.laixiangran.cn - 没有这个头部或者有这个头部但源信息不匹配,浏览器就会驳回请求。正常情况下,浏览器会处理请求。注意,请求和响应都不包含 cookie 信息。
- 如果需要包含 cookie 信息,ajax 请求需要设置 xhr 的属性 withCredentials 为 true,服务器需要设置响应头部
Access-Control-Allow-Credentials: true。
非简单请求
浏览器在发送真正的请求之前,会先发送一个 Preflight 请求给服务器,这种请求使用 OPTIONS 方法,发送下列头部:
- Origin:与简单的请求相同。
- Access-Control-Request-Method: 请求自身使用的方法。
- Access-Control-Request-Headers: (可选)自定义的头部信息,多个头部以逗号分隔。
例如:
Origin: http://www.laixiangran.cn
Access-Control-Request-Method: POST
Access-Control-Request-Headers: NCZ发送这个请求后,服务器可以决定是否允许这种类型的请求。服务器通过在响应中发送如下头部与浏览器进行沟通:
- Access-Control-Allow-Origin:与简单的请求相同。
- Access-Control-Allow-Methods: 允许的方法,多个方法以逗号分隔。
- Access-Control-Allow-Headers: 允许的头部,多个方法以逗号分隔。
- Access-Control-Max-Age: 应该将这个 Preflight 请求缓存多长时间(以秒表示)。
例如:
Access-Control-Allow-Origin: http://www.laixiangran.cn
Access-Control-Allow-Methods: GET, POST
Access-Control-Allow-Headers: NCZ
Access-Control-Max-Age: 1728000一旦服务器通过 Preflight 请求允许该请求之后,以后每次浏览器正常的 CORS 请求,就都跟简单请求一样了。
优点
- CORS 通信与同源的 AJAX 通信没有差别,代码完全一样,容易维护。
- 支持所有类型的 HTTP 请求。
缺点
- 存在兼容性问题,特别是 IE10 以下的浏览器。
- 第一次发送非简单请求时会多一次请求。
3、基于filter的跨域实现
这种实现方式较为简单,判断允许跨域访问后在 Response 头信息中添加 Access-Control-Allow-Origin、Access-Control-Allow-Method等字段信息。代码如下:
public class CorsFilter extends OncePerRequestFilter {private static Logger log = LoggerFactory.getLogger(CorsFilter.class);private static List<String> whiteList = new ArrayList<>();//跨域白名单static {whiteList.add("http://mall.yjc.jd.com");whiteList.add("http://jshopx.jd.com");whiteList.add("http://mall.yao.jd.com");whiteList.add("http://yao-shop.jd.com");}@Overrideprotected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {//请求的地址String originUrl = request.getHeader("origin");//查看是否在白名单里面boolean isAllow = whiteList.contains(originUrl);if (isAllow) {response.setHeader("Access-Control-Allow-Origin", originUrl);response.setHeader("Access-Control-Allow-Credentials", "true");response.setHeader("Access-Control-Allow-Methods", "POST, GET, OPTIONS");response.setHeader("Access-Control-Max-Age", "1800");//30分钟response.setHeader("Access-Control-Allow-Headers", "x-requested-with, content-type");filterChain.doFilter(request, response);}else {//对于非白名单域名的请求,不予进行访问,不然还会进入到controller方法中执行对应的逻辑return;}}
}4、@CrossOrigin注解
Spring 从4.2版本后开始支持 @CrossOrigin 注解实现跨域,这在一定程度上简化了我们实现跨域访问的开发成本,在需要跨域访问的方法或者类上加上这个注解便大功告成。但在不知晓其原理的情况下使用该注解跨域出了问题将无从下手解决。以下是 @CrossOrigin 的一些基础知识,部分设计到 Spring 框架加载 Bean 的源码。可以使用在方法上,只针对一个方法有效,可以使用在类上,对类中的所有方法都生效
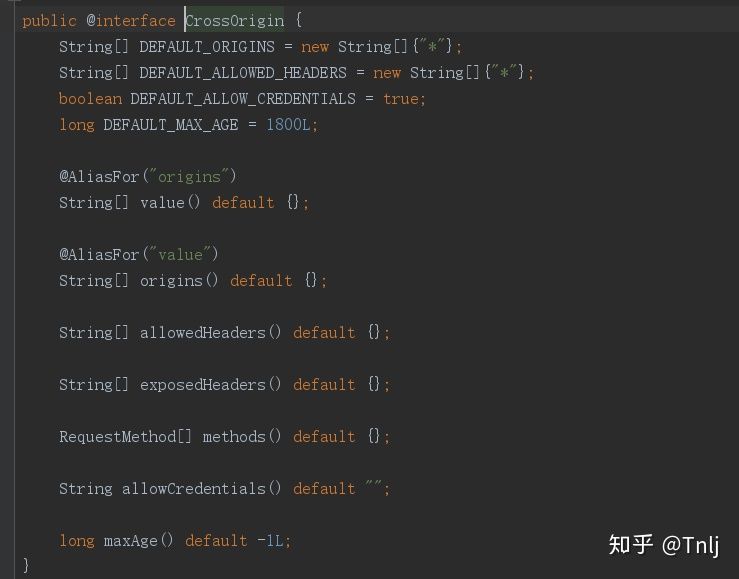
@CrossOrigin
- String[] origins: 允许来源域名的列表,例如 'www.jd.com',匹配的域名是跨域预请求 Response 头中的 'Access-Control-Aloow_origin' 字段值。不设置确切值时默认支持所有域名跨域访问。
- String[] allowedHeaders: 跨域请求中允许的请求头中的字段类型, 该值对应跨域预请求 Response 头中的 'Access-Control-Allow-Headers' 字段值。 不设置确切值默认支持所有的header字段(Cache-Controller、Content-Language、Content-Type、Expires、Last-Modified、Pragma)跨域访问。
- String[] exposedHeaders: 跨域请求请求头中允许携带的除Cache-Controller、Content-Language、Content-Type、Expires、Last-Modified、Pragma这六个基本字段之外的其他字段信息,对应的是跨域请求 Response 头中的 'Access-control-Expose-Headers'字段值。
- RequestMethod[] methods: 跨域HTTP请求中支持的HTTP请求类型(GET、POST...),不指定确切值时默认与 Controller 方法中的 methods 字段保持一致。
- String allowCredentials: 该值对应的是是跨域请求 Response 头中的 'Access-Control-Allow-Credentials' 字段值。浏览器是否将本域名下的 cookie 信息携带至跨域服务器中。默认携带至跨域服务器中,但要实现 cookie 共享还需要前端在 AJAX 请求中打开 withCredentials 属性。
- long maxAge: 该值对应的是是跨域请求 Response 头中的 'Access-Control-Max-Age' 字段值,表示预检请求响应的缓存持续的最大时间,目的是减少浏览器预检请求/响应交互的数量。默认值1800s。设置了该值后,浏览器将在设置值的时间段内对该跨域请求不再发起预请求。
这篇关于浏览器同源策略和CORS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






