本文主要是介绍交通数据三维可视化呈现与可视化分析系统开发(附程序源码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
01 系统介绍
02 功能介绍
文件管理功能
模型研究
可视化分析功能
今天分享一套“交通数据三维可视化呈现与可视化分析系统”,并开放程序源代码下载,内容涉及开源空间数据库的使用、三维引擎的二次开发、矢量和栅格数据管理、交通流量分析模型框架等,以供智慧交通相关的各位同学学习参考。
01 系统介绍
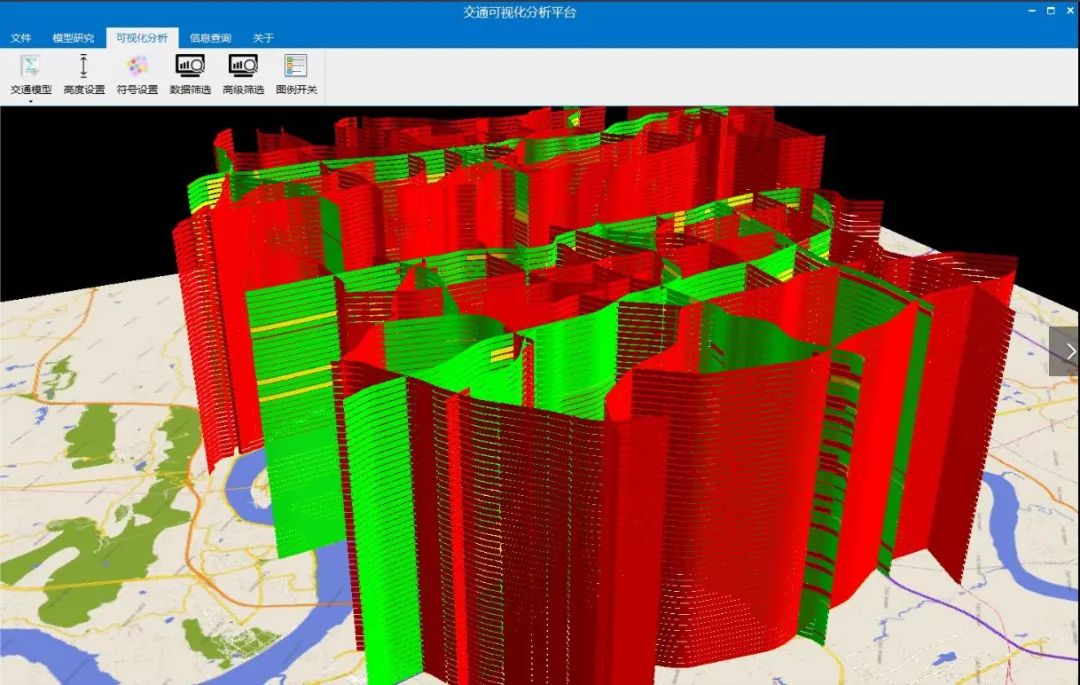
系统主界面
数据库主要包括监测流量数据、基础路网数据、路网模型数据、基础地形影像数据的处理建库。系统功能主要包括文件管理、模型研究、可视化分析、查询统计等功能模块。
02 功能介绍
文件管理功能
(1)数据源
点击数据源按钮,会弹出数据源加载界面(如图3.1),其中起始时间表示所加载数据的起始时间,结束时间表示所加载数据的结束时间,设置好时间参数以后,点击加载,勾选跳过错误(数据可能存在缺失),可将数据加载到路网上。
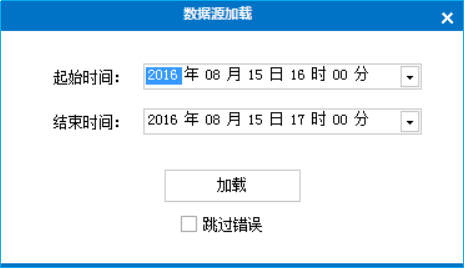
图 3.1 数据源加载
(2)打开文档。打开所保存的.csxd文件。
(3)保存文档。将文件保存到指定位置,文件保存类型为.csxd文件。
(4)导出图片。点击导出图片按钮,自定义图片保存的名字和类型,将导出软件视图所展示的图片。
(5)屏幕截图。点击屏幕截图按钮后,框选所需要截图的范围,然后点击保存,可对软件界面进行截图。
(6)底图切换。点击底图切换按钮,出现三种不同的底图可供选择(如图3.2),分别为矢量地图、影像地图、电子地图(如图3.3、3.4、3.5所示),三种地图可以自由切换,但是不能同时显示影像地图和电子地图。

图 3.2 底图切换
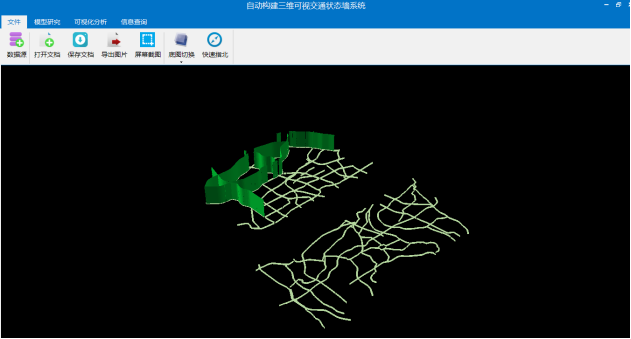
图 3.3 矢量地图
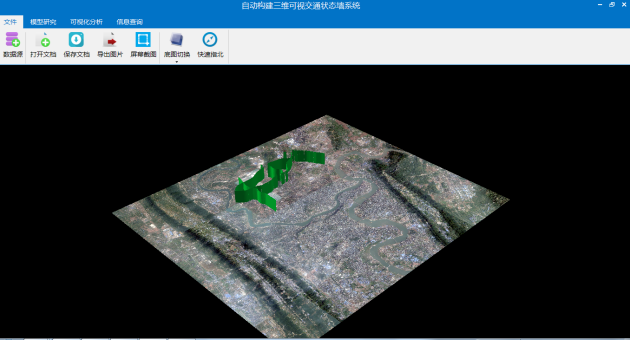
图 3.4 影像地图
图3.5 电子地图
(7)快速指北。点击快速指北按钮,软件界面中的视图会自动调整指向北方。
模型研究
(1)模型编码。
点击“模型编码”可弹出新建模型和历史构建的模型(如图3.6)。
测试模型为案例模型。新建模型可根据自己的需要新建模型,点击新建模型,会出现模型编码编辑框(如图3.7)。其中模型名称可任意填写,中英文不限;字段名称任意填写,需英文(注意:字段名称不要同已有表中字段名相同,否则会覆盖原有字段值);字段别名任意填写,中英文不限(该别名会显示在信息查询框中);表达式功能:函数表达式(例如:函数名(参数1,参数2,…参数n));代码块中利用python语句进行编程书写,自定义交通状态的划分标准(如图3.8)。“保存”和“删除”可以实现保存和删除模型的功能。

图 3.6 模型编码
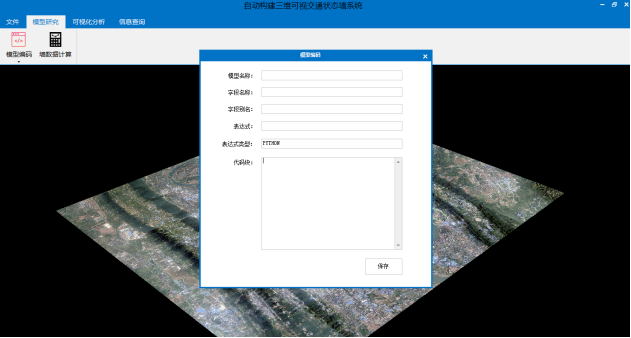
图 3.7 新建模型
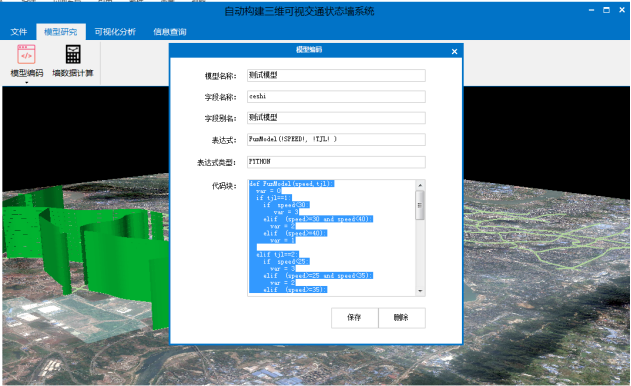
图 3.8 新建模型表达式
(2)墙数据计算。
点击墙数据计算,弹出墙数据计算框(如图3.9),在“交通模型”栏中勾选需要进行计算的模型,设置数据的起止时间,点击“计算”按钮,开始对模型中数据进行计算。待计算完成后,墙数据计算框会自动消失。
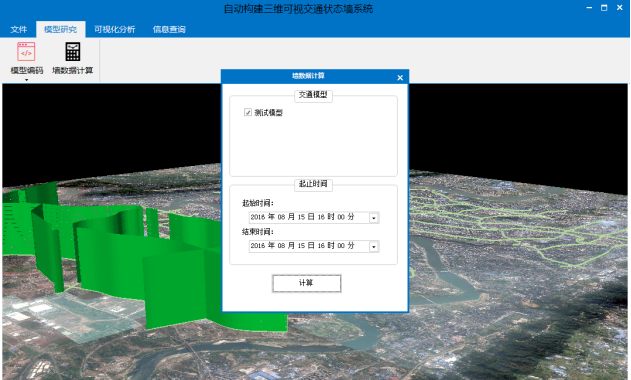
图3.9 墙数据计算
可视化分析功能
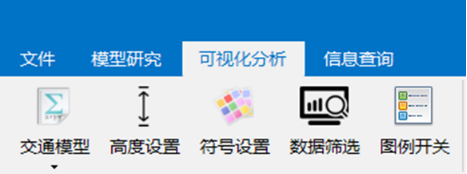
图3.10 可视化分析功能
(1)交通模型。通过选取一种“模型研究”构建的交通状态判别模型,对数据进行交通状态可视化显示。
(2)高度设置。层偏移量(单位:度):设置状态墙间隔;层挤压高度(单位:度):设置状态墙带宽。层偏移量与层挤压高度的差值就是状态墙的间隙宽度值。
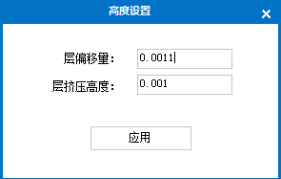
图3.11 高度设置
(3)符号设置。对不同交通状态进行不同颜色配置。可以删除、添加新的状态符合及对应的状态值。
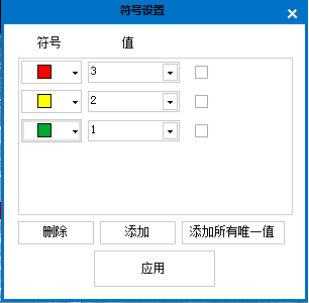
图3.12 符号设置
(4)数据筛选。模型结果:筛选交通状态;道路名称:根据道路名称进行信息筛选;道路级别:筛选主干路、次干路、支路;时间:选择任一时刻的交通状态(查询采用sql语法)
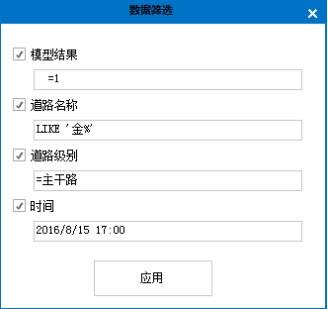
图3.13 数据筛选
(5)图例开关。结合“符号设置”的符号颜色和状态值,可以自动在视图的右上角生成对应的图例。图例可以自动进行编辑,但是不能编辑后的值不能进行保存。
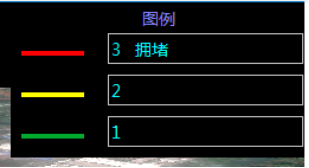
图3.14 图例设置
信息查询功能
图3.15 信息查询
(1)点击查询。可以点击视图中任一路段,显示该路段的属性信息。通过点选路段,可以显示多个路段的属性信息框。
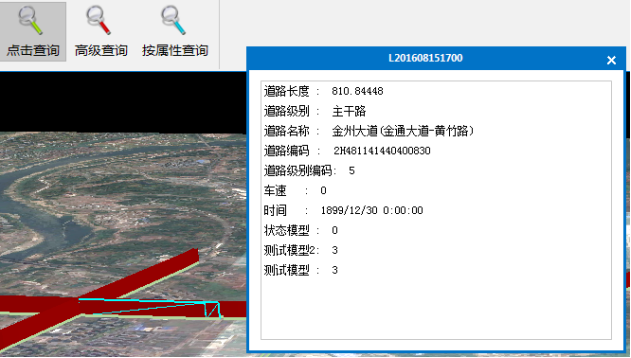
图3.16 点击查询
(2)高级查询。
通过拾取2个不同的要素,计算两个要素的时差和两个要素的距离。
重新计算前,需点击 “清除要素”。“查看要素信息”将选中的要素信息显示,通过“导出excle”,可以另存为表格。
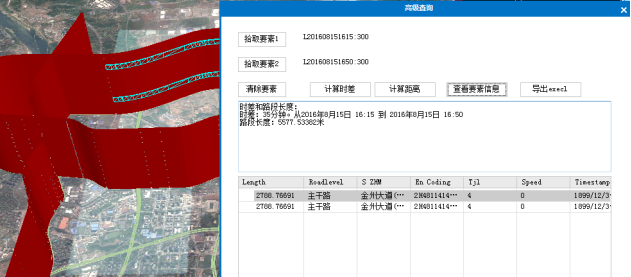
图3.17 按要素查询
按属性查询。查询某时间段内某条道路的交通状态分布情况,查询的数据以表格数据导出。
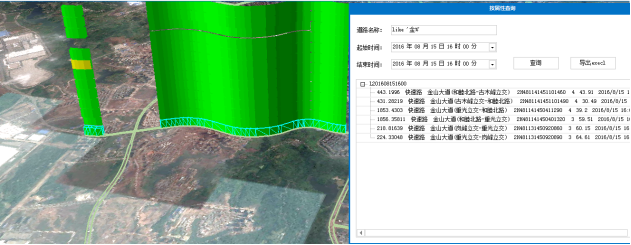
图3.18 按属性查询
进入本公众号后台,联系博主获取下载链接。
文件名:交通数据三维可视化呈现与可视化分析系统

声明:转载此文不为商业用途。文字和图片版权归原作者所有,若有来源标注错误或侵犯了您的合法权益,请与我们联系,我们将及时处理,谢谢。
注册测绘师资格考试备考建议 | 附30GB学习资料
注册测绘师历年真题及答案解析
ArcGIS中SHP转CAD如何分图层以及颜色等
AutoCAD如何加载在线/离线遥感影像地图
如何快速构建三维模型(倾斜摄影)
这篇关于交通数据三维可视化呈现与可视化分析系统开发(附程序源码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







