本文主要是介绍3d gaussian-splatting源码运行及结果展示,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
笔者是在windows下配置的环境
源码地址及官方教程
github gaussian-splatting
官网给出了详细的配置教程和视频解说
记录一下个人的部署过程
环境需求
硬件需求
具有计算能力 7.0+ 的带有CUDA的GPU
24G显存
软件需求
python版本我没注意到明确说明,3.7以上应该就可以(我用的3.12)
Anaconda (python环境管理,网上教程很多)
支持PyTorch扩展的C++编译器(VS2019)
支持PyTorch扩展的CUDA SDK 11 (笔者及官方使用的是11.8)(在cmd中使用命令nvcc --version)
第三方应用
-
ffmpeg 是一款免费,开源的音视频编解码工具及开发套件,在这里只需要用它来将视频分割成图片序列
下载链接
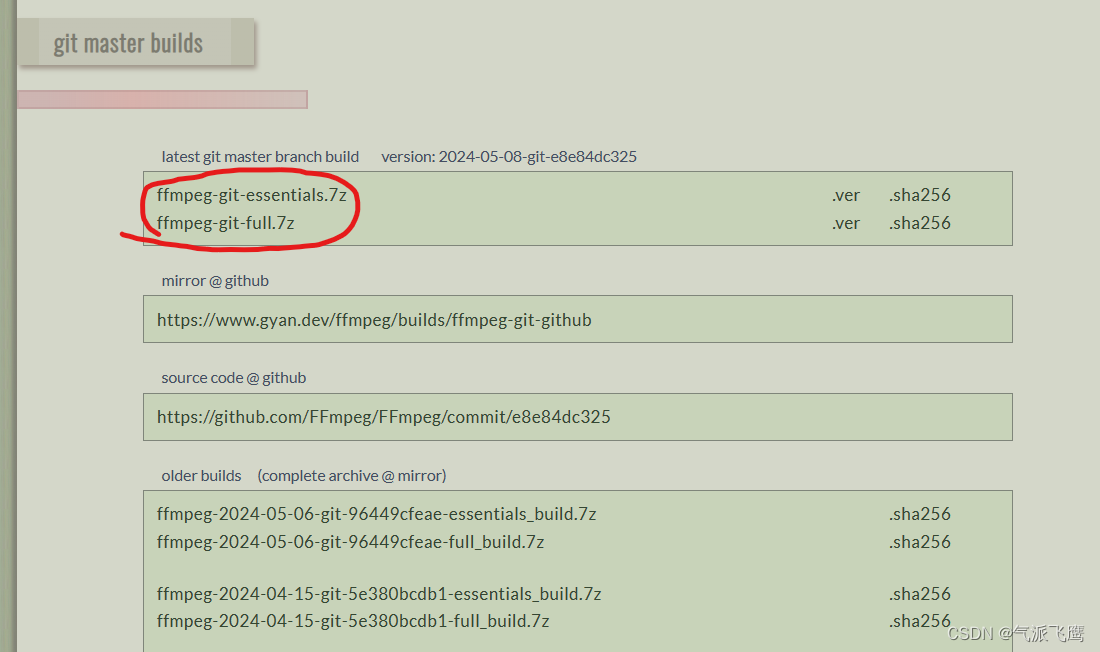
两个都可以,上面是基础版,下面是完整版
解压缩,然后添加环境变量到加压目录下的bin文件夹(这里我把下载后的文件名改过了)

-
COLMAP是一款开源的结合SfM(Structure-from-Motion)和MVS(Multi-View Stereo)的三维重建Pipeline
GitHubRelease页下载
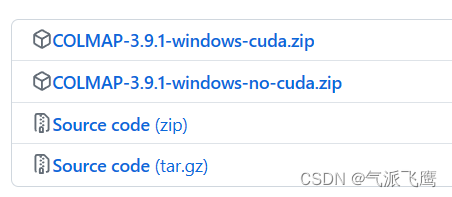
如果电脑已经配置了CUDA可以下载没有CUDA的包,但是我们前面应该是配置了CUDA的环境,这里下载no-cuda版本就可以了。
解压缩,然后添加系统环境变量到加压文件夹路径就可以了

-
ImageMagick 图像批处理的软件
下载地址
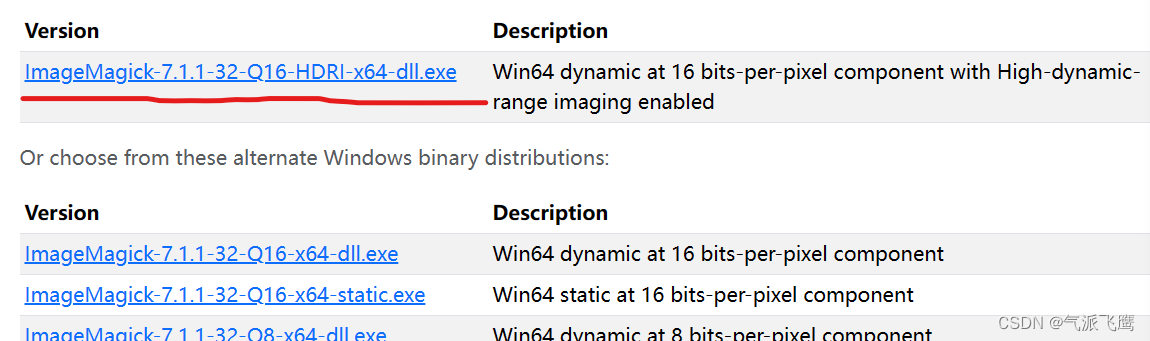
选择一个路径,勾选添加环境变量,无脑安装。
源码下载
可以用git也可以直接下载
git clone git@github.com:graphdeco-inria/gaussian-splatting.git --recursive
or
git clone https://github.com/graphdeco-inria/gaussian-splatting --recursive
Conda环境
打开一个anaconda prompt,cd到gaussian-splatting源码所在路径,例如D:\3DGaussian\gaussian-splatting
一次输入下面命令
SET DISTUTILS_USE_SDK=1 # Windows only
conda env create --file environment.yml
conda activate gaussian_splatting
可能会在第二步出错,官方给出的方案是(注意在源码所在路径下)执行以下代码
conda activate gaussian_splatting
pip install submodules\diff-gaussian-rasterization
pip install submodules\simple-knn
数据集准备
-
用手机相机围绕一个物体拍摄一段视频
-
比如拍摄一个可乐瓶视频,放到<gaussian-splatting source>\data\cola路径下
-
在<gaussian-splatting source>\data\cola下执行
ffmpeg -i {video} -qscale:v 1 -qmin 1 -vf fps={fps} %04d.jpg,其中{video}参数是视频路径,{fps}参数是指每秒的获取的帧数,笔者拍摄了15秒的视频每秒2帧。 -
分割结果应该是若干张图片

-
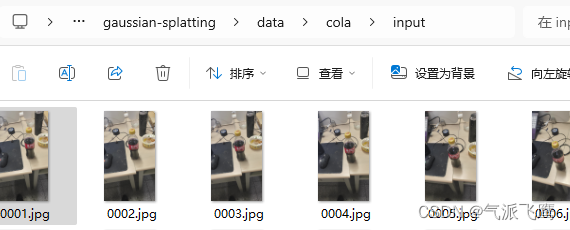
把图片放到<gaussian-splatting source>\data\cola\input下
-
在conda环境gaussian_splatting下,cd到<gaussian-splatting source>目录下执行命令
python convert.py -s <location>
<location>指的是<gaussian-splatting source>\data\cola路径,也就是input的上级目录
执行完成后生成的内容大概是这样
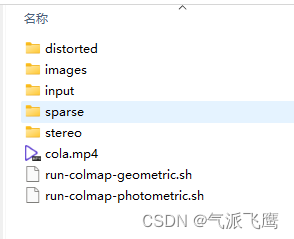
-
然后执行以下命令
python train.py -s <path to COLMAP or NeRF Synthetic dataset>
<path to COLMAP or NeRF Synthetic dataset>是input的上级目录<gaussian-splatting source>\data\cola
开始训练
训练结果在路径<gaussian-splatting source>\output\cola_7000\point_cloud\iteration_7000路径下
用文本编辑器打开能看到各种参数
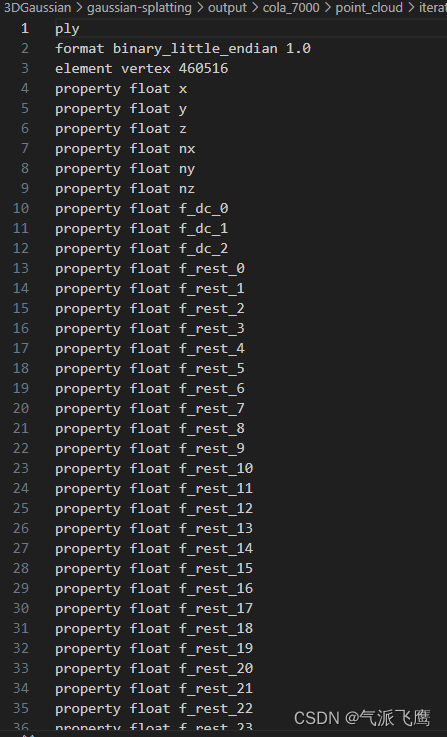
-
渲染结果,命令中的路径为<gaussian-splatting source>\output\cola_7000\,因为我这里只存储了7000次迭代的结果
python render.py -m <path to trained model> # Generate renderings
渲染结果保存在<gaussian-splatting source>\output\cola_7000\train\下面
9. 评估结果,路径与渲染的路径相同
python metrics.py -m <path to trained model> # Compute error metrics on renderings
交互式窗口
windows下的预编译版本链接下载
下载完后是一个压缩包,解压缩即可。
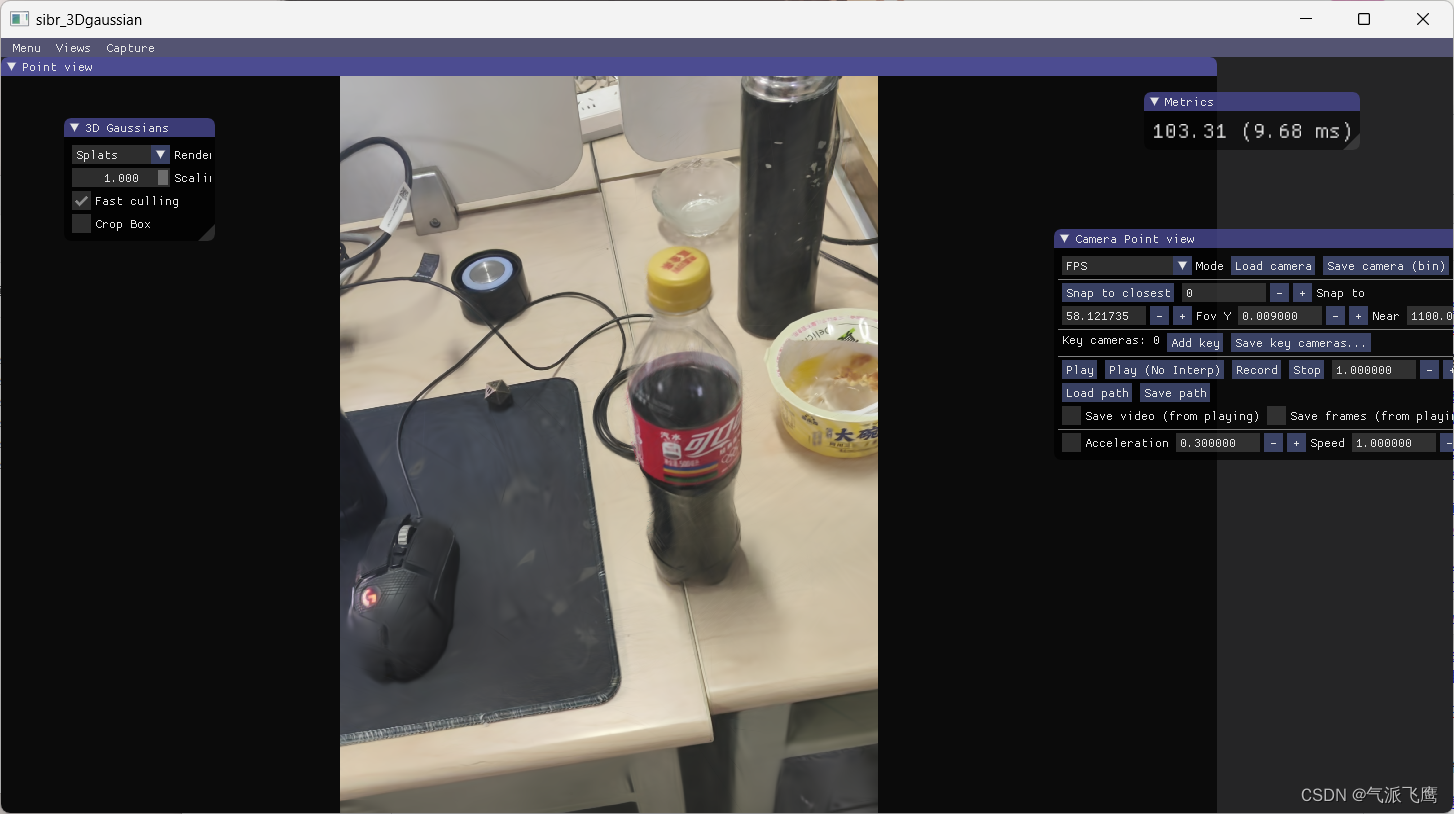
SIBR_remoteGaussian_app.exe 这个程序可以在训练的同时查看训练情况,并且随着迭代更新显示结果,可以双击运行,也可以命令行运行
SIBR_gaussianViewer_app.exe 这个可以用来查看训练的结果
比如我的模型保存在<gaussian-splatting source>\output\cola_7000\point_cloud\iteration_7000路径下
那么我在命令行调用以下命令
SIBR_gaussianViewer_app.exe -m D:\3DGaussian\gaussian-splatting\output\cola_7000
就可以将训练好的模型可视化了。
最后,祝大家科研顺利,有什么问题欢迎讨论,本人能力有限,仍需学习!
这篇关于3d gaussian-splatting源码运行及结果展示的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






