本文主要是介绍动手学深度学习——多层感知机,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 感知机
感知机本质上是一个二分类问题。给定输入x、权重w、偏置b,感知机输出:
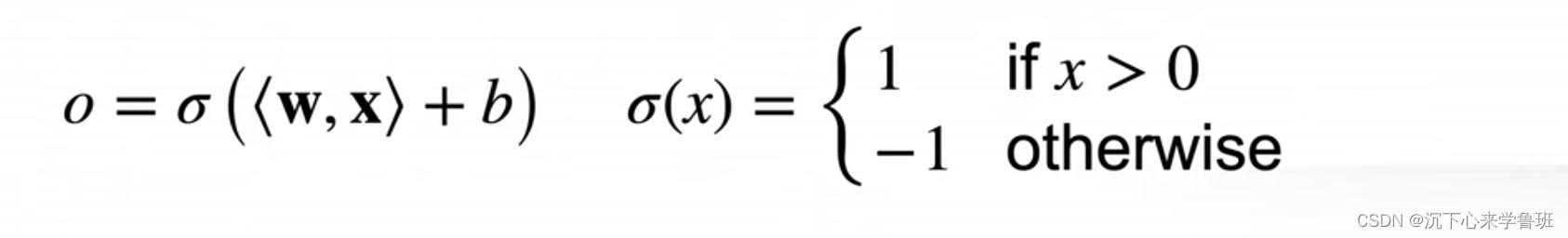
以猫和狗的分类问题为例,它本质上就是找到下面这条黑色的分割线,使得所有的猫和狗都能被正确的分类。

与线性回归和softmax的不同点:
- vs
线性回归:输出的都是一个数,但线性回归输出的是实数,而感知机输出的是离散的分类。 - vs
softmax: softmax是一个多分类(如果有n个分类,softmax就会输出n个元素),而感知机只输出一个元素。
感知机存在的问题: 它只能产生线性分割面,对于XOR(异或)函数,无法拟合(一条线不论怎么分割,都无法将绿色和红色分类正确)。

2. 多层感知机(MLP)
对于上面单层感知机的问题,一个改进思想是:一层函数如果做不了,就用多层函数来做,而多层就带来了网络,用不同层解决不同的问题,多层配合来解决更复杂的问题。

可以使用蓝线对所有数据进行x轴方向的正负分类,再使用黄线对所有数据进行y轴方向的正负分类,最后再将两次分类结果进行xor运算就能得到结果。
多层感知机使用隐藏层和激活函数来得到非线性模型。
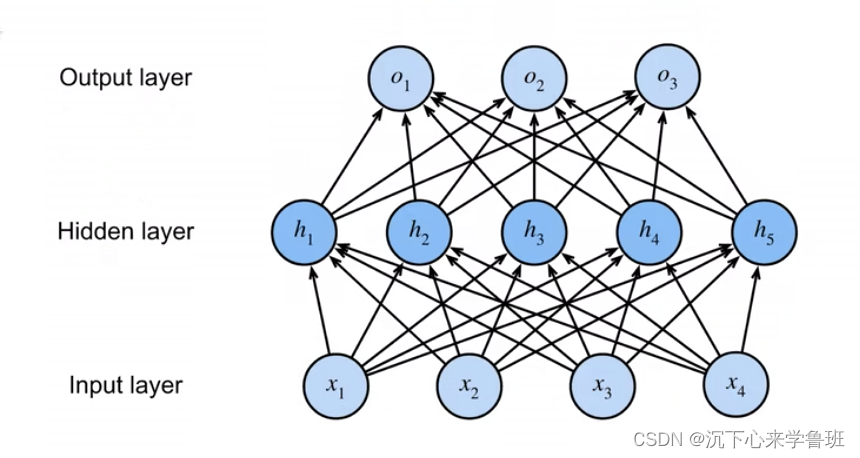
在softmax基础上多了隐藏层。可选超参:
- 隐藏层数
- 每个隐藏层的宽度,通常选择2的若干次冥作为层的宽度
这两个参数的选择取决于输入和输出的复杂度
对复杂的输入,输入维度一般比较高,输出一般会比较少,有两种处理办法:
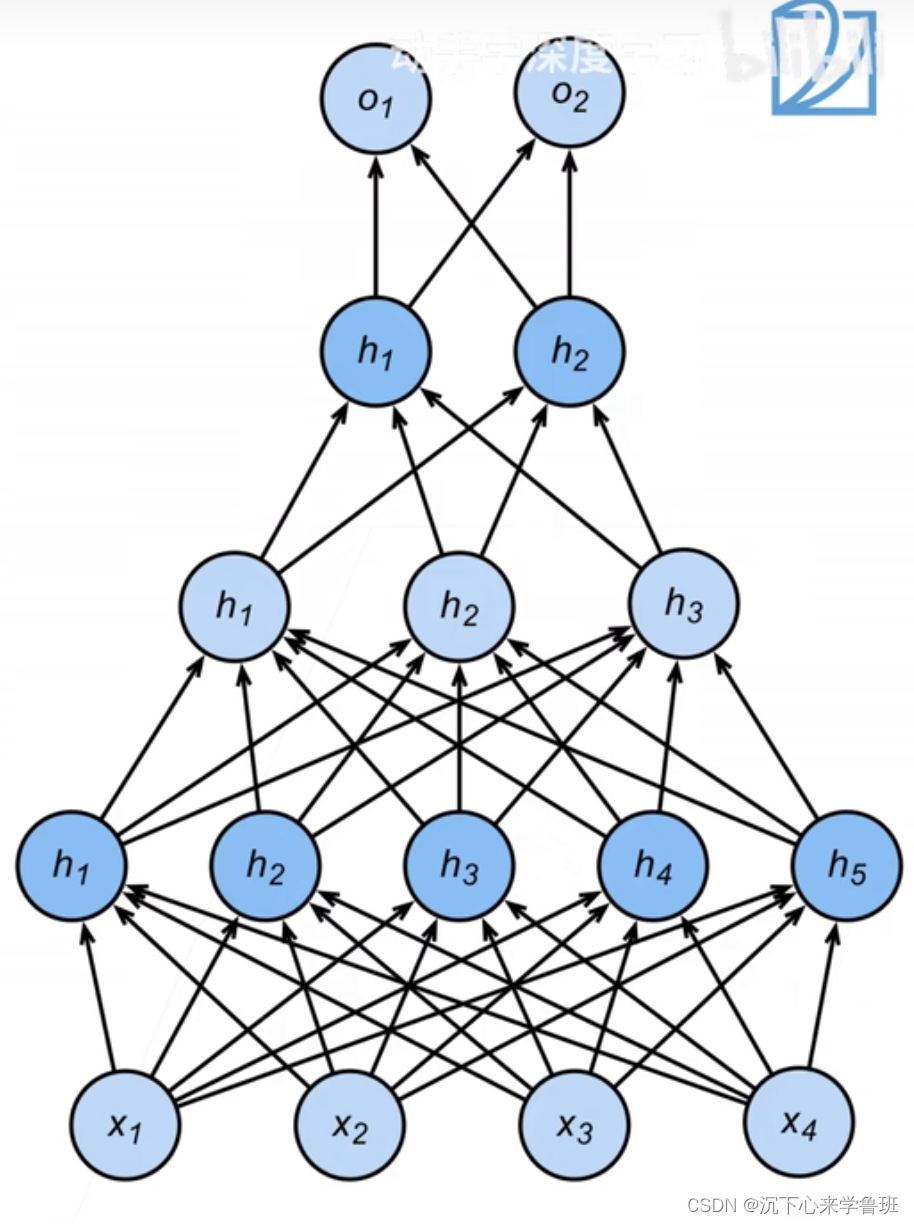
- 做单隐藏层,把模型做平,层的大小设大一点
- 做多隐藏层,把模型做深,层的大小可以设小一点,每层的维度逐步减少(如果每层维度都高,则会导致模型太大)
复杂输入到简单输出本质上是一个信息压缩的过程,多层逐步压缩能避免一次压缩太大导致信息损失太严重,例如:128->64->32->16->8
也可以先expand,从128->256->64->32->16->8
3. 激活函数
作用:在神经网络中引入非线性,可以理解为一个开关,当输入信号超过一定阀值时,神经元会被激活并产生输出,而未超过阀值时神经元将会被抑制。
在没有激活函数的情况下,神经网络只能表示线性映射,无法处理复杂的非线性关系。激活函数的作用就是线性结果映射到一个非线性的输出,以帮助神经网络更好的适应输入数据,提高非线性拟合能力。
举例:一个邮件过滤模型中的神经元,负责对输入邮件的特征(长度、关键词等)进行加权求和,但这个结果只是一个连续的数值我们交
激活函数不能是线性函数,否则会变成单层感知机,依然会存在线性分割面无法处理XOR的问题。
激活函数主要作用于隐藏层。
激活函数的几种选择:
-
sigmoid: 对于任意输入x,都能投影到0~1区间内。
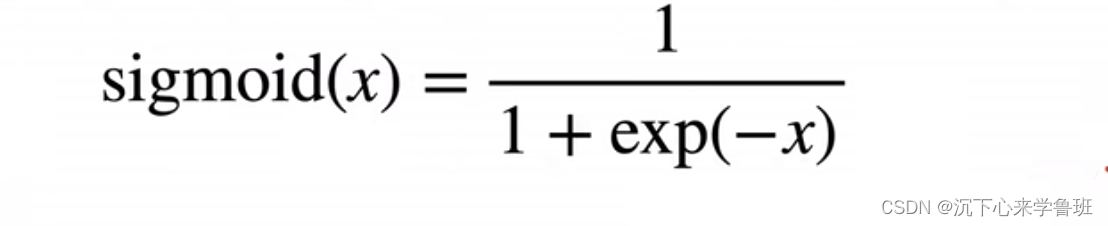
-
tanh(x): 将输入投影到[-1,1]区间内
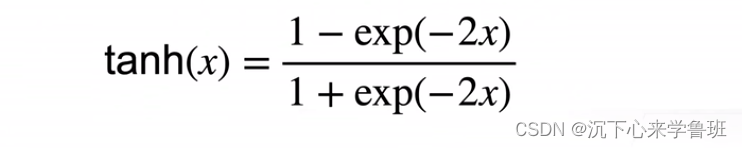
- ReLU: 就是一个Max函数(常用),特点是计算很快,相比前面基于指数运算的sigmoid和tanh函数都快很多(一次指数运算要100个时钟周期)

对ReLU函数求导,小于等于0时都是0,大于0时都是1,最终结果就是一个二分类。
4. 代码实现
4.1 初始化参数
我们将实现一个具有单隐藏层的多层感知机, 这个隐藏层包含128个隐藏单元。
对于每一层我们都要记录一个权重矩阵和一个偏置向量,并指定requires_grad=True来记录参数梯度。
import torch
from torch import nn
from d2l import torch as d2lnum_inputs, num_outputs, num_hiddens = 784, 10, 128W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))params = [W1, b1, W2, b2]
通常,我们选择2的若干次幂作为层的宽度。 因为内存在硬件中的分配和寻址方式,这么做往往可以在计算上更高效。
4.2 加载数据集
这里继续使用Fashion-MNIST图像分类数据集。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
4.3 激活函数
Relu函数的实现比较简单,就是一个max函数的调用, 它将输入的负值部分截断为0,保留正值部分不变。
def relu(X):a = torch.zeros_like(X)return torch.max(X, a)
- torch.zeros_like(X): 创建了一个与X具有相同形状的全零张量a。
- torch.max(X, a): 对于输入X中的每个元素,如果它是正值,则该元素保留不变;如果它是负值,则将其替换为0。
4.4 模型
def net(X):X = X.reshape((-1, num_inputs)) H = relu(X@W1 + b1) # 隐藏层,这里“@”代表矩阵乘法return (H@W2 + b2) # 输出层
- 使用reshape将输入的二维图像转换为一个长度为num_inputs=784的向量;
- 用ReLu函数对隐藏层的线性输出进行激活,得到输出张量H;
- 最后,由张量H和权重矩阵W2进行矩阵乘法操作,将偏置向量b2加到结果上,得到预测输出结果。
4.5 损失函数
这里直接使用pytorch中内置的交叉熵损失函数。
loss = nn.CrossEntropyLoss(reduction='none')
4.6 训练
多层感知机的训练过程与softmax的训练过程完全相同,可以直接调用之前定义过的train_ch3函数。
# 将迭代周期数设置为10,并将学习率设置为0.1.
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
训练过程中的模型损失和精度的收敛变化:
epoch: 1, loss: 1.1021366075515746, test_acc: 0.7544
epoch: 2, loss: 0.6142196039199829, test_acc: 0.8004
epoch: 3, loss: 0.5257990721384684, test_acc: 0.8061
epoch: 4, loss: 0.4842481053034465, test_acc: 0.7988
epoch: 5, loss: 0.4575055497487386, test_acc: 0.8266
epoch: 6, loss: 0.4389862974802653, test_acc: 0.8382
epoch: 7, loss: 0.42252545185089113, test_acc: 0.8443
epoch: 8, loss: 0.40933472124735515, test_acc: 0.8458
epoch: 9, loss: 0.3975078603744507, test_acc: 0.8467
epoch: 10, loss: 0.38488629398345947, test_acc: 0.8527
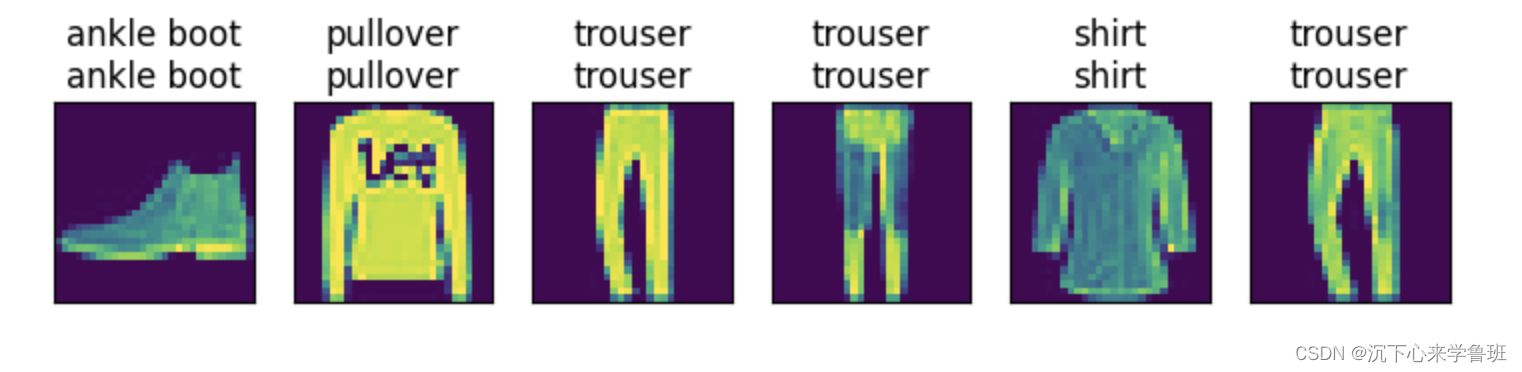
基于之前softmax模型上定义的预测函数,在测试数据集上使用这个模型做验证:
predict_ch3(net, test_iter)
这篇关于动手学深度学习——多层感知机的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



