本文主要是介绍Total Store Orderand(TSO) the x86 MemoryModel,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一种广泛实现的内存一致性模型是总store顺序 (total store order, TSO)。
- TSO 最早由 SPARC 引入,更重要的是,它似乎与广泛使用的 x86 架构的内存一致性模型相匹配。
- RISC-V 还支持 TSO 扩展 RVTSO,部分是为了帮助移植最初为 x86 或 SPARC 架构编写的代码。
为什么需要TSO
处理器核心长期以来一直使用 write buffer (或 store buffer,写入缓冲区) 来保存已提交(retired)的store,直到内存系统的其余部分可以处理这些store。
当store commit时,store进入写入store buffe,当要写入的块处于读写 coherence 状态的高速缓存中时,store退出写入缓冲区。
- Significantly, a store can enter the write buffer before the cache has obtained read-write coherence permissions for the block to be written;
- the write buffer thus hides the latency of servicing a store miss;
对于单核处理器,可以通过确保对地址 A 的load将最近store的值返回给 A,即使对 A 的一个或多个store在write buffer中,也可以使write buffer在架构上不可见。
- This is typically done by either bypassing the value of the most recent store to A to the load from A,其中“最近”由程序顺序确定,或者如果到 A 的store在write buffer中,则停止load A 。
在构建多核处理器时,使用多个核心似乎很自然,每个核心都有自己的旁路写入缓冲区(bypass write buffer),并假设写入缓冲区在架构上仍然是不可见的。
但是,这个假设是错误的! 
考虑如上的代码,假设multicore processor with in-order cores,其中每个核心都有一个单入口写入缓冲区并按以下顺序执行代码;
- 1. 核心 C1 执行store S1,但在其write buffer中缓冲新store的 NEW 值。
- 2. 同样,核心 C2 执行store S2 并将新store的 NEW 值保存在其write buffer中。
- 3. 接下来,两个核心执行各自的load L1 和 L2,并获得旧值 0。
- 4. 最后,两个核心的write buffer使用新store的值 NEW 更新内存。
最终结果是 (r1, r2) = (0, 0)。正如我们在上一章中看到的,这是 SC 禁止的执行结果。
- 没有write buffer,硬件就是 SC,但有了write buffer,它就不是了,这使得write buffer在多核处理器中在架构上是可见的
如何解决这个问题?
- 对可见的写入缓冲区的一种响应是关闭它们,但由于潜在的性能影响,供应商一直不愿这样做。另一种选择是使用激进的、推测性的 SC 实现,使写入缓冲区再次不可见,但这样做会增加复杂性,并且会浪费电力来检测违规和处理错误推测。
- SPARC 和后来的 x86 选择的选项是放弃 SC,转而支持memory consistency model,允许在每个核心上直接使用先进先出 (FIFO) write buffer。这个被称为 TSO 的新模型允许结果“(r1, r2) = (0, 0)”。这个模型让一些人感到惊讶,但事实证明,对于大多数编程习惯来说,它的行为就像 SC 一样,并且在所有情况下都得到了明确的定义。
TSO/X86 的基本思想
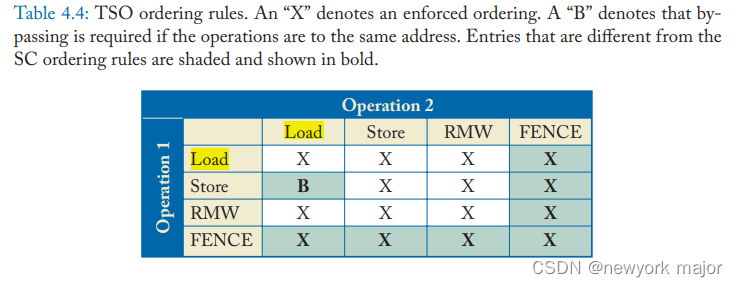
随着执行的进行,SC 要求每个核心为连续操作的所有四种组合保留其load和store的程序顺序:
- * Load -> Load
- * Load -> Store
- * Store -> Store (意味着写入缓冲区必须是 FIFO(而不是,例如,合并)以保持 store-store 顺序。)
- * Store -> Load (Included for SC but omitted for TSO)
TSO 包括前三个约束,但不包括第四个;
同样考虑上面的那个例子:

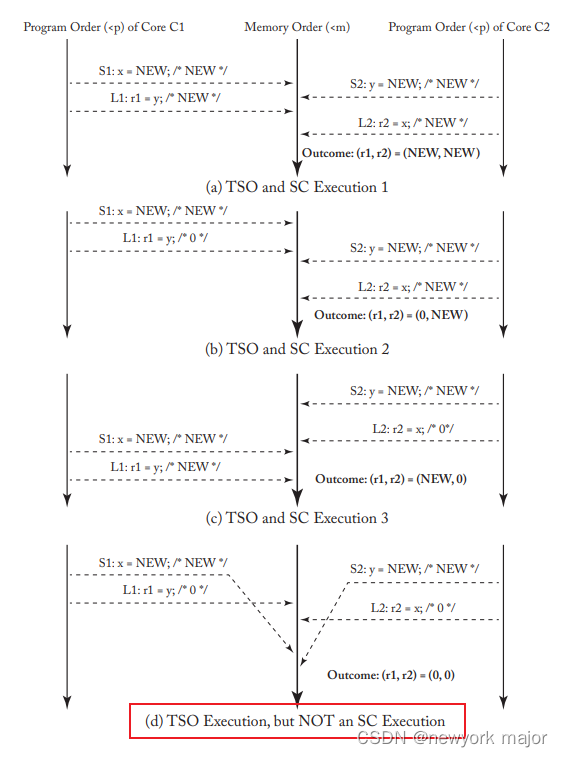
怎么阻止(d)这种场景的发生?
- 插入fence指令;

- 使用 TSO 的程序员很少使用 FENCE(又名内存屏障),因为 TSO 对大多数程序“做正确的事”。
write buffer的bypassing

TSO 确实允许一些非直观的执行结果。表 4.3 是表 4.1 中程序的修改版本,其中:
- 核心 C1 和 C2 分别制作 x 和 y 的本地副本。
- 许多程序员可能假设如果 r2 和 r4 都等于 0,那么 r1 和 r3 也应该为 0,因为store S1 和 S2 必须在load L2 和 L4 之后插入到内存顺序中。
然而,图 4.3 展示了一个执行,显示 r1 和 r3 绕过每个核心写入缓冲区中的值 NEW。
事实上,为了保持single-thread sequential semantics,每个核心都必须按照程序顺序看到自己store的效果,即使store还没有被其他核心观察到。因此,在所有 TSO 执行下,本地副本 r1 和 r3 将始终设置为 NEW 值。
TSO与SC的差异
1. 所有核心都将它们的load和store插入到内存顺序 `<m` 中,考虑到它们的程序顺序,无论它们是相同还是不同的地址(即 a==b 或 a!=b)。有四种情况:
* If `L(a) <p L(b)` => `L(a) <m L(b)` /* Load -> Load */
* If `L(a) <p S(b)` => `L(a) <m S(b)` /* Load -> Store */
* If `S(a) <p S(b)` => `S(a) <m S(b)` /* Store -> Store */
* 删除:If `S(a) <p L(b)` => `S(a) <m L(b)` /* Store -> Load */ => 修改1:Enable FIFO Write Buffer
2. 每个load从它之前的最后一个store中获取它的值到相同的地址:
* 删除:Value of `L(a)` = Value of `MAX <m {S(a) | S(a) <m L(a)}` => 修改2:Need Bypassing
* Value of `L(a)` = Value of `MAX <m {S(a) | S(a) <m L(a) or S(a) <p L(a)}`
最后一个令人费解的等式表明,load的值是最后store到同一地址的值,该地址要么是(a)按内存顺序在它之前,要么(b)按程序顺序在它之前(但可能在它之后)内存顺序,选项(b)优先(即,write buffer绕过覆盖内存系统的其余部分)。
3. 第 (1) 部分必须扩充以定义 FENCE:/* 修改3: FENCEs Order Everything */
* If `L(a) <p FENCE` => `L(a) <m FENCE` /* Load -> FENCE */
* If `S(a) <p FENCE` => `S(a) <m FENCE` /* Store -> FENCE */
* If `FENCE <p FENCE` => `FENCE <m FENCE` /* FENCE -> FENCE */
* If `FENCE <p L(a)` => `FENCE <m L(a)` /* FENCE -> Load */
* If `FENCE <p S(a)` => `FENCE <m S(a)` /* FENCE -> Store */
因为 TSO 已经需要除 Store -> Load 之外的所有顺序,也可以将 TSO FENCE 定义为仅排序:
* If `S(a) <p FENCE` => `S(a) <m FENCE` /* Store -> FENCE */
* If `FENCE <p L(a)` => `FENCE <m L(a)` /* FENCE -> Load */
TSO的实现
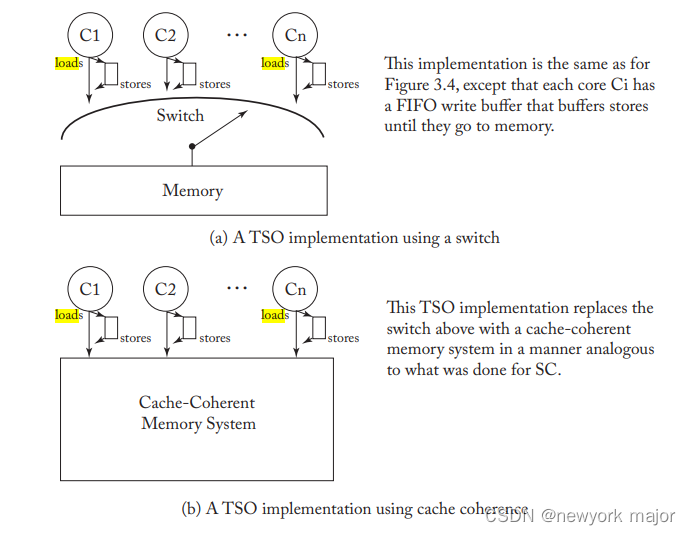
TSO/x86 的实现问题与 SC 类似,只是增加了每个核心中的 FIFO writer buffer。
-
Load 和 store 按照po的顺序,离开该core;
-
Load 要么 bypass write buffer 中的值,要么像以前一样等待切换。
-
如果 buffer 未满,则 store 进入 FIFO write buffer 的尾部;如果 buffer 已满,则 store stall 核心。
-
当 switch 选择核心 Ci 时,它要么执行下一次 load,要么执行 write buffer 头部的 store。
最后,多线程为 TSO 引入了一个微妙的写入缓冲区问题。 TSO write buffer在逻辑上对每个线程上下文(虚拟内核)都是私有的。因此,在多线程内核上,一个线程上下文不应该bypassing另一个线程上下文的write buffer。这种逻辑分离可以通过每个线程上下文的写入缓冲区来实现,或者更常见的是,by using a shared write buffer with entries tagged by thread-context identifiers that permit bypassing only when tags match.

如何定义好的memory consistency model?
一个良好的内存一致性模型应当具备 Sarita Adve 提出的三个P,以及我们的第四个P:
- *可编程性*:一个良好的模型应该使编写多线程程序变得(相对)容易。这个模型应该对大多数用户来说是直观的,即使是那些没有阅读详细细节的用户也是如此。它应该是精确的,以便专家可以拓展所允许的范围。
- *性能*:一个良好的模型应该在合理的功耗、成本等条件下促进高性能的实现。它应该给予实现者广泛的选项余地。
- *可移植性*:一个良好的模型应该被广泛采用,或者至少提供向后兼容性或在不同模型之间进行转换的能力。
- *精确性*:一个良好的模型应该被精确定义,通常通过数学方式。自然语言过于模糊不清,不能让专家拓展所允许的范围。
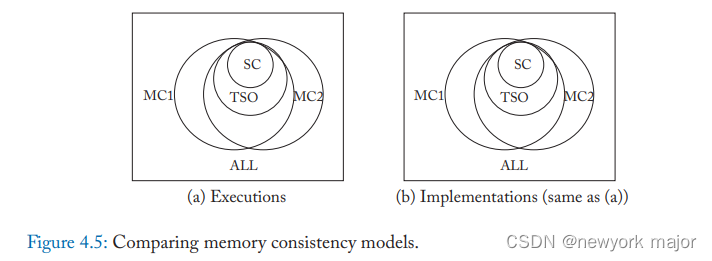
SC和TSO模型的优劣如何?
运用这四个P来分析:
- *可编程性*:SC 模型是最直观的。TSO 模型也接近,因为对于常见的编程惯例,它的行为类似于 SC 模型。然而,隐含的非 SC 执行可能会对程序员和工具作者产生影响。
- *性能*:对于简单的核心,TSO 模型可以比 SC 模型提供更好的性能,但通过推测可以减小二者之间的差距。
- *可移植性*:SC 模型被广泛理解,而 TSO 模型得到了广泛采用。
- *精确性*:SC 模型和 TSO 模型都有明确的形式定义。
总的来说,SC 模型和 TSO 模型非常接近,尤其是与下一章讨论的更复杂和更宽松的 memory consistency 模型相比较。
这篇关于Total Store Orderand(TSO) the x86 MemoryModel的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!