本文主要是介绍跨平台图表控件TeeChart如何从DAT或TEXT文件中导入数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大多数开发人员在使用TeeChart进行开发的时候,都需要访问包含在文本文档中的一些数据,本次教程将详细讲解如何去实现这一步骤。
文本文件通常包含使用空格键或者是TAB键分隔开的数字和文字:
TeeChart官方最新版免费下载地址
比如下面的文本,包含两个字段,使用空格作为字段分隔:
0.1 24
0.5 143
0.2 321
0.1 100
从一个文本文件读取数据(如果列分隔符是正确的),开发者可以使用TSeriesTextSource组件,可以根据自身的数据设置ileName、Fields和FieldSeparator属性。然后只需通过设置TSeriesTextSource.Series或Series.DataSource属性将系列文本源组件连接到一个图表系列。
1 创建一个新的应用程序。 (File->New->Application)
2 从"Additional"面板选项卡中拖放TChart组件。
3 双击Chart1组件显示TeeChart编辑对话框。(或右键单击Chart1并单击"Edit...")
4 单击"Add..." 按钮,选择"Line"系列风格,单击OK按钮。(或双击"Line"图表)
5 关闭编辑器对话框(或按Esc键关闭它)。
6 找到“TeeChart”组件面板选项卡并拖放SeriesTextSource组件。
7 双击SeriesTextSource1组件显示编辑器对话框,填写以下属性:
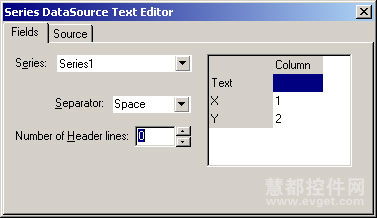
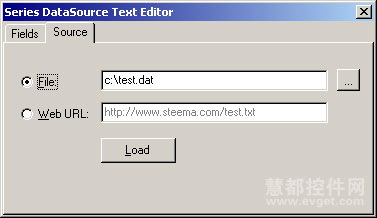
VCL代码:
unit UImportData;interfaceusesWindows, Messages, SysUtils, Classes, Graphics, Controls, Forms,Dialogs, TeEngine, Series, TeeURL, TeeSeriesTextEd, ExtCtrls, TeeProcs, Chart, StdCtrls, Buttons;typeTForm1 = class(TForm)Chart1: TChart;Series1: TLineSeries;SeriesTextSource1: TSeriesTextSource;Panel1: TPanel;BitBtn1: TBitBtn;procedure BitBtn1Click(Sender: TObject);private{ Private declarations }public{ Public declarations }end;varForm1: TForm1;implementation{$R *.dfm}procedure TForm1.BitBtn1Click(Sender: TObject);beginwith SeriesTextSource1 dobegin// Setup fields (columns in text file)Fields.Clear;AddField('X',1);AddField('Y',2);// Set separatorsFieldSeparator := ' ';DecimalSeparator := '.';// Set file name containing text dataFileName := 'test.dat';// Series to add dataSeries := Series1;// Load data from file into SeriesActive := True;end;// Example of setting axes scales.// Not necessary is axes already have Automatic:=True.Series1.GetVertAxis.SetMinMax(0,1);Series1.GetHorizAxis.SetMinMax(3864.90,3865.50);end;end.
Displaying the SeriesTextSource editor dialogIf you wish to show the SeriesTextSource editor dialog at runtime, simply drop a button and type this code at Button1Click event:procedure TForm1.Button1Click(Sender: TObject);begin// This procedure is located at TeeSeriesTextEd.pas unit:TeeEditSeriesTextSource(SeriesTextSource1); end;
这篇关于跨平台图表控件TeeChart如何从DAT或TEXT文件中导入数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




