本文主要是介绍【机器学习300问】79、Mini-Batch梯度下降法的原理是什么?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Mini-Batch梯度下降法是一种将训练数据集分成小批次进行学习的优化方法,通过这种方式,可以有效地解决内存限制问题并加速学习过程。
一、为什么要使用Mini-Batch?
在机器学习尤其是深度学习中,我们常常面临海量数据处理的问题。如果我们一次性将所有的数据加载进内存做训练,很可能会遇到内存不足的情况。此外,处理如此大批量的数据也会导致训练速度变慢。为了解决这个问题,Mini-Batch技术应运而生。
二、什么是批量梯度下降?
让我们理解一下批量梯度下降(Batch Gradient Descent, BGD)的概念。这种方法在每次迭代时使用全部样本来进行梯度的更新。这样做的优点是可以确保梯度估计的无偏性,并且当目标函数为凸函数时,可以保证收敛到全局最小值。然而,当数据集非常大时,遍历所有样本需要大量的时间,这就是BGD的主要缺点。
为了解决大数据集带来的问题,Mini-Batch梯度下降(Mini-Batch Gradient Descent, MBGD)就应运而生了。它是BGD的一种改良方法,通过将整个数据集分成若干个小批次,每次只使用一个小批次的数据来更新梯度。这样既保留了BGD的一些优点,比如更准确地朝向极值所在的方向,又显著减少了每次迭代所需的计算量。
三、Mini-Batch举例说明
假设我们有一个包含1000个样本的训练集,我们可以选择每个批次包含64个样本,那么我们将有16个这样的批次(因为1000除以64得到15余数为40,所以还有一个批次包含剩余的40个样本)。然后我们会对这16个批次分别执行一步梯度下降法,更新我们的模型参数。
四、Mini-Batch的大小设置
(1)大小设置的三种情况
| 随机梯度下降(SGD) | Mini-Batch梯度下降(MBGD) | 批量梯度下降(BGD) |
| Mini-Batch Size = 1 | Mini-Batch Size = k | Mini-Batch Size = m |
| 失去向量化的加速训练效果。 | 使用向量化技术加速训练; 无须等待所有数据被处理即可进行后续工作。 | 耗时长、迭代次数多。 |
如果Mini-Batch的大小设置为1,那么Mini-Batch梯度下降实际上就变成了随机梯度下降(Stochastic Gradient Descent,SGD)。在SGD中,每次迭代只使用一个样本来计算梯度并更新模型参数。由于只用到了一个样本,所以SGD的计算速度非常快,并且可以支持在线学习,即模型可以在新数据到来时实时更新。然而,SGD的缺点在于因为每个样本都会产生一个梯度估计,这些估计值可能会有很大的变异性,导致优化过程出现很多震荡,收敛路径不够平滑。
如果Mini-Batch的大小设置为训练集的大小m,那么Mini-Batch梯度下降实际上就变成了批量梯度下降(Batch Gradient Descent,BGD)。在BGD中,每次迭代使用整个训练集来计算梯度并更新模型参数。由于使用了全部的训练样本,所以BGD可以得到最准确的梯度估计,从而使得优化过程更加稳定。然而,BGD的缺点在于计算速度非常慢,因为需要遍历整个训练集。此外,当数据集非常大时,可能会导致内存不足的问题。
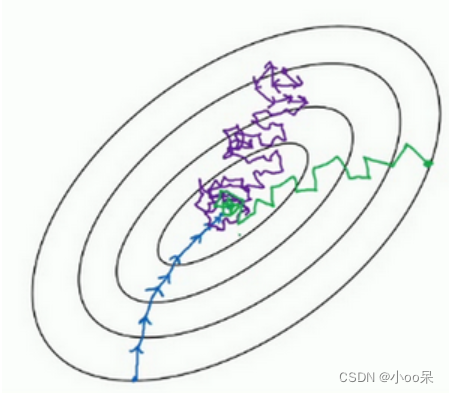
上图是梯度下降空间。 蓝色的部分是BGD、紫色部分是SGD、绿色部分是Mini-Batch。 Mini-Batch不是每次迭代损失函数都会减少,所以看上去好像走了很多弯路。 不过整体还是朝着最优解迭代的。 而且由于Mini-Batch一个epoch就走了步,而BGD一个epoch只有一步。所以虽然Mini-Batch走了弯路但还是会快很多。
(2)训练速度与稳定性的权衡
mini-Batch的大小是权衡速度与稳定性的一种方式。所以Batch Size是一个超参数。
- 当大小为1时,我们获得了最快的训练速度,但可能牺牲了一定的稳定性。而当我们增加mini-Batch的大小时,虽然单次迭代所需的时间会增加,但梯度估计会变得更加稳定,从而使得整个优化过程更加平滑。
- 当大小为m时,我们获得了最快的训练速度和最稳定的优化过程,但可能会面临内存不足的问题。而当我们减小mini-Batch的大小时,虽然单次迭代所需的时间会增加,但可以解决内存不足的问题,并且梯度估计也会变得更加稳定,从而使得整个优化过程更加平滑。
(3)常见的Batch Size选择
Batch Size超参数其选择大多取决于具体的计算资源、数据集大小、模型复杂度和训练目标。他并不是一个固定的数字,而是需要根据具体情况来调整。以下是一些选择Batch Size时需要考虑的因素:
- 一般设置:2的n次方。 例如64,128,512,1024. 一般不会超过这个范围。不能太大,因为太大了会无限接近BGD的行为,速度会慢。 也不能太小,太小了以后可能算法永远不会收敛。
- 计算资源:较大的Batch Size需要更多的内存和计算资源。如果计算资源有限,可以选择较小的Batch Size,例如32或64。
- 数据集大小:对于较小的数据集,选择较小的Batch Size通常更合适,以避免模型过度拟合训练数据。
- 模型复杂度:简单模型可以使用较大的Batch Size,因为计算量相对较小。复杂模型则建议使用较小的Batch Size,以充分训练模型。
- 训练目标:如果追求最大化训练速度,可以选择较大的Batch Size。若目标是获得更好的模型性能,则建议使用较小的Batch Size。
这篇关于【机器学习300问】79、Mini-Batch梯度下降法的原理是什么?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




