本文主要是介绍Paddle 基于ANN(全连接神经网络)的GAN(生成对抗网络)实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是GAN
GAN是生成对抗网络,将会根据一个随机向量,实现数据的生成(如生成手写数字、生成文本等)。
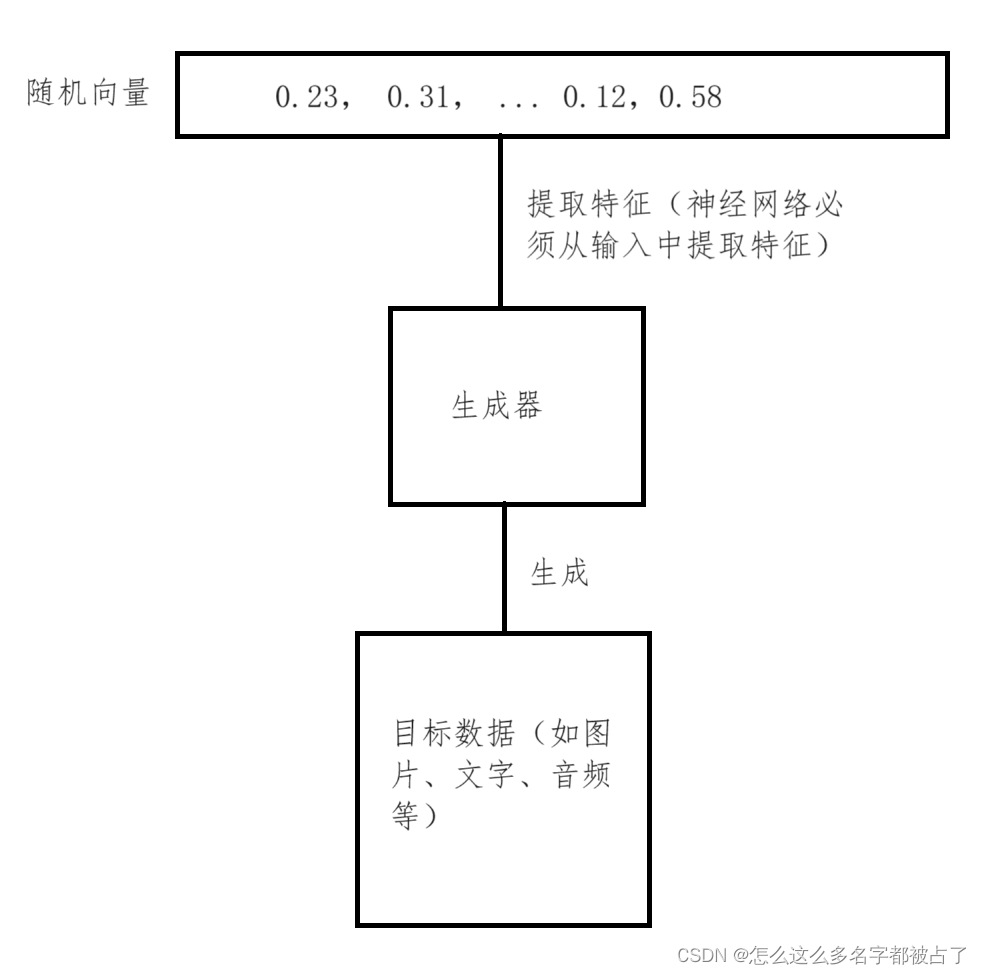
GAN的训练过程中,需要有一个生成器G和一个鉴别器D.
生成器用于生成数据,鉴定器用于鉴定数据的准确性,其实就是在鉴别数据是人生成的还是机器生成的,因为生成器需要以假乱真。
鉴别器将会与生成器一起训练。鉴别器将会先训练,这样才有适当的能力去鉴定生成器生成数据的准确性。
鉴别器的训练过程中,需要先给它准确的数据,和通过随机向量传入生成器产生的数据(一律视为负样本),并通过损失函数对其进行训练;生成器训练过程中,会先给它一个随机向量进行前向传播,然后让鉴别器判断其正确性,并通过损失函数(不正确的数据意味着有损失)进行训练:

生成器训练过程中,需要先通过随机向量获取其结果,然后让鉴别器进行鉴别,在通过鉴别器的鉴别结果计算损失(如果鉴别器认为这是生成器生成的,则产生损失),最后更新梯度和参数:

训练过程直到生成器拟合训练集(收敛),判别器的输出总是0.5(均方误差损失函数应为0.25)为止.
形象的GAN的例子
想象一场由一位“名画伪造者”和一位“艺术鉴定家”参与的猫捉老鼠游戏。
在这个场景中,名画伪造者(即GAN中的生成器)的目标是创造出一幅足以欺骗艺术鉴定家(即GAN中的判别器)的假画。开始时,伪造者的技艺并不精湛,他制作的假画充满了破绽,很容易被鉴定家一眼识破。
然而,随着伪造者不断尝试和失败,他逐渐从每一次的失败中学习,逐渐提升了自己的技艺。他开始注意到真画的每一个细节,从笔触、色彩到构图,都尽量模仿得惟妙惟肖。每一次的失败都让他更接近成功,他制作的假画也越来越难以辨别真伪。
而艺术鉴定家也不甘示弱。他开始时能够轻易地识别出伪造者的假画,但随着伪造者技艺的提升,他也需要不断提升自己的鉴定能力。他开始深入研究真画的每一个特点,以便更准确地识别出伪造者的假画。
这个过程就像GAN中的训练过程一样。生成器不断尝试生成新的数据(在这里是假画),而判别器则不断尝试区分这些数据是真实的还是生成的。两者在相互竞争的过程中不断提升自己的能力,最终达到了一个平衡状态。
在这个例子中,名画伪造者就是GAN中的生成器,他负责生成新的数据;而艺术鉴定家则是GAN中的判别器,他负责区分数据的真伪。两者在相互竞争的过程中共同进步,使得生成的数据越来越接近真实的数据。
代码实现
本文将以基于MNIST(手写数据集)为数据集,实现一个生成手写数字的GAN模型:
首先创建models.py,用于定义判别器和生成器:
import paddle# Generator Code
class Generator(paddle.nn.Layer):def __init__(self, ):super(Generator, self).__init__()self.gen = paddle.nn.Sequential(paddle.nn.Linear(in_features=100, out_features=256),paddle.nn.ReLU(True),paddle.nn.Linear(in_features=256, out_features=512),paddle.nn.ReLU(True),paddle.nn.Linear(in_features=512, out_features=1024),paddle.nn.Tanh(),)def forward(self, x):x = self.gen(x)out = paddle.reshape(x,[-1,1,32,32])return out# Discriminator Code
class Discriminator(paddle.nn.Layer):def __init__(self, ):super(Discriminator, self).__init__()self.dis = paddle.nn.Sequential(paddle.nn.Linear(in_features=1024, out_features=512),paddle.nn.LeakyReLU(0.2),paddle.nn.Linear(in_features=512, out_features=256),paddle.nn.LeakyReLU(0.2),paddle.nn.Linear(in_features=256, out_features=1),paddle.nn.Sigmoid())def forward(self, x):x = paddle.reshape(x, [-1, 1024])out = self.dis(x)return out
其中,生成器将接收一个长度为100的张量(随机向量),输出一个长度为1024的张量(生成的图片);鉴别器将接收一个长度为1024的张量(图片) ,输出长度为1的张量(鉴别结果)
然后创建main.py,用于训练:
import paddle
import matplotlib.pyplot as plt
from models import Generator, Discriminator
import numpy as npdataset = paddle.vision.datasets.MNIST(mode='train',transform=paddle.vision.transforms.Compose([paddle.vision.transforms.Resize((32, 32)),paddle.vision.transforms.Normalize([0], [255])]))dataloader = paddle.io.DataLoader(dataset, batch_size=32, shuffle=True)netG = Generator()
netD = Discriminator()if 1:try:mydict = paddle.load('generator.params')netG.set_dict(mydict)mydict = paddle.load('discriminator.params')netD.set_dict(mydict)except:print('fail to load model')optimizerD = paddle.optimizer.Adam(parameters=netD.parameters(), learning_rate=0.0002, beta1=0.5, beta2=0.999)
optimizerG = paddle.optimizer.Adam(parameters=netG.parameters(), learning_rate=0.0002, beta1=0.5, beta2=0.999)# 最大迭代epoch
max_epoch = 10for epoch in range(max_epoch):now_step = 0for step, (data, label) in enumerate(dataloader):############################# (1) 更新鉴别器############################ 清除D的梯度optimizerD.clear_grad()# 传入正样本,并更新梯度pos_img = datalabel = paddle.full([pos_img.shape[0], 1], 1, dtype='float32')pre = netD(pos_img)loss_D_1 = paddle.nn.functional.mse_loss(pre, label)loss_D_1.backward()# 通过randn构造随机数,制造负样本,并传入D,更新梯度noise = paddle.randn([pos_img.shape[0], 100], 'float32')neg_img = netG(noise)label = paddle.full([pos_img.shape[0], 1], 0, dtype='float32')pre = netD(neg_img.detach()) # 通过detach阻断网络梯度传播,不影响G的梯度计算loss_D_2 = paddle.nn.functional.mse_loss(pre, label)loss_D_2.backward()# 更新D网络参数optimizerD.step()optimizerD.clear_grad()loss_D = loss_D_1 + loss_D_2############################# (2) 更新生成器############################ 清除D的梯度optimizerG.clear_grad()noise = paddle.randn([pos_img.shape[0], 100], 'float32')fake = netG(noise)label = paddle.full((pos_img.shape[0], 1), 1, dtype=np.float32, )output = netD(fake)# 这个写法没有问题,因为这个mse_loss既会影响到netG(output=netD(netG(noise)))的梯度,也会影响到netD的梯度,但是之后的代码并没有更新netD的参数,而循环开头就清除了netD的梯度loss_G = paddle.nn.functional.mse_loss(output, label)loss_G.backward()# 更新G网络参数optimizerG.step()optimizerG.clear_grad()now_step += 1############################ 输出日志###########################if now_step % 100 == 0:print(f'Epoch ID={epoch} Batch ID={now_step} \n\n D-Loss={float(loss_D)} G-Loss={float(loss_G)}')paddle.save(netG.state_dict(), "generator.params")
paddle.save(netD.state_dict(), "discriminator.params")
如果是第一次训练或不使用原有训练参数,可以将if 1改成if 0.
接下来创建use.py,用于生成图片:
import paddle
from models import Generator
import matplotlib.pyplot as pltimport paddle
from models import Generator
import matplotlib.pyplot as plt
import numpy as np# 加载模型
netG = Generator()
mydict = paddle.load('generator.params')
netG.set_dict(mydict)# 设置matplotlib的显示环境
fig, axs = plt.subplots(nrows=2, ncols=5, figsize=(15, 6)) # 创建一个2x5的子图网格# 生成10个噪声向量
for i, ax in enumerate(axs.flatten()):noise = paddle.randn([1, 100], 'float32')img = netG(noise)img = img.numpy()[0][0] # img.numpy():张量转np数组img[img < 0] = 0 # 将img中所有小于0的元素赋值为0img = np.clip(img, 0, 1) # 将img中所有小于0的元素设为0,大于1的设为1(如果需要)# 显示图片ax.imshow(img)ax.axis('off') # 不显示坐标轴# 显示图像
plt.show()
进行多轮训练后,生成结果:

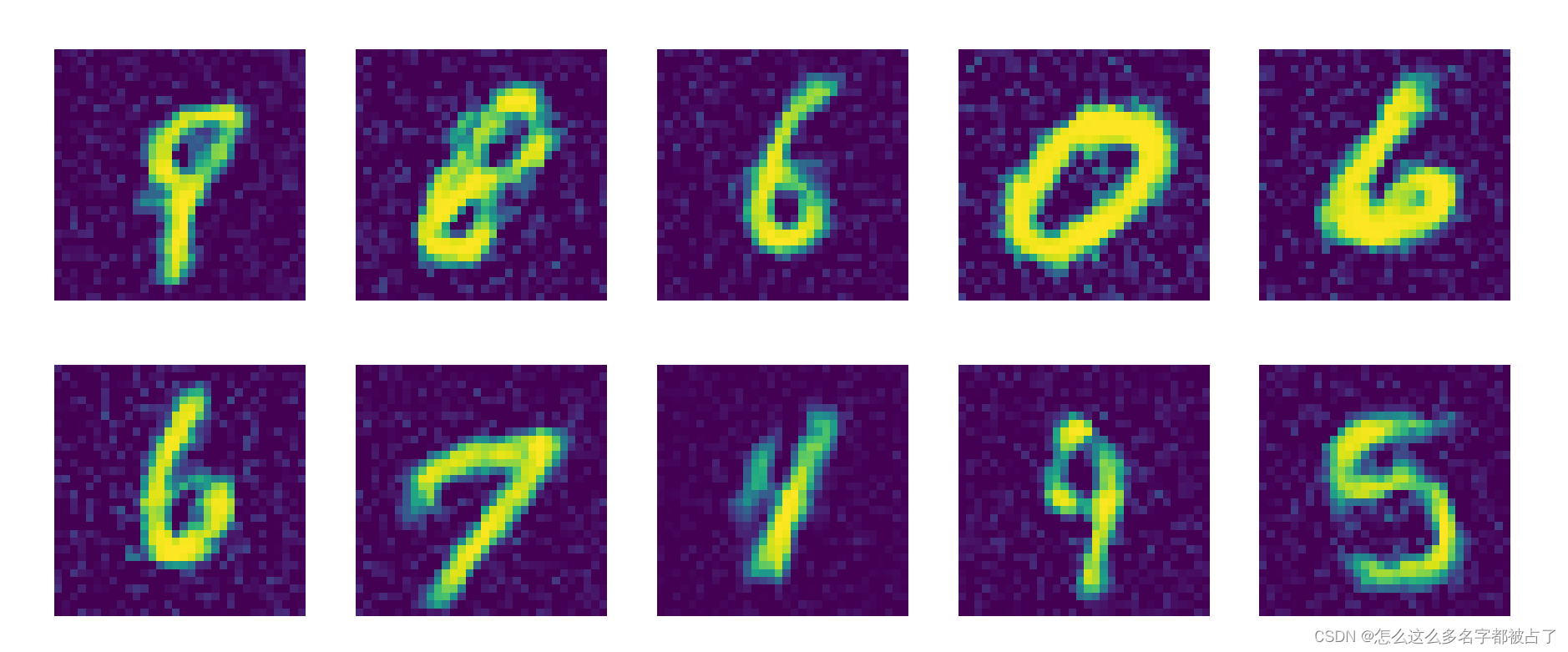
可以看到,它很好的生成了我们想要的图片。
GANs
但是,我们这个模型只能随机产生数字,还不能生成指定的数字(如让机器生成一个1).为了解决这个问题,我们可以针对每一个数字生成一个对应的GAN,所有这样的GAN组合起来,就是GANs. 这里不展开讲解。
参考
MNIST数据集下用Paddle框架的动态图模式玩耍经典对抗生成网络(GAN)-使用文档-PaddlePaddle深度学习平台
【飞桨PaddlePaddle】四天搞懂生成对抗网络(一)——通俗理解经典GAN_四天搞懂生成对抗网络(一)-CSDN博客
这篇关于Paddle 基于ANN(全连接神经网络)的GAN(生成对抗网络)实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





