本文主要是介绍使用C++ __builtin_expect优化程序性能后,程序体积不改变原因,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
结论
使用__builtin_expect优化程序性能,开启-O3的情况下,确实程序的体积可能不改变,但是还是会产生优化效果。
测试代码
不使用__builtin_expect
#include <iostream>void fun(int a, int b) {// 不使用__builtin_expectif (a < b) {std::cout << "a < b" << std::endl;} else {std::cout << "a >= b" << std::endl;}
}int main() {return 0;
}使用__builtin_expect
#include <iostream>void fun(int a, int b) {// 使用__builtin_expectif (__builtin_expect(a < b, 1)) {std::cout << "a < b" << std::endl;} else {std::cout << "a >= b" << std::endl;}
}int main() {return 0;
}在Compiler Explorer 选择ARM64 gcc9.5 -O3优化
汇编指令对比
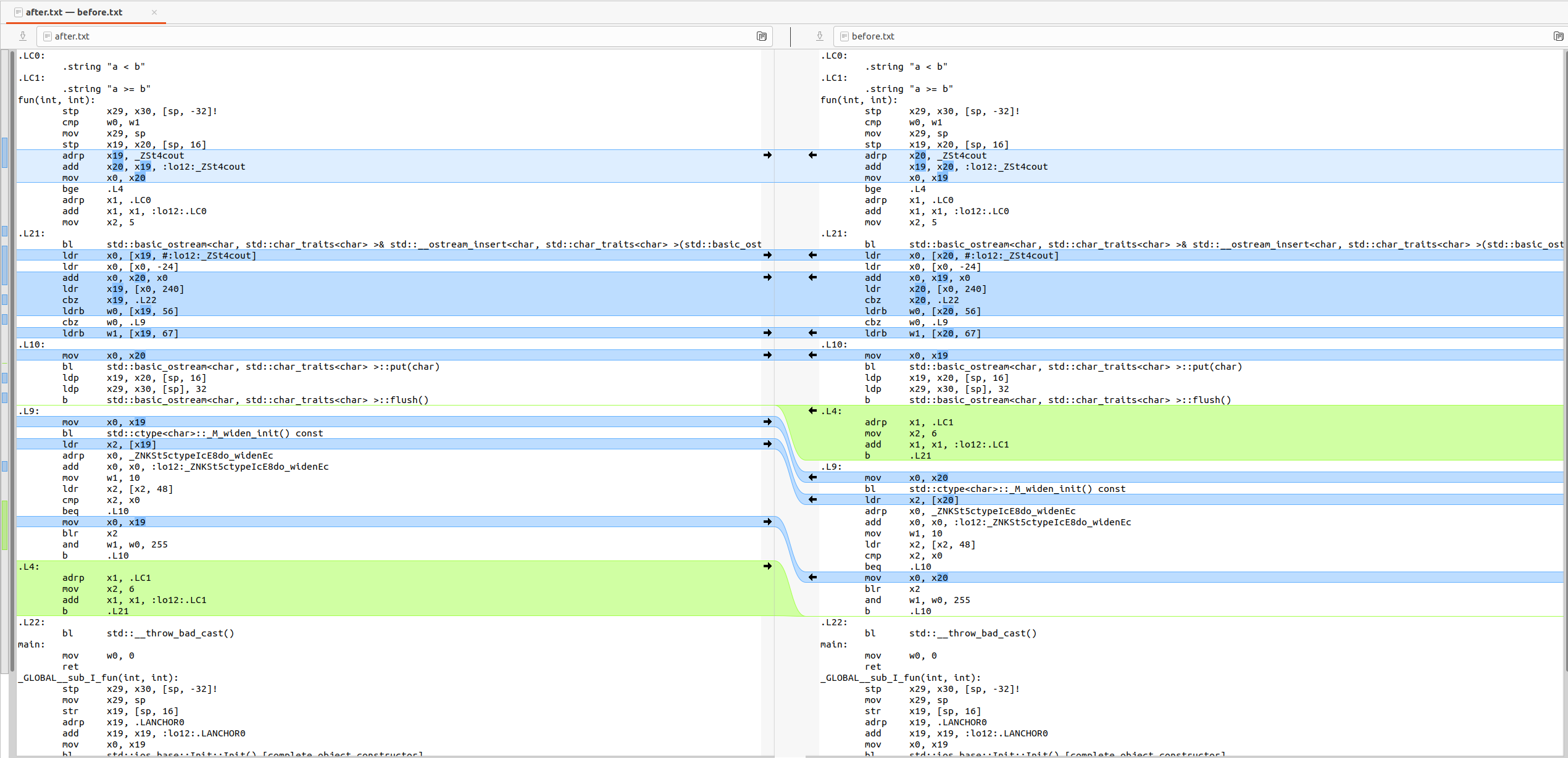
上图中主要汇编指令的顺序不一致
在ubuntu 20.04下使用 g++ -O3测试
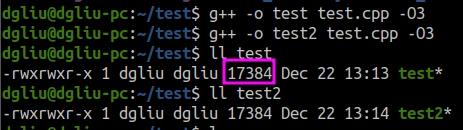
发现使用使用__builtin_expect前后程序的大小是完全一样的。
这篇关于使用C++ __builtin_expect优化程序性能后,程序体积不改变原因的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






