本文主要是介绍基因表达微阵列数据分类的多目标启发式算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
#引用
##LaTex
@article{LV201613,
title = “A multi-objective heuristic algorithm for gene expression microarray data classification”,
journal = “Expert Systems with Applications”,
volume = “59”,
pages = “13 - 19”,
year = “2016”,
issn = “0957-4174”,
doi = “https://doi.org/10.1016/j.eswa.2016.04.020”,
url = “http://www.sciencedirect.com/science/article/pii/S0957417416301865”,
author = “Jia Lv and Qinke Peng and Xiao Chen and Zhi Sun”,
keywords = “Microarray, Gene selection, Small number of selected genes, Multi-objective, Heuristic algorithm”
}
##Normal
Jia Lv, Qinke Peng, Xiao Chen, Zhi Sun,
A multi-objective heuristic algorithm for gene expression microarray data classification,
Expert Systems with Applications,
Volume 59,
2016,
Pages 13-19,
ISSN 0957-4174,
https://doi.org/10.1016/j.eswa.2016.04.020.
(http://www.sciencedirect.com/science/article/pii/S0957417416301865)
Keywords: Microarray; Gene selection; Small number of selected genes; Multi-objective; Heuristic algorithm
#摘要
Microarray data 微阵列数据
analytic hierarchy process (AHP)
Univariate Marginal Distribution Algorithm
the fewer the selected genes are, the less cost the disease prognosis expert system is.
#主要内容
##1 特征预选择
a filter-based gene ranking algorithm — mRMR:
特征与类之间的相关性(max-relevance 最大相关)
特征之间的冗余度(min-redundancy 最小冗余)

单个特征的性能
为防止丢失在组中表现好的特征,选300个特征
##2 多目标模型
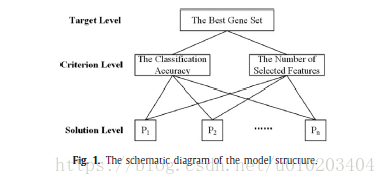
##3 MOEDA
多目标the estimation of distribution algorithm (EDA) — MOEDA
elite individuals ( EIs )
regenerated individuals ( RIs )
probabilistic model:
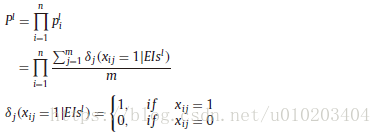
classification accuracy (ACC)
the number of selected features (NSF)
Higher and fewer rule. (HFR)
ACC绝对比NSF重要
- 根据ACC对个体排序
- 对于相同ACC,根据NSF排序
Forcibly decrease rule. (FDR)
随着演化的进行,计算NSF的上限 — U L l UL^l ULl(逐渐降低)
N L l = q 2 ⌊ l w ⌋ NL^l = \frac{q}{2^{\left\lfloor\frac{l}{w}\right\rfloor}} NLl=2⌊wl⌋q
l l l — 代数
q q q — 预选择的特征数目
w w w — 常数
每个特征对应一个选择概率
mutation rules — 防止落入局部最优
the elite reserved strategy — 防止最优个体丢失
SVM + the radial basis function (RBF)
SVM-RBF
参数: c c c与 γ \gamma γ
同时优化参数与特征
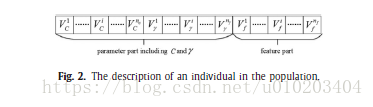
参数计算
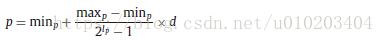
p ∈ { c , γ } p \in \left\{ c, \gamma \right\} p∈{c,γ}
max p \max_p maxp — 参数最大值
min p \min_p minp — 参数最小值
d d d — 二进制字符串的十进制值
l p l_p lp — 二进制字符串的长度
l c = l γ = 25 l_c = l_\gamma = 25 lc=lγ=25
max c = 256 \max_c = 256 maxc=256
max γ = 16 \max_\gamma = 16 maxγ=16
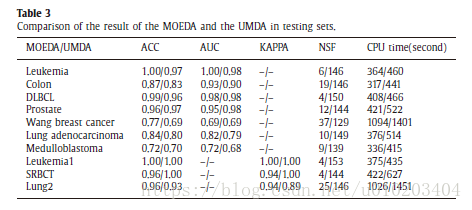
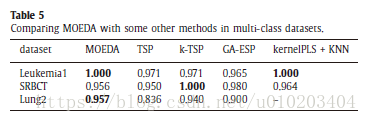
#4 试验
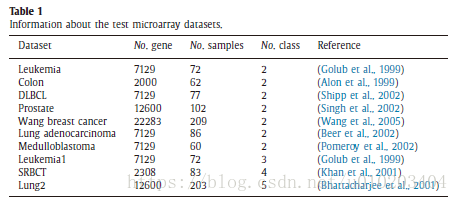
10-fold cross validation
‘the N best features are always not the best N features’.
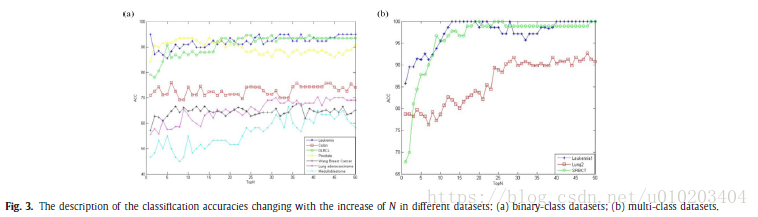
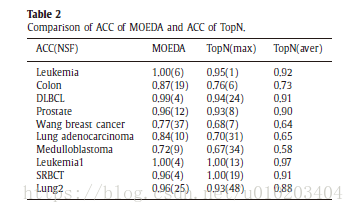
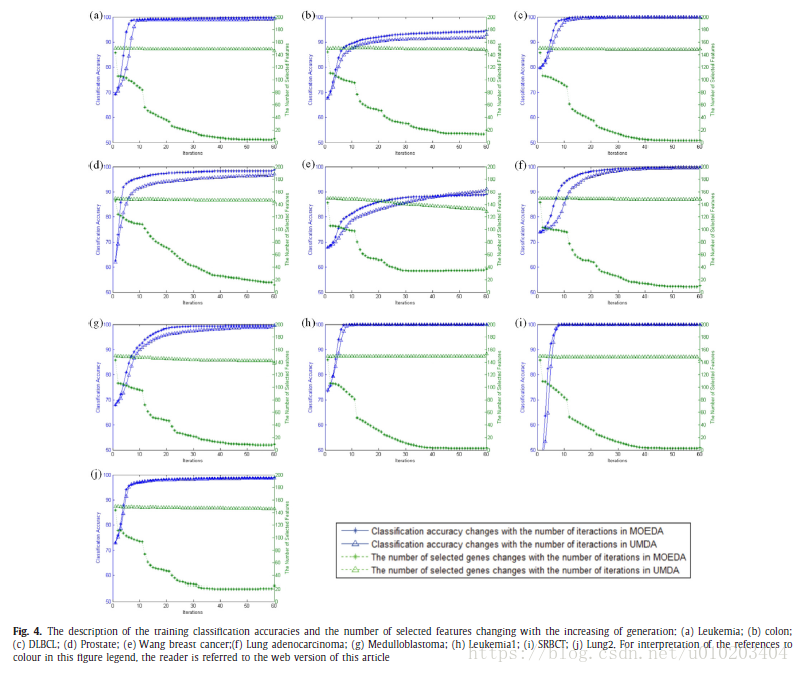

这篇关于基因表达微阵列数据分类的多目标启发式算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




