本文主要是介绍Burp Suite抓取明文,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
Burp Suite代理
正常的通信模式
Burp Suite代理后通信模式
设置代理
安装证书
导出证书
Burp Suite导入
浏览器下载证书
安装证书
管理证书
导入证书
下一步
导入证书
下一步
完成
抓明文的例子
1、修改浏览器代理
编辑2、开启拦截编辑
3、查看抓取历史
4、抓取了腾讯云的一个数据包明文
Burp Suite代理
正常的通信模式

Burp Suite代理后通信模式
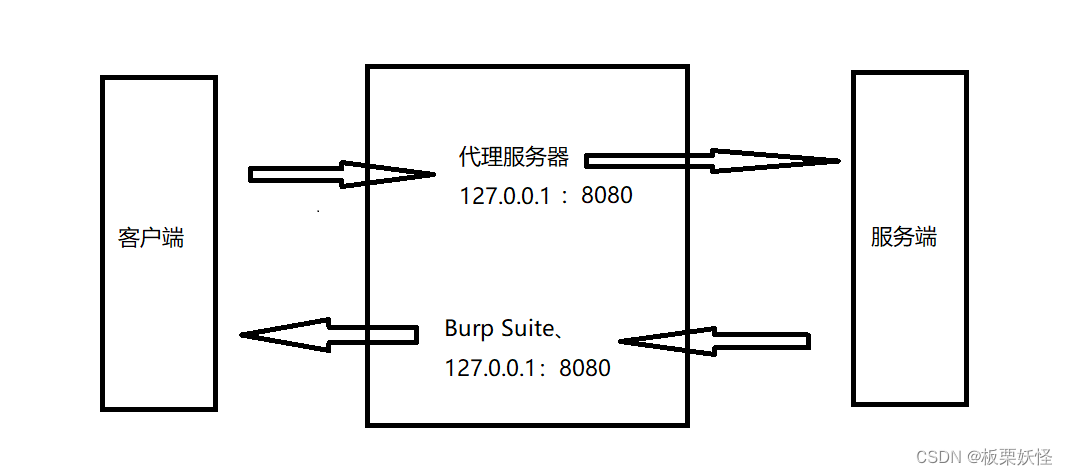
将代理设置到自己本机,然后客户端在向服务端发起请求的时候会经过代理,然后你可以在代理上面对发送的请求进行修改,同理在服务端回应客户端请求的时候,代理也可以拦截,然后进行对回复的数据进行修改。
设置代理
设置代理可使用插件

或者

下面以Proxy SwitchyOmega来在Microsoft Edge做示例,
1、首先下载插件
在两个地方寻找扩展,两个地方都可以找到,点击扩展以后,在点击扩展里面的获取Microsoft Edge扩展

2、搜索下载插件,上面两个插件都可以

3、下载之后创建代理

4、设置代理
(注:设置的代理最好如下图所示)
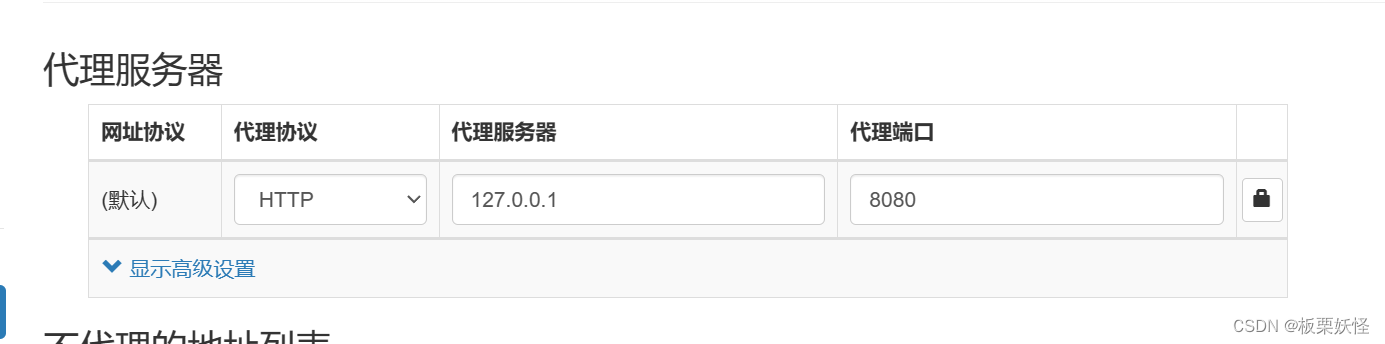
为啥要设置如上图所示的代理
打开我们的Burp Suite,按照如下图所示查看Burp Suite代理,浏览器代理要和Burp Suite代理一样
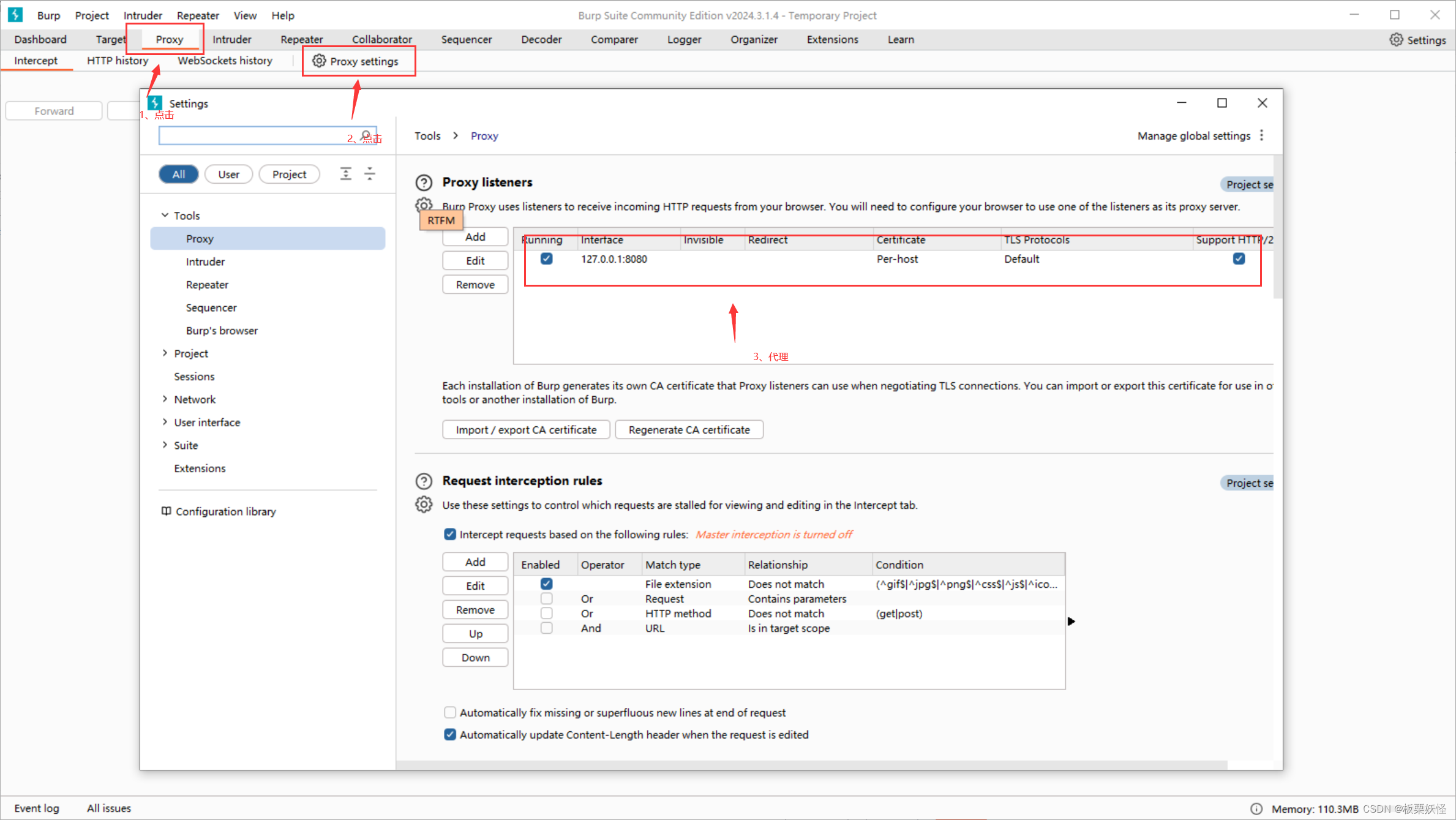
安装证书
导出证书
如果按照上面的步骤进行配置后,那么burp suite只可以抓取http的数据,想要抓取https的数据,需要安装证书。但是burp suite不是合法的数字证书认证机构,想要抓取https的数据,需要伪造公钥证书,获取客户端的信任。所以就需要在你的客户端装证书,这个证书是根证书。用来验证客户端得到的证书是合法的。
安装证书有两方式一种是在Burp Suite导入,一种是浏览器下载证书
Burp Suite导入
进入设置

导入证书
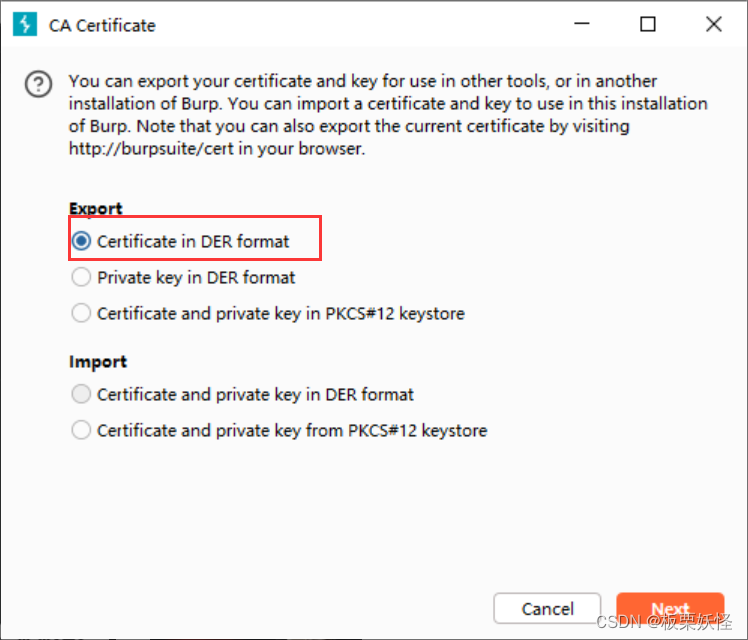
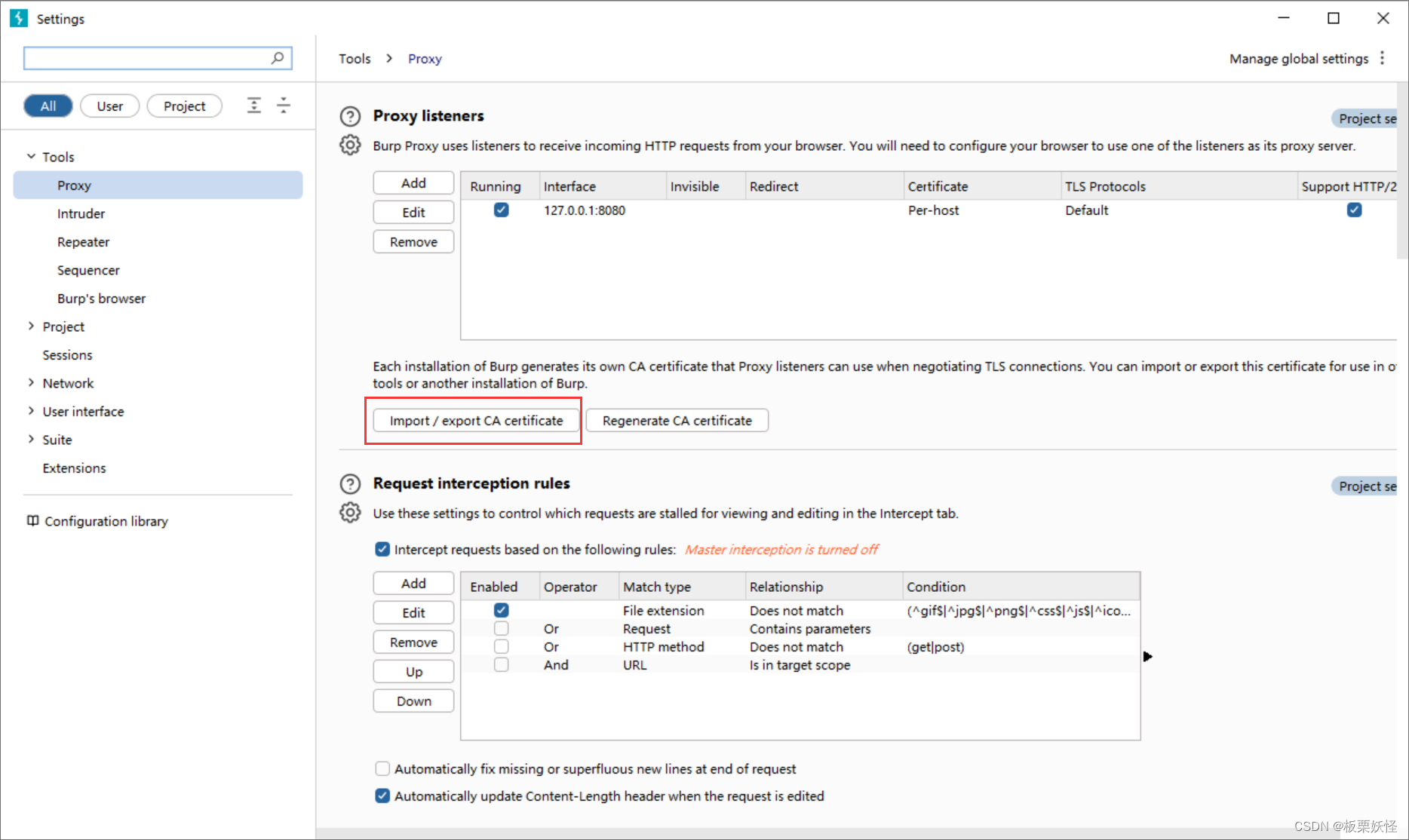 选择证书
选择证书
 选择要下载的路径
选择要下载的路径 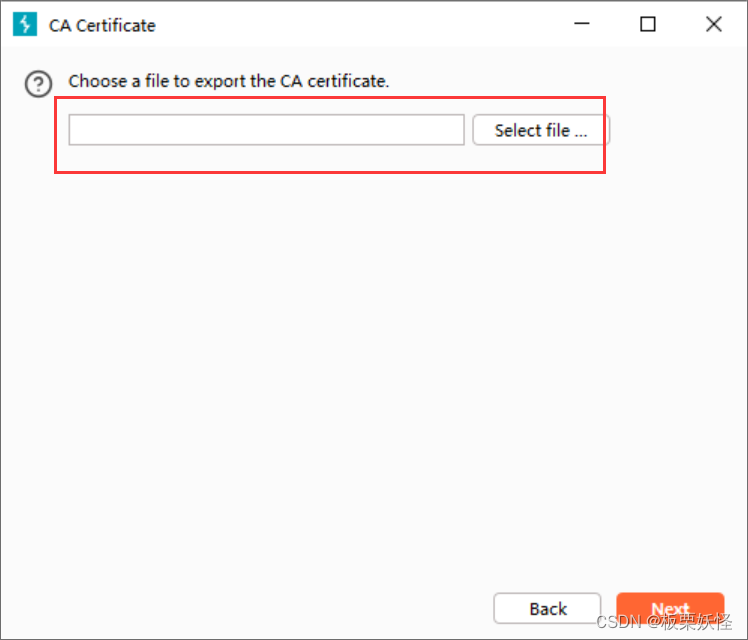
文件名要是cacert.der

然后next,就成功导出了
浏览器下载证书
打开burpsuite,开启浏览器代理,访问http://burp,如图点击下载CA证书


安装证书
双击cacert.der安装
或者在浏览器的设置中搜索证书,浏览器中进行安装
一下是浏览器中进行安装的步骤
管理证书

导入证书
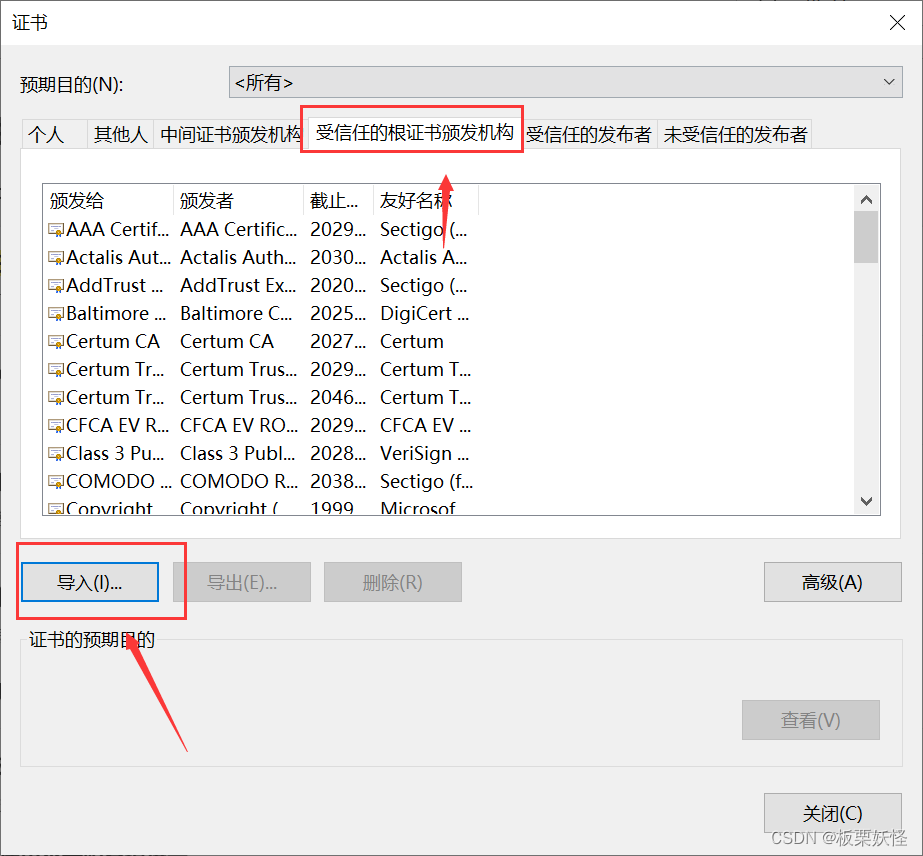
下一步

导入证书

下一步

完成

这时候就正常可以明文抓取https的数据包了
抓明文的例子
1、修改浏览器代理

2、开启拦截
3、查看抓取历史

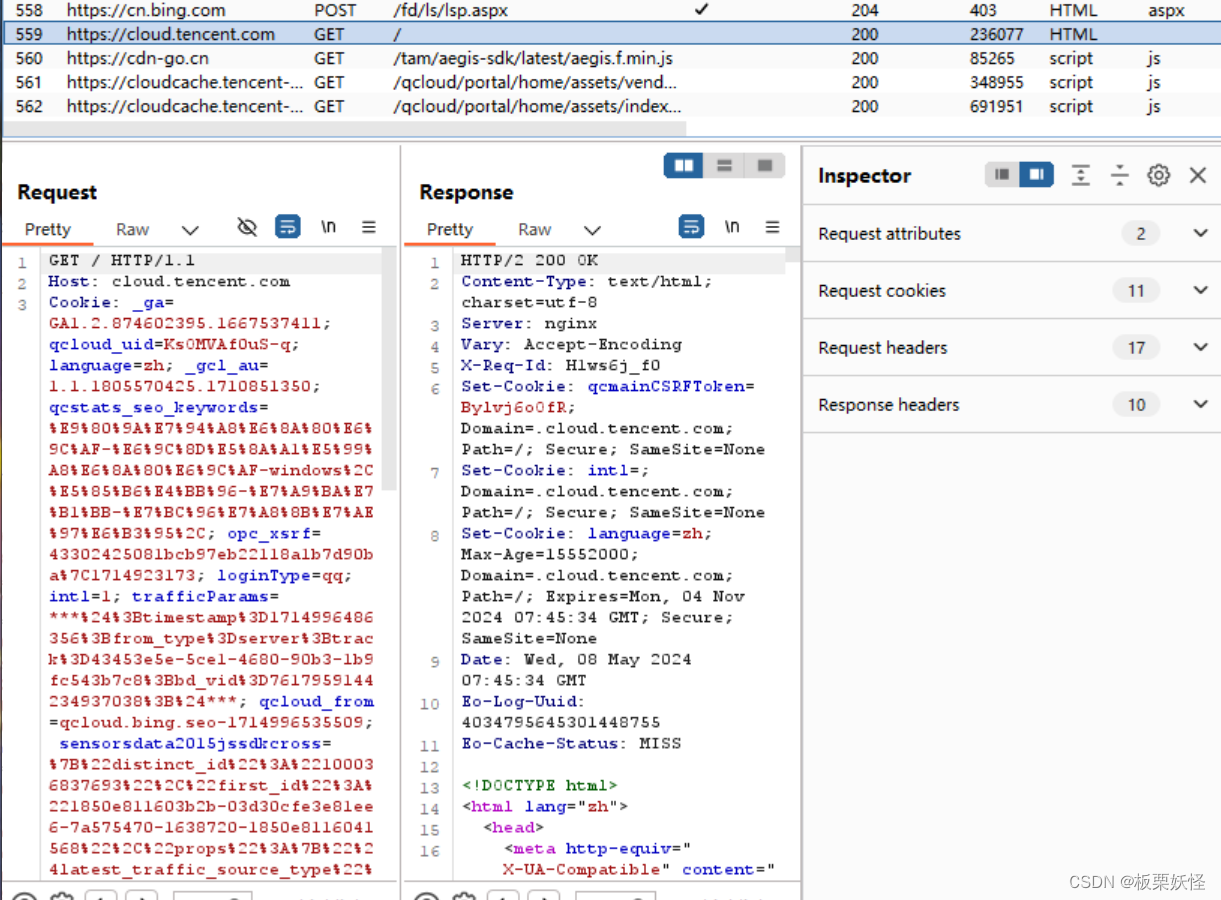
4、抓取了腾讯云的一个数据包明文
不嫌弃的点点关注,点点赞 ଘ(੭ˊᵕˋ)੭* ੈ✩‧₊˚
这篇关于Burp Suite抓取明文的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!