本文主要是介绍BFS专题——FloodFill算法:200.岛屿数量,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 题目描述
- 算法原理
- 代码实现
- C++
- Java
题目描述
题目链接:200.岛屿数量

PS:注意题目中每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。也就是说斜角是不算了, 例如示例二,是三个岛屿。
算法原理
这道题目是 DFS,BFS,并查集,基础题目,因为本博客属于BFS专题,所以只会讲解如何用BFS解决,具体如下:
遍历整个矩阵,每次找到⼀块陆地的时候:
- 说明找到⼀个岛屿,记录到最终结果 ret ⾥⾯;
- 并且将这个陆地相连的所有陆地,也就是这块岛屿,全部变成海洋。这样的话,我们下次遍历到这块岛屿的时候,它已经是海洋了,不会影响最终结果。(PS:可以在原数组上改也可以用一个 bool 类型的visited数组标记,笔试可以直接改,面试能不能改需要询问面试官)
- 其中变成海洋的操作,可以利⽤深搜和宽搜解决,其实就是 733. 图像渲染这道题~
这样,当我们,遍历完全部的矩阵的时候, ret 存的就是最终结果。
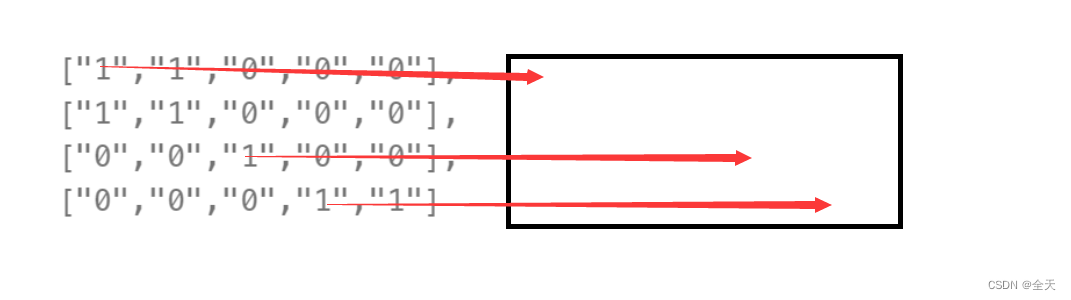
三个箭头是每次遇到新岛屿的时候,将vis数组标记为true,剩下的在陆地在每次q.push的时候标记为true。
不少同学用广搜做这道题目的时候超时了。 就是因为这里有一个广搜中很重要的细节:根本原因是只要加入队列就代表走过,就需要标记,而不是从队列拿出来的时候再去标记走过。
很多同学可能说这有区别吗?
如果从队列拿出节点,再去标记这个节点走过,就会发生这样的结果,会导致很多节点重复加入队列。
代码实现
C++
class Solution {typedef pair<int, int> PII;int dx[4] = {0, 0, -1, 1};int dy[4] = {-1, 1, 0, 0};bool vis[301][301];int m, n;public:int numIslands(vector<vector<char>>& grid) {int ret = 0;m = grid.size(), n = grid[0].size();for (int i = 0; i < m; ++i) {for (int j = 0; j < n; ++j) {if (grid[i][j] == '1' && !vis[i][j]){bfs(grid, i, j);ret++;}}}return ret;}void bfs(vector<vector<char>>& grid, int i, int j) {queue<PII> q;q.push({i, j});vis[i][j] = true;while (!q.empty()) {auto [a, b] = q.front();q.pop();for (int k = 0; k < 4; ++k) {int x = a + dx[k], y = b + dy[k];if (x >= 0 && x < m && y >= 0 && y < n && grid[x][y] == '1' && !vis[x][y]){q.push({x, y});vis[x][y] = true;}}}}
};
Java
class Solution {int[] dx = { 0, 0, -1, 1 };int[] dy = { 1, -1, 0, 0 };boolean[][] vis = new boolean[301][301];int m, n;public int numIslands(char[][] grid) {m = grid.length;n = grid[0].length;int ret = 0;for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {if (grid[i][j] == '1' && !vis[i][j]) {ret++;bfs(grid, i, j);}}}return ret;}public void bfs(char[][] grid, int i, int j) {Queue<int[]> q = new LinkedList<>();q.add(new int[] { i, j });vis[i][j] = true;while (!q.isEmpty()) {int[] t = q.poll();int a = t[0], b = t[1];for (int k = 0; k < 4; k++) {int x = a + dx[k], y = b + dy[k];if (x >= 0 && x < m && y >= 0 && y < n && grid[x][y] == '1' &&!vis[x][y]) {q.add(new int[] { x, y });vis[x][y] = true;}}}}
}
这篇关于BFS专题——FloodFill算法:200.岛屿数量的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








