本文主要是介绍Elasticsearch:如何使用 Java 对索引进行 ES|QL 的查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在我之前的文章 “Elasticsearch:对 Java 对象的 ES|QL 查询”,我详细介绍了如何使用 Java 来对 ES|QL 进行查询。对于不是很熟悉 Elasticsearch 的开发者来说,那篇文章里的例子还是不能单独来进行运行。在今天的这篇文章中,我来详细地介绍如何把那个例子跑起来。更多关于 ES|QL 的动手实践,请阅读文章 “Elasticsearch:ES|QL 查询展示”。
为了说明方便,我把所有的代码放在地址 GitHub - liu-xiao-guo/elasticsearch-java-esql 以方便大家学习。这是一个 Maven 的项目。我们可以使用如下的命令来进行克隆:
git clone https://github.com/liu-xiao-guo/elasticsearch-java-esql准备工作
Elasticsearch 及 Kibana 安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的链接来进行安装:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Kibana:如何在 Linux,MacOS 及 Windows上安装 Elastic 栈中的 Kibana
在安装的时候,我们选择 Elastic Stack 8.x 来进行安装。特别值得指出的是:ES|QL 只在 Elastic Stack 8.11 及以后得版本中才有。你需要下载 Elastic Stack 8.11 及以后得版本来进行安装。
在首次启动 Elasticsearch 的时候,我们可以看到如下的输出:
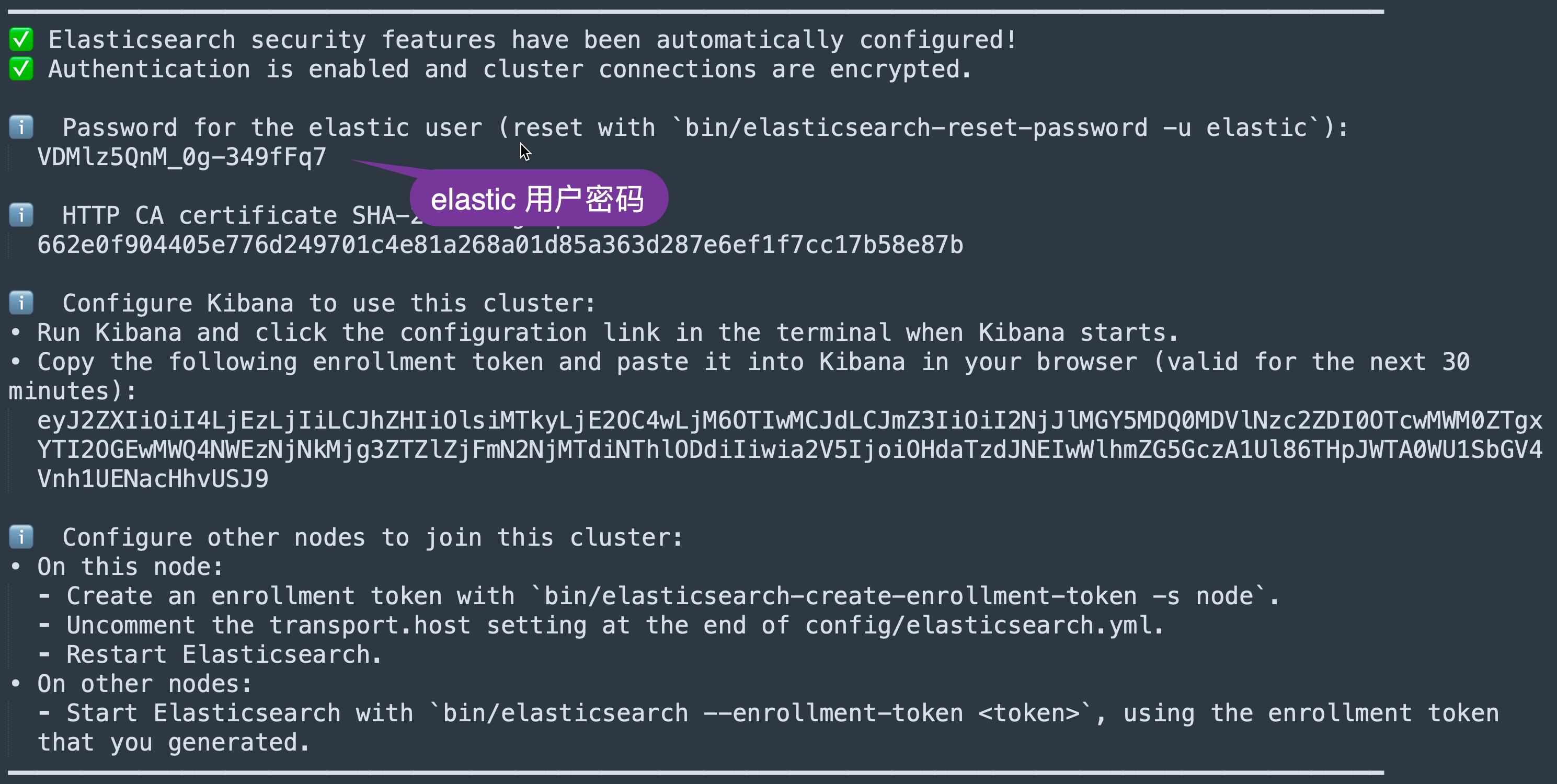
我们记下这个密码在如下的配置中进行使用。
准备数据集
我们的数据集非常简单。我从之前的文章中下载了文章里的数据集,但是我发现数据集中字段和文章里的字段并不相同,而且那个 year 定义为 integer,但是下载数据集里的数据其实是一个 date 类型的数据。为了说明问题,我们也不需要那么多的数据。我从中挑出了10个数据,并把数据集置于链接。
在我们克隆完项目的时候,我们可以看到:
$ pwd
/Users/liuxg/java/elasticsearch-java-esql
$ ls
pom.xml sample.csv src这里的 sample.csv 就是我们所需要的数据集。我们的一条数据是这样的。

为了方便我们把它的字段重新命令为:
title,description,authors,image,previewLink,publisher,year,infoLink,categories,ratings如下是一条示例文档:
Its Only Art If Its Well Hung!,,['Julie Strain'],http://books.google.com/books/content?id=DykPAAAACAAJ&printsec=frontcover&img=1&zoom=1&source=gbs_api,http://books.google.nl/books?id=DykPAAAACAAJ&dq=Its+Only+Art+If+Its+Well+Hung!&hl=&cd=1&source=gbs_api,,1996,http://books.google.nl/books?id=DykPAAAACAAJ&dq=Its+Only+Art+If+Its+Well+Hung!&hl=&source=gbs_api,['Comics & Graphic Novels'],配置项目
为了能够使得项目能够正常运行,我们必须配置如下的 application.conf 文件:
$ pwd
/Users/liuxg/java/elasticsearch-java-esql
$ tree -L 10
.
├── http_ca.crt
├── pom.xml
├── sample.csv
└── src├── main│ ├── java│ │ └── com│ │ └── example│ │ └── esql│ │ ├── Book.java│ │ └── EsqlArticle.java│ └── resources│ └── application.conf└── test└── java
application.conf
server-url=https://localhost:9200
api-key=NTdYSFBJOEJ6TnJzZHhPZ0xDcGQ6Y09hYTFzZDVRLUtSVHVVZWVaOEJKdw==
csv-file=/Users/liuxg/java/elasticsearch-java-esql/sample.csv
cert_path=/Users/liuxg/elastic/elasticsearch-8.13.2/config/certs/http_ca.crt如上所示,我们需要根据自己的设置进行配置。我们需要填入 Elasticsearch 的访问地址,sample.csv 的路径及 Elasticsearch 的证书。我们需要申请一个 API key 来访问 Elasticsearch:
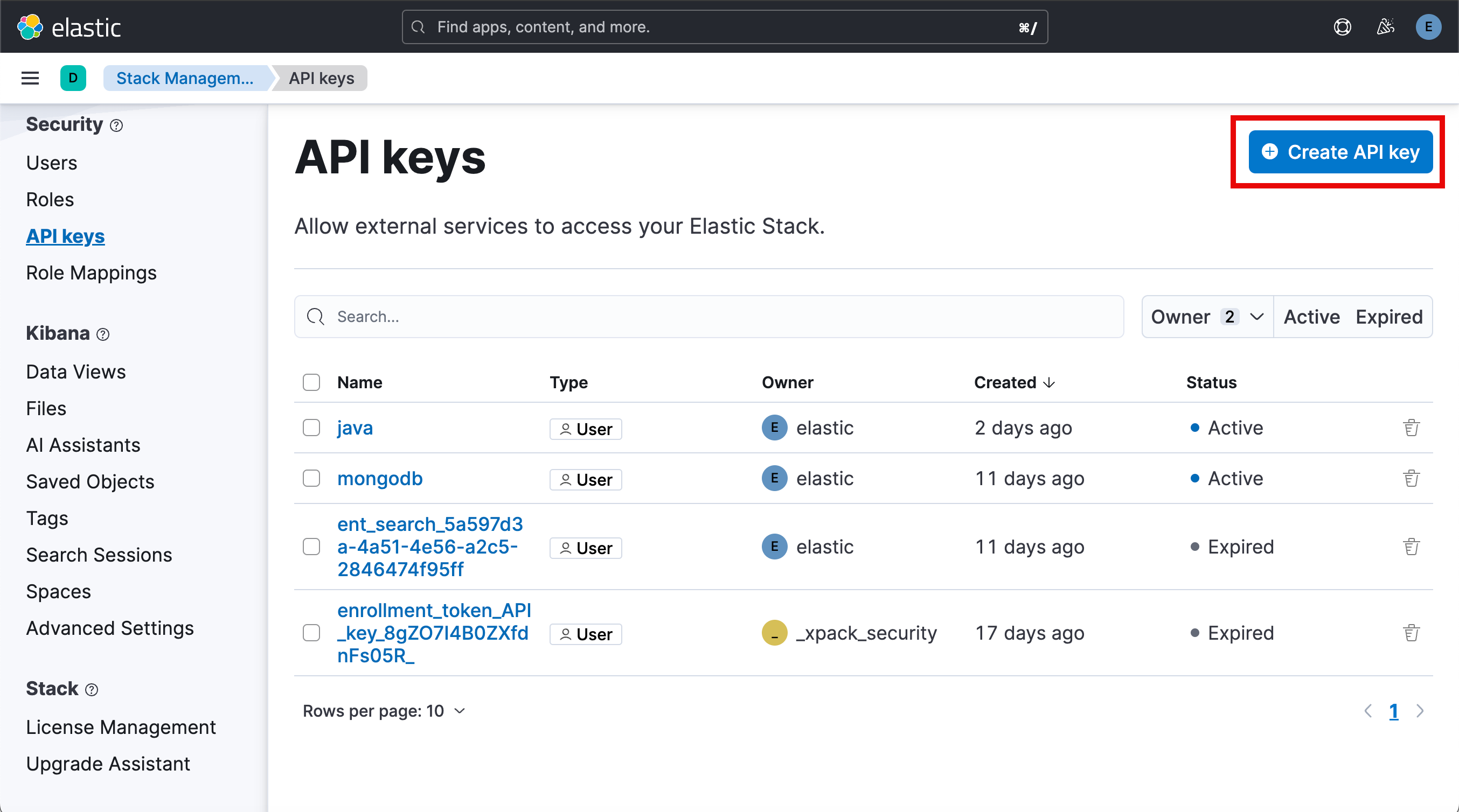
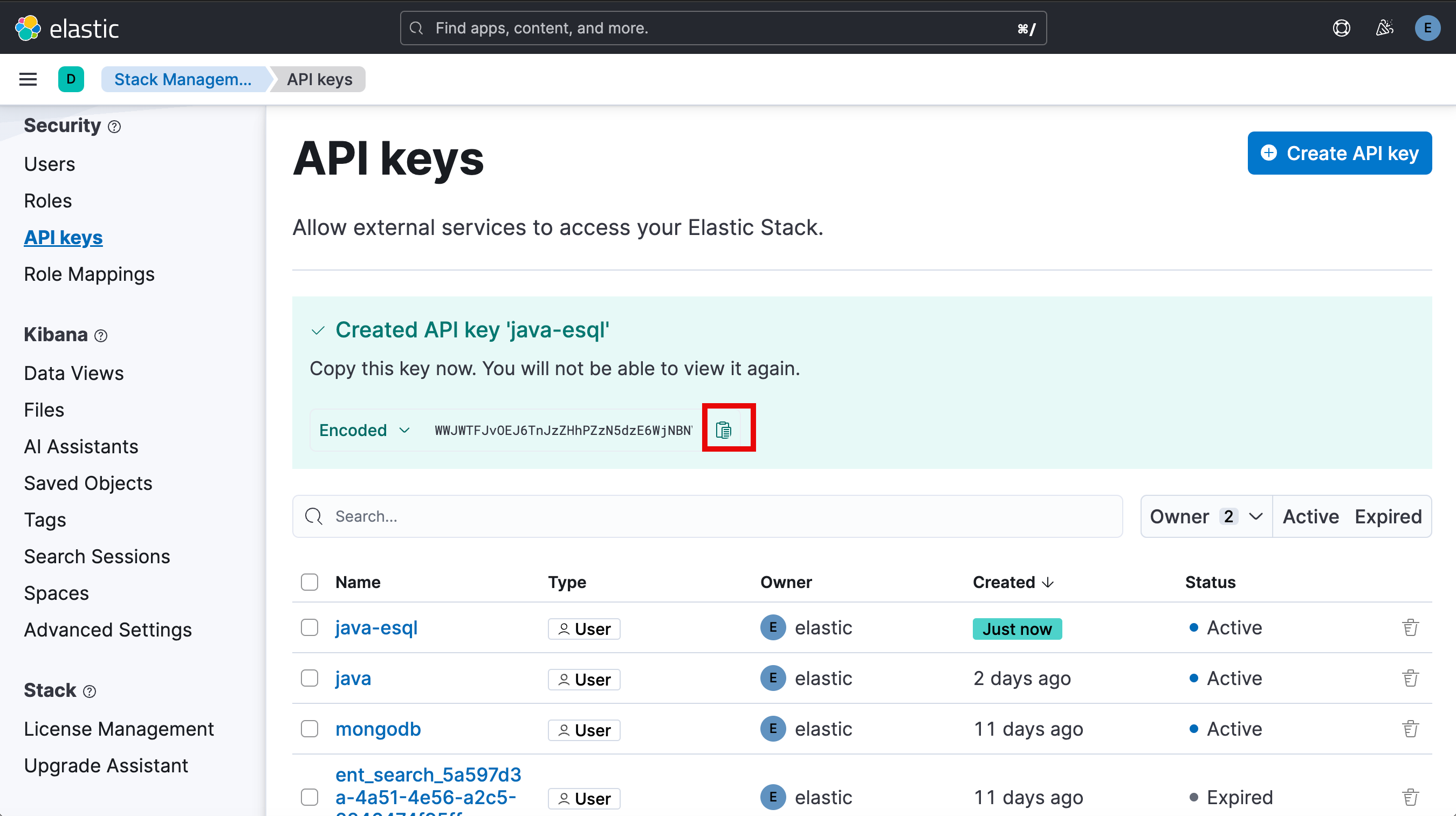
至此,我们的配置就基本完成了。
代码解读
写入文档
首先我们根据 csv 格式的字段创建了如下的一个 Book.java 类:
Book.java
package com.example.esql;import java.util.Date;public record Book(String title,String description,String author,String image,String previewLink,String publisher,Integer year,String infoLink,String categories,Float ratings) {}它分别对应于 csv 示例文档中的各个字段。
接下来,我们来阅读 EsqlArticle.java 文件。我们首先读出在 application.conf 文件中的配置:
String dir = System.getProperty("user.dir");System.out.println(dir);Properties prop = new Properties();Path path = Paths.get(dir, "src", "main", "resources", "application" +".conf");prop.load(new FileInputStream(path.toString()));String serverUrl = prop.getProperty("server-url");String apiKey = prop.getProperty("api-key");String csvPath = prop.getProperty("csv-file");String certPath = prop.getProperty("cert_path");System.out.println("serverUrl: " + serverUrl);System.out.println("apiKey: " + apiKey);System.out.println("csvPath: " + csvPath);System.out.println("certPath: " + certPath);
输出结果:
serverUrl: https://localhost:9200
apiKey: NTdYSFBJOEJ6TnJzZHhPZ0xDcGQ6Y09hYTFzZDVRLUtSVHVVZWVaOEJKdw==
csvPath: /Users/liuxg/java/elasticsearch-java-esql/sample.csv
certPath: /Users/liuxg/elastic/elasticsearch-8.13.2/config/certs/http_ca.crt我们接下来创建 Elasticsearch 访问客户端:
Path caCertificatePath = Paths.get(certPath);CertificateFactory factory =CertificateFactory.getInstance("X.509");Certificate trustedCa;try (InputStream is = Files.newInputStream(caCertificatePath)) {trustedCa = factory.generateCertificate(is);}KeyStore trustStore = KeyStore.getInstance("pkcs12");trustStore.load(null, null);trustStore.setCertificateEntry("ca", trustedCa);SSLContextBuilder sslContextBuilder = SSLContexts.custom().loadTrustMaterial(trustStore, null);final SSLContext sslContext = sslContextBuilder.build();RestClient restClient = RestClient.builder(HttpHost.create(serverUrl)).setDefaultHeaders(new Header[]{new BasicHeader("Authorization", "ApiKey " + apiKey)}).setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {@Overridepublic HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpAsyncClientBuilder) {return httpAsyncClientBuilder.setSSLContext(sslContext);}}).build();System.out.println(restClient.isRunning());ObjectMapper mapper = JsonMapper.builder().build();JacksonJsonpMapper jsonpMapper = new JacksonJsonpMapper(mapper);ElasticsearchTransport transport = new RestClientTransport(restClient, jsonpMapper);ElasticsearchClient client = new ElasticsearchClient(transport);由于我们的部署是自签名的,我们需要使用 Elasticsearch 的证书。
我们接下来删除 books 索引,如果它已经存在的话:
final String INDEX_NAME = "books";// Delete the index if it existsif (client.indices().exists(ex -> ex.index(INDEX_NAME)).value()) {client.indices().delete(d -> d.index(INDEX_NAME));}我们接下来创建 books 索引的 mappings:
if (!client.indices().exists(ex -> ex.index(INDEX_NAME)).value()) {client.indices().create(c -> c.index(INDEX_NAME).mappings(mp -> mp.properties("title", p -> p.text(t -> t)).properties("description", p -> p.text(t -> t)).properties("author", p -> p.text(t -> t)).properties("image", p -> p.text(t -> t)).properties("previewLink", p -> p.text(t -> t)).properties("publisher", p -> p.text(t -> t)).properties("year", p -> p.short_(s -> s)).properties("infoLink", p -> p.text(t -> t)).properties("categories", p -> p.text(t -> t)).properties("ratings", p -> p.halfFloat(hf -> hf))));}你可以看到 year 是 short 类型的数据,而 ratings 是一个浮点数。其它的均为 text 字段。
我们接下来使用 Jackson 的 CSV 映射器来读取该文件,所以让我们对其进行配置:
Instant start = Instant.now();System.out.println("Starting BulkIndexer... \n");CsvMapper csvMapper = new CsvMapper();CsvSchema schema = CsvSchema.builder().addColumn("title") // same order as in the csv.addColumn("description").addColumn("author").addColumn("image").addColumn("previewLink").addColumn("publisher").addColumn("year").addColumn("infoLink").addColumn("categories").addColumn("ratings").setColumnSeparator(',').setSkipFirstDataRow(true).build();MappingIterator<Book> it = csvMapper.readerFor(Book.class).with(schema).readValues(new FileReader(csvPath));然后我们将逐行读取 csv 文件并使用 BulkIngester 优化摄取:
BulkIngester ingester = BulkIngester.of(bi -> bi.client(client).maxConcurrentRequests(20).maxOperations(5000));boolean hasNext = true;int j = 0;while (hasNext) {try {Book book = it.nextValue();ingester.add(BulkOperation.of(b -> b.index(i -> i.index(INDEX_NAME).document(book))));hasNext = it.hasNextValue();} catch (JsonParseException | InvalidFormatException e) {// ignore malformed dataSystem.out.println("Something is wrong at: " + j);}j ++;}ingester.close();由于我们使用的文档数非常之少,只有10个文档。索引的速度非常之快。
查询文档
现在是时候从书籍数据中提取一些信息了。假设我们想要找到 ['Julie Strain']。请注意,为了方便,我们在摄入文档的时候并没有针对 author 来进行任何的处理。它应该是一个数组。在这里我们为什么需要添加 [ 及 ] 符号呢?这是因为截止目前的 ES|QL 版本发布,所有的 text 字段都被当做为 keyword 字段。全文搜索还没有完全实现。
String queryAuthor ="""from books| where author == "['Julie Strain']"| sort year desc| limit 10""";List<Book> queryRes = (List<Book>) client.esql().query(ObjectsEsqlAdapter.of(Book.class), queryAuthor);System.out.println("~~~\nObject result author:\n" + queryRes.stream().map(Book::title).collect(Collectors.joining("\n")));ResultSet resultSet = client.esql().query(ResultSetEsqlAdapter.INSTANCE, queryAuthor);System.out.println("~~~\nResultSet result author:");while (resultSet.next()) {System.out.println(resultSet.getString("title"));}上面显示的结果是:
~~~
Object result author:
Its Only Art If Its Well Hung!~~~
ResultSet result author:
Its Only Art If Its Well Hung!感谢使用 Book.class 作为目标的 ObjectsEsqlAdapter,我们可以忽略 ES|QL 查询的 json 结果是什么,而只关注客户端自动返回的更熟悉的书籍列表。
对于那些习惯 SQL 查询和 JDBC 接口的人来说,客户端还提供了 ResultSetEsqlAdapter,可以以同样的方式使用它,而是返回一个 java.sql.ResultSet。
ResultSet resultSet = esClient.esql().query(ResultSetEsqlAdapter.INSTANCE,queryAuthor);另一个例子,我们现在想要找出出版商为 Plympton PressIntl 中评分最高的书籍:
String queryPublisher ="""from books| where publisher == "Plympton PressIntl"| sort ratings desc| limit 10| sort title asc""";queryRes = (List<Book>) client.esql().query(ObjectsEsqlAdapter.of(Book.class), queryPublisher);System.out.println("~~~\nObject result publisher:\n" + queryRes.stream().map(Book::title).collect(Collectors.joining("\n")));上面代码运行的结果为:
Object result publisher:
Rising Sons and Daughters: Life Among Japan's New Young你可以在地址 GitHub - liu-xiao-guo/elasticsearch-java-esql 下载源码。
这篇关于Elasticsearch:如何使用 Java 对索引进行 ES|QL 的查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






