本文主要是介绍DS:顺序表、单链表的相关OJ题训练(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎各位来到 Harper.Lee 的学习小世界!
博主主页传送门:Harper.Lee的博客主页
想要一起进步的uu可以来后台找我交流哦!
在DS:单链表的实现 和 DS:顺序表的实现这两篇文章中,我详细介绍了顺序表和单链表的实现方法及其相关注意点,uu们可以点击跳转学习。俗话说“光说不练假把式”,下面我们通过几道经典OJ算法题来进行顺序表和单链表的相关训练!
一、力扣--203. 移除链表元素
题目:给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回新的头节点 。

思路1:遍历原链表,将值为val的节点释放掉(很像单链表中删除指定位置的节点)。
思路2:找值不为val的节点,将其尾插到不带头的新链表中,返回该新链表的头节点。
创建的结构体指针newHead和newTail均指为空(初始时新链表为空)。改变的是newTail,而不是newHead。 a. 创建链表的第一个节点:从原链表第一个节点开始判断,该节点的值如果不是val,那么他就是新链表第一个节点newHead从第一个节点开始创建新链表,相当于是头插(同时也是尾插); b. 其余节点依次进行遍历并判断节点的值是否为val:如果是,就进行释放操作 ;如果不是,就尾插入新链表中,用newTail来接收; c. 遍历链表使用pcur。
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;//说明该结构体中的内容,但是如果要使用该结构体,就需要struct ListNode来定义结构体,太麻烦,所以重命名 * };*/typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val) {//创建一个新链表ListNode* newHead,*newTail;//????newHead = newTail=NULL;//遍历原链表ListNode* pcur = head;//head是传进来的参数(结构体指针)while(pcur)//pcur用来遍历链表{//找值不为val的节点,尾插到新链表。if(pcur->val!=val){//链表为空if(newHead==NULL){newHead=newTail=pcur;//插入的第一个节点既是头节点也是尾节点}//链表不为空else{//newtail的下一个位置插入数据newTail->next=pcur;newTail=newTail->next;}}pcur=pcur->next;//pcur往下走继续遍历}if(newTail)newTail->next = NULL;//newTail的next指针要置为空return newHead;
}二、力扣--206. 反转链表
题目描述:给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
 思路1:创建一个新链表newHead和newTail,从第一个节点(作为newTail且不再改变)开始遍历原链表同时将原链表的节点利用头插法建立该新链表。
思路1:创建一个新链表newHead和newTail,从第一个节点(作为newTail且不再改变)开始遍历原链表同时将原链表的节点利用头插法建立该新链表。
思路2:创建3个指针,完成原链表的翻转 。
/*** Definition for singly-linked list.* struct ListNode {* int val;//已知存储的数据和指向下一个节点的指针* struct ListNode *next;* };*/typedef struct ListNode ListNode;//将结构体指针struct ListNode重命名为ListNode
struct ListNode* reverseList(struct ListNode* head) {//先判断链表是否为空if(head==NULL){return head;}//创建三个指针:n1 n2 n3 ,让n2的next指向n1,//n1 = n2,n2 = n3,n3 = n3->nextListNode* n1, *n2,*n3;n1 = NULL,n2 = head;n3 = n2->next;//初始化三个指针,n2指向n3while(n2){//先反转方向,再n1=n2; n2=n3;n3=n3->next;n2->next=n1; //n2的next指针指向n1=n2;n2=n3;if(n3)//n3 走到为空了,不能继续走也就是不能解引用了n3=n3->next;}return n1;//因为链表的接待有数据范围,所以说明链表 可能为空,n3 = n2->next,可能不合适
}三、力扣--21. 合并两个有序链表
题目描述:将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。

从前往后找小数据,数据会丢失,所以从后往前找大数据.
第一个版本的代码(会报错) :
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {ListNode* l1 = list1;ListNode* l2 = list2;//创建新链表ListNode* newTail,*newHead;newHead = newTail = NULL;while(l1 && l2)//使用 &&,因为两个要同时满足非空链表 {if(l1->val<l2->val)//开始比较存储的值的大小{//l1拿下来进行尾插if(newHead == NULL)//头节点为空{newHead=newTail=l1;}else{//新链表不为空newTail->next=l1;newTail=newTail->next;}l1=l1->next;//原来的链表也要继续往前遍历}else{//l2拿下来尾插if(newHead==NULL){newHead=newTail=l2;}else{newTail->next=l2;newTail=newTail->next;}l2=l2->next;}}//跳出循环,面临两种情况:l1走到空 或者 l2走到空,上下一个节点,止咳尾插,不用再比较了if(l2)//l2不为空{newTail->next = l2;}if(l1){newTail->next = l1;}return newHead;
}1、 报错:
分析报错具体原因:
如果list1为空链表,l1也为空,不能进入while循环,所以来到跳出while循环的 if 部分。l2不为空,执行 newTail->next = l2; 但是因为没有进入while循环,所以新链表也无法在while循环中创建节点,也就是说,新链表仍然时空连,而此刻 newTail->next 操作 相当于对空指针进行解引用操作。因而报出上图所示错误。
解决办法:链表为空有一个提示,说明链表可能同时为空。根据提修改代码:判断链表为空的情况:做另外的处理。

首先链表是已经排为升序了的,如果其中一个链表为空,可直接返回里另外一个链表;如果两个链表都为空,那么就直接返回NULL。先增加判断链表是否为空的情况。
(第二个版本代码)正确代码如下:
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {//判断链表是否为空:(添加部分在这里)if(list1 == NULL){return list2;}if(list2 == NULL){return list1;}ListNode* l1 = list1;ListNode* l2 = list2;//创建新链表ListNode* newTail,*newHead;newHead = newTail = NULL;while(l1 && l2)//使用 &&,因为两个要同时满足非空链表 {if(l1->val<l2->val)//开始比较存储的值的大小{//l1拿下来进行尾插if(newHead == NULL)//头节点为空{newHead=newTail=l1;}else{//新链表不为空newTail->next=l1;newTail=newTail->next;}l1=l1->next;//原来的链表也要继续往前遍历}else{//l2拿下来尾插if(newHead==NULL){newHead=newTail=l2;}else{newTail->next=l2;newTail=newTail->next;}l2=l2->next;}}//跳出循环,面临两种情况:l1走到空 或者 l2走到空,上下一个节点,止咳尾插,不用再比较了if(l2)//l2不为空{newTail->next = l2;}if(l1){newTail->next = l1;}return newHead;
}2、存在重复代码,如何优化代码?
在上面的代码中观察发有一段重复出现的代码:将节点拿下来进行尾插处理。我们将这部分代码进行优化处理。一种优化方法是:函数封装。此外,还可以进行
代码重复的原因:新链表存在空链表和非空链表两种情况。
解决思路:让新链表不为空。
解决办法:之前的newTaail和newHead是将其创建为空(NULL),现在为它动态申请一块内存
newHead = newTail = NULL; 改成newHead = newTail = (ListNode*)malloc(sizeof(ListNode)); 动态申请空间但是不存储任何数据。此时链表不为空,头尾指针都指向一个有效的地址(节点)。然后将while循环中判断链表是否为空的代码删掉:
删除如下注释:
//while循环中删除判断部分: while(l1 && l2)//使用 &&,因为两个要同时满足非空链表 {if(l1->val<l2->val)//开始比较存储的值的大小{//l1拿下来进行尾插//if(newHead == NULL)//头节点为空//{//newHead=newTail=l1;//else{//新链表不为空newTail->next=l1;newTail=newTail->next;// }l1=l1->next;//原来的链表也要继续往前遍历}else{//l2拿下来尾插//if(newHead==NULL)//{//newHead=newTail=l2;// }// else// {newTail->next=l2;newTail=newTail->next;// }l2=l2->next;}}3、 注意,此时不能或者直接返回newHead,因为最后得到的链表多了一部分,这一部分是因为系统随机给动态申请的空间赋随机值。因此要返回不包含此部分的链表。return newHead->next;(最后的链表如下图所示:)

4、此外,动态内存申请的空间都是要释放掉的,而这里没有释放操作但不会报错,是因为:我们写的程序需要提交到力扣服务端进行运行后,会自动释放。但是如果是我们自己写代码,为了养成好的空间开辟习惯,记得释放空间。如果直接 free(newHead); 这样就找不到原来的空间了,也就不能通过return newHead->next;将最终结果返回了。因此,利用结构体指针ret记录空间,然后再释放,返回ret。
最终代码如下:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {//判断链表是否为空://newHead = newTail = NULL;newHead = newTail = (ListNode*)malloc(sizeof(ListNode));ListNode* l1 = list1;ListNode* l2 = list2;//创建新链表ListNode* newTail,*newHead;// newHead = newTail = NULL;newHead = newTail = (ListNode*)malloc(sizeof(ListNode));//动态申请空间但是不存储任何数据 while(l1 && l2)//使用 &&,因为两个要同时满足非空链表 {if(l1->val<l2->val){newTail->next=l1;newTail=newTail->next;l1=l1->next;//原来的链表也要继续往前遍历}else{newTail->next=l2;newTail=newTail->next;l2=l2->next;}}if(l2)//l2不为空{newTail->next = l2;}if(l1){newTail->next = l1;}ListNode* ret = newHead->next;free(newHead);newHead = NULL;return ret;
}5、刚动态申请空间的那部分节点没有存入数据,它实际是链表分类中的一种,叫做带头链表。头节点叫做哨兵位,只起站岗的作用,没有任何有效意义。
此题和之前的合并两个有序数组有点相似。
四、力扣--876. 链表的中间节点
题目描述:给你单链表的头结点 head ,请你找出并返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。

思路一:count 记录节点数,直接返回(count/2)节点的next节点
思路二: 创建指针数组用来记录每一次遍历的数组,然后长度除以对应的数组的指针就是中间节点。
思路三:快慢指针法。奇数个节点slow每次走一步,fast每次走两步,重复这个操作,直到fast->next==NULL时,停止,此时,slow指向的就是中间节点;偶数个节点slow每次走一步,fast每次走两步,重复这个操作,直到fast==NULL时,停止,此时,slow指向的就是中间节点。即使链表很长好,此方法也可以,因为对链表只需遍历一遍。其中的原理在于:满足2slow=fast。
typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head) {//创建快慢指针:ListNode* slow = head;ListNode* fast = head;while(fast && fast->next)//fast和fats->next不能交换位置,//如果链表是在有欧束个节点的情况下,fast的最后一次会直接走到空,fast->next就是对其进行解引用操作,->相当于解引用操作符{slow=slow->next;fast=fast->next->next;}//此时slow指向的就是中间节点return slow;
}1、循环条件可以进行交换吗?
循环条件:while(fast && fast->next),其中循环条件不能进行交换,否则会出现链表为偶数个节点的情况下,fast走到头时,fast == NULL已经满足了,fast->next为空,空指针解引用报错的情况。
2、快慢指针总结:
慢指针每次走一步,快指针每次走两步,慢指针*2 = 快指针。快指针遍历完一遍链表时,快指针在链表的中间位置 。如果链表的节点有偶数个,fast==NULL;如果链表的节点是奇数个,fast->next==NULL。
五、牛客--环形链表的约瑟夫问题
背景:著名的Josephus问题
据说著名犹太历史学家Josephus有过以下的故事:在罗⻢⼈占领乔塔帕特后,39个犹太⼈与
Josephus及他的朋友躲到⼀个洞中,39个犹太⼈决定宁愿死也不要被⼈抓到,于是决定了⼀个⾃杀⽅式,41个⼈排成⼀个圆圈,由第1个⼈开始报数,每报数到第3⼈该⼈就必须⾃杀,然后再由下⼀个重新报数,直到所有⼈都⾃杀⾝亡为⽌。
然⽽Josephus?和他的朋友并不想遵从,Josephus要他的朋友先假装遵从,他将朋友与自己排在第16个与第31个位置,于是逃过了这场死亡游戏。
详细分析过程如下图片所示(第一次尝试传入手写笔记照片,可能效果不太理想):
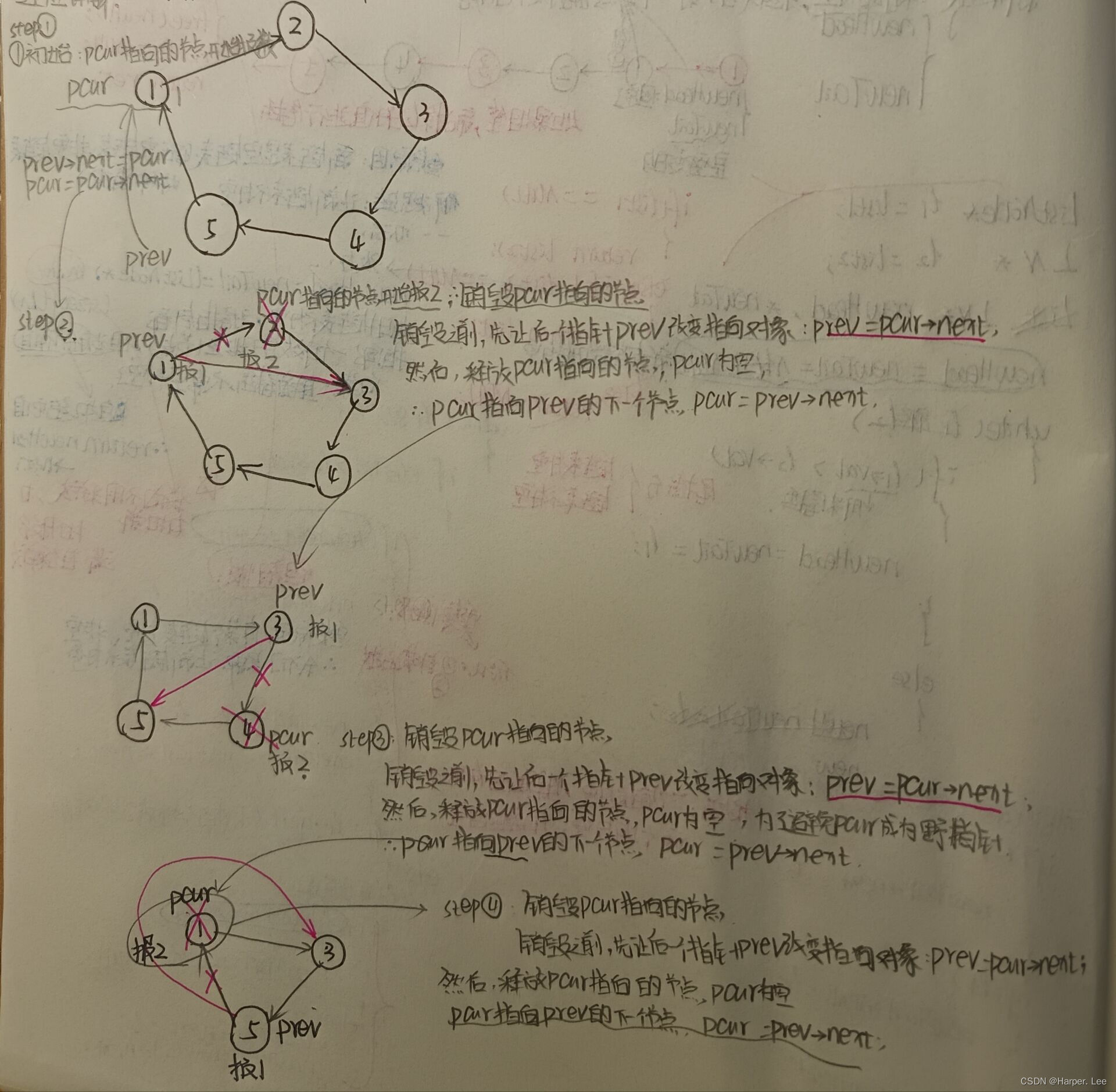

创建带环链表的过程:
首先创建第一个节点,该节点既是phead也是ptail,然后继续创建节点,并将之前先创建的节点与该节点连接在一起(ptail = ptail->next;),直到最后一个节点连接进去。 但此时还没有形成带环链表,加上 ptail->next = phead; 头尾相连,链表成环。

代码如下:
/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * @param n int整型 * @param m int整型 * @return int整型*/#include <stdlib.h>
typedef struct ListNode ListNode;
//创建节点:
ListNode* buyNode(int x)
{ListNode* node = (ListNode*)malloc(sizeof(ListNode));if(node == NULL){exit(1);//内存申请失败}node->val = x;node->next = NULL;return node;
}
//创建带环链表:
ListNode* creatCircle(int n)
{//先创建第一个节点ListNode* phead = buyNode(1);//第一个节点存储数据1ListNode* ptail = phead;//ptail用来尾插for(int i = 2;i <= n;i++){ ptail->next = buyNode(i);//将新创建的节点与链表连接在一起ptail = ptail->next;//ptail也要继续前进}ptail->next = phead;//(首尾相连,链表成环)//return 的方法return ptail;//不返回phead,而是返回ptail
}
int ysf(int n, int m ) {//1. 根据n创建带环链表ListNode* prev = creatCircle(n);//这三句代码就是图片中重复操作的那部分过程ListNode* pcur = prev->next;int count = 1;//初始时count为1,因为前面一句代码中pcur指向了第一个节点,就需要报数//开始报数//当链表只有一个节点时, 跳出循环(最后一个节点的next指向它自己)while(pcur->next != pcur)//当链表只有最后一个节点且指向它自己时,循环结束{if(count == m){//销毁pcur节点,首先prev改变指向prev->next = pcur->next;free(pcur);//此时pcur是野指针pcur = prev->next;count = 1;}else{//此时不需要销毁节点(因为报数不是m,不需要销毁)prev = pcur;pcur = pcur->next;count++;}}//此时剩下的一个节点就是要返回的节点里的值return pcur->val;
}1、末尾return之前为了养成良好的代码习惯,可以先把pcur原来的值val存储下来,然后将pcur节点释放掉。
2、创建环形链表时要返回链表的 ptail 尾节点。
return 头节点还是尾节点,要看需要如何使用该链表。首先phead报数为1,然后phead的后一个节点指针 ptail (这个过程需要用到ptail)需要走到phead的前面。按照这个过程,则需要返回ptail。
六、力扣--02.04 面试题:分割链表
题目描述:给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。你不需要 保留 每个分区中各节点的初始相对位置。

注意这不是排序,而是分割链表,不需要保证 x 两边节点的相对位置。
思路1:在原链表上进行修改。若pcur节点的值小于x,只需继续往前遍历;若pcur节点的值大于或者等于x,尾插在原链表后面(newPtail记录新的尾节点的位置,后续尾插在newPtail位置进行),删除旧节点(需要 prev指针),直到遇到尾节点ptail,循环结束。 分析过程如手写图:

思路2:在带头新链表(newHead和newTail)上进行修改。若pcur节点的值小于x,节点头插在新链表中;若pcur节点的值大于或者等于x,将节点尾插在新链表中;哨兵位不能动。顺序不太一样,但是题目说明可以不用保留相对位置。分析过程如手写图:

思路3:创建两个新链表大链表(greaterHead和greaterTail)和小链表(lessHead和额lessTail)。 小于x的节点就尾插入小链表,大于等于x的节点就尾插入大链表中。然后将小链表的尾节点和大链表的首尾相连,合并小链表和大链表。详细分析过程如下手写图:

超出时间限制报错的代码如下:
//*************超出时间限制的代码:***************//typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x){if(head == NULL){return head;}//创建两个带头链表:ListNode* lessHead,*lessTail;ListNode* greaterHead,*greaterTail;//创建哨兵位 lessHead = lessTail = (ListNode*)malloc(sizeof(ListNode));greaterHead = greaterTail = (ListNode*)malloc(sizeof(ListNode)); //遍历原链表,将原链表中的节点尾插到大小链表中ListNode * pcur = head;//用来遍历while(pcur)//pcur为空,遍历结束{if(pcur->val < x)//尾插在小链表中{//尾插到小链表中lessTail->next = pcur;lessTail = lessTail->next;//尾节点在改变}else//尾插在大链表中{greaterTail->next = pcur;greaterTail = greaterTail->next;//尾节点在改变}pcur = pcur->next;//原链表也要继续遍历}//小链表的尾节点和大链表的第一个有效的节点首尾相连lessTail->next = greaterHead->next;//大链表的第一个有效节点:greaterHead->next//从 ,返回之前动态申请的空间还需要释放掉ListNode* ret = lessHead ->next;//销毁之前先存储free(lessHead);free(greaterHead);lessHead = greaterHead = NULL;//置空return ret;
} 上面的代码运行结果:

修改后的代码(仍然报错):
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x){if(head == NULL){return head;}//创建两个带头链表:ListNode* lessHead,*lessTail;ListNode* greaterHead,*greaterTail;//创建哨兵位 lessHead = lessTail = (ListNode*)malloc(sizeof(ListNode));greaterHead = greaterTail = (ListNode*)malloc(sizeof(ListNode)); //遍历原链表,将原链表中的节点尾插到大小链表中ListNode * pcur = head;//用来遍历while(pcur)//pcur为空,遍历结束{if(pcur->val < x)//尾插在小链表中{//尾插到小链表中lessTail->next = pcur;lessTail = lessTail->next;//尾节点在改变}else//尾插在大链表中{greaterTail->next = pcur;greaterTail = greaterTail->next;//尾节点在改变}pcur = pcur->next;//原链表也要继续遍历}//小链表的尾节点和大链表的第一个有效的节点首尾相连lessTail->next = greaterHead->next;//大链表的第一个有效节点:greaterHead->next//增加一行:修改大链表的尾节点的next指针指向greaterTail->next = NULL;//如果不加这一行,代码会会出现死循环,超出时间限制//从 返回之前动态申请的空间还需要释放掉ListNode* ret = lessHead->next;//销毁之前先存储free(lessHead);free(greaterHead);lessHead = lessHead = NULL;//置空return ret;
} 还要注意判断链表是否为空的情况:如果链表(head)为空,pcur也为空,不能进入while循环,也就不能进行循环中的各项操作 。来到while循环的外面,大小链表的首尾节点均为空,仍然指向的是初始时的哨兵位。(增加if(head == NULL){ } 这一段判断代码)
运行上面的代码,又出现以下错误:

画图分析报错原因:

最终版本的正确的代码如下:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x){if(head == NULL){return head;}//创建两个带头链表:ListNode* lessHead,*lessTail;ListNode* greaterHead,*greaterTail;//创建哨兵位 lessHead = lessTail = (ListNode*)malloc(sizeof(ListNode));greaterHead = greaterTail = (ListNode*)malloc(sizeof(ListNode)); //遍历原链表,将原链表中的节点尾插到大小链表中ListNode * pcur = head;//用来遍历while(pcur)//pcur为空,遍历结束{if(pcur->val < x)//尾插在小链表中{//尾插到小链表中lessTail->next = pcur;lessTail = lessTail->next;//尾节点在改变}else//尾插在大链表中{greaterTail->next = pcur;greaterTail = greaterTail->next;//尾节点在改变}pcur = pcur->next;//原链表也要继续遍历}//增加一行:修改大链表的尾节点的next指针指向greaterTail->next = NULL;//如果不加这一行,代码会会出现死循环,超出时间限制//小链表的尾节点和大链表的第一个有效的节点首尾相连lessTail->next = greaterHead->next;//大链表的第一个有效节点:greaterHead->next//从 返回之前动态申请的空间还需要释放掉ListNode* ret = lessHead->next;//销毁之前先存储free(lessHead);free(greaterHead);lessHead = lessHead = NULL;//置空return ret;
} 创作不易,喜欢的uu支持一下哦!

这篇关于DS:顺序表、单链表的相关OJ题训练(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







