本文主要是介绍【LLM 论文】背诵增强 LLM:Recitation-Augmented LM,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:Recitation-Augmented Language Models
⭐⭐⭐
ICLR 2023, Google Research, arXiv:2210.01296
Code:github.com/Edward-Sun/RECITE
文章目录
- 论文速读
论文速读
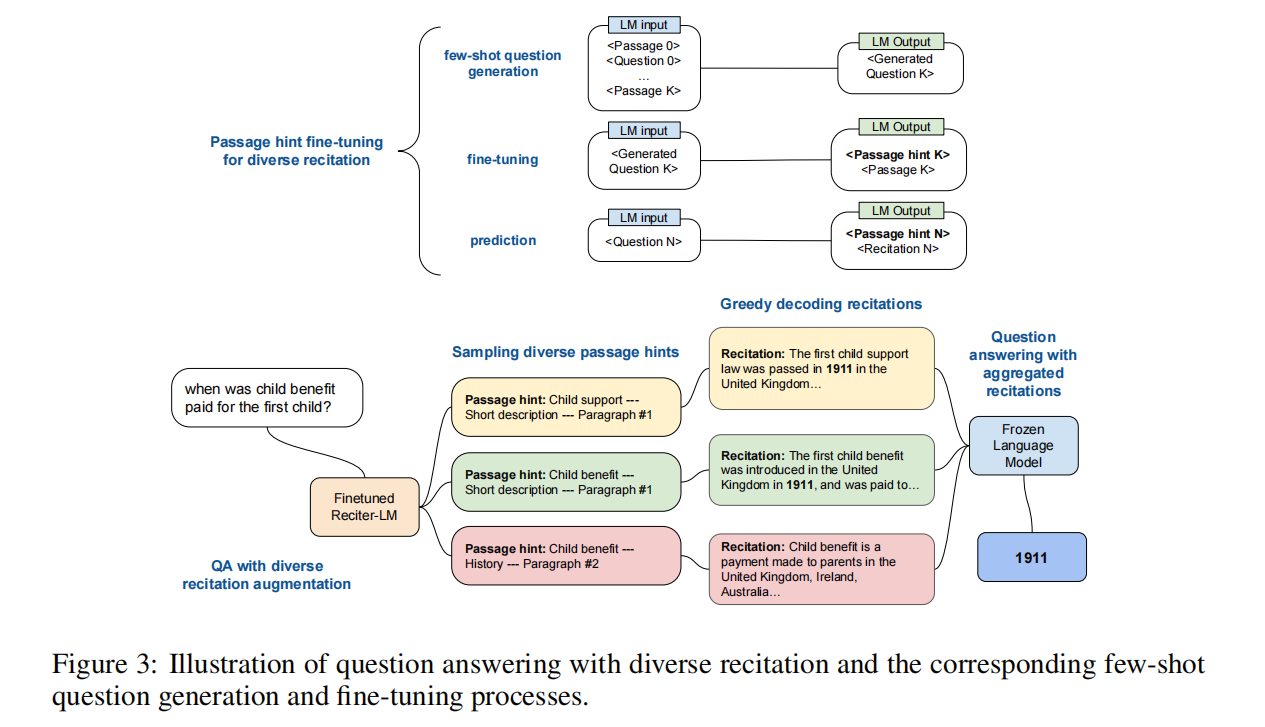
论文的整体思路还是挺简单的,就是让 LLM 面对一个 question,首先先背诵(recitation)一遍自己知道的相关段落,然后再回答答案,如下图所示(最右边的是 Recitation-augmented Generation):

实现的方式就是通过 in-context learning,为 LLM 提供几个带有 recitation 的 few-shot exemplars。
这种 two-step 的范式,将原来的知识密集型任务分解为了两个子任务:knowledge-recitation 和 task-execution,前者可以视为一种中间的知识获取步骤(从 LLM 的内部参数中)。
论文还举了一个例子来说明为什么这种方法可行。比如问题是“ π \pi π 的第十位小数是什么”,也许 LLM 的训练资料中没有关于这个问题的直接回答,但是它可能可以背出“ π \pi π 的前面的数字是 3.1415926535”,这样他就可以回答出答案是 5。
另外,论文还尝试与 self-consistency 和 multi-hop 多轮背诵的方法进行结合来解决更加复杂的问题,如下图:
这篇关于【LLM 论文】背诵增强 LLM:Recitation-Augmented LM的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

