本文主要是介绍Redis-三主三从高可用集群搭建,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
正式搭建之前,注意事项(坑)提前放到最开始,也可以出问题回来看,
(1)第二步中最好将配置文件中的logfile自定义一个目录,以便于在第五步中启动出错的时候迅速定位错误。
(2)第五步如果启动不起来,如果是我上一篇博客中的错误,可以将IP改成环回地址。
(3)第四步如果redis版本是3以上,需要升级ruby版本为2以上,否则会在第六步中报错。
如何升级网上有很多,但是有坑。
pool.sks-keyservers.net 已经被弃用,所以在获取密钥的时候,你需要使用:
gpg2 --keyserver hkp://keyserver.ubuntu.com --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB
升级完成,再去下载redis 4.0.0,


redis集群需要至少要三个master节点,我们这里搭建三个master节点,并且给每个master再搭建一个slave节点,总共6个redis节点,由于节点数较多,这里采用在一台机器上创建6个redis实例,并将这6个redis实例配置成集群模式,所以这里搭建的是伪集群模式,当然真正的分布式集群的配置方法几乎一样。
第一步:在/usr/local下创建文件夹redis-cluster,然后在其下面分别创建6个文件夾如下
(1)mkdir -p /usr/local/redis-cluster
(2)mkdir 8001、mkdir 8002、 mkdir 8003、 mkdir 8004、 mkdir 8005、 mkdir 8006
第二步:把之前的redis.con配置文件copy到8001下,修改如下內容:
(1)daemonize yes
(2)port 8001 (分别对每个机器的端口号进行设置)
(3)bind 192.168.0.60(必须要绑定当前机器的ip,这里方便redis集群定位机器,不绑定可能会出现循环查找集群节点机器的情况)
(4)dir /usr/local/redis-cluster/8001/(指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据。
(5) rluster-enabled yes(启动集群模式)
(6) cluster-config-file nodes-8001.conf (这里800x最好和port对应上)
(7)cluster-node-timeout 5000
(8) appendonly yes
第三步:把修改后的配置文件,分别 copy到各个文夹下,注意每个文件要修改第2、4、6项里的端口号,可以用批量替换:
:%s/源字符串/目的字符串/g
第四步:由于 redis集群需要使用 ruby命令,所以我们需要安装 ruby
yum install ruby
yum install rubygems
gem install redis --version 3.0.0
第五步:分别启动6个redis实例,然后检查是否启动成功
(1)/usr/local/redis/bin/redis-server /usr/local/redis-cluster/800*/redis.conf
(六个依次执行 星号替换成具体的1,2,3,4,5,6)
(2)ps -ef | grep redis 查看是否启动成功
第六步:在redis3的安装目录下执行 redis-trib.rb命令创建整个redis集群
(1) cd /usr/local/redis3/src
(2)/redis-trib.rb create --replicas 1 192.168.0.60:8001 192.168.0.60:8002 192.168.0.60:8003 192.168.0.60:8004 192.168.0.60:8005 192.168.0.60:8006
第七步:验证集群
(1)连接任意一个客户端即可:redis-cli -c -h -p (-c表示集群模式,指定ip地址和端口号)如:/usi/lpcal/redis/bin/redis-cli -c -h 192.168.0.60 -p 800*
(2)进行验证: cluster info(查看集群信息)、cluster nodes(查看节点列表)

(3)进行数据操作验证
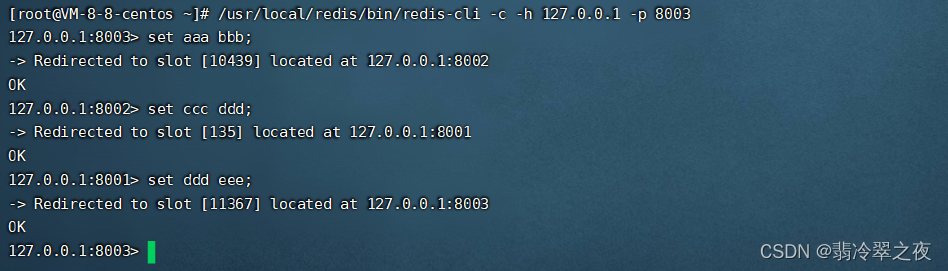
(4)关闭集群则需要逐个进行关闭,使用命令:
/usi/lpcal/redis/bin/redis-cli -c -h 192.168.0.60 -p 800* shutdown
PS:当出现集群无法启动时,删除临时的数据文件,再次重新启动每一个redis服务,然后重新构造集群环境。
这篇关于Redis-三主三从高可用集群搭建的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








