本文主要是介绍图解pix2pix(PatchGAN) ,pix2pixHD,vid2vid,SPADE,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
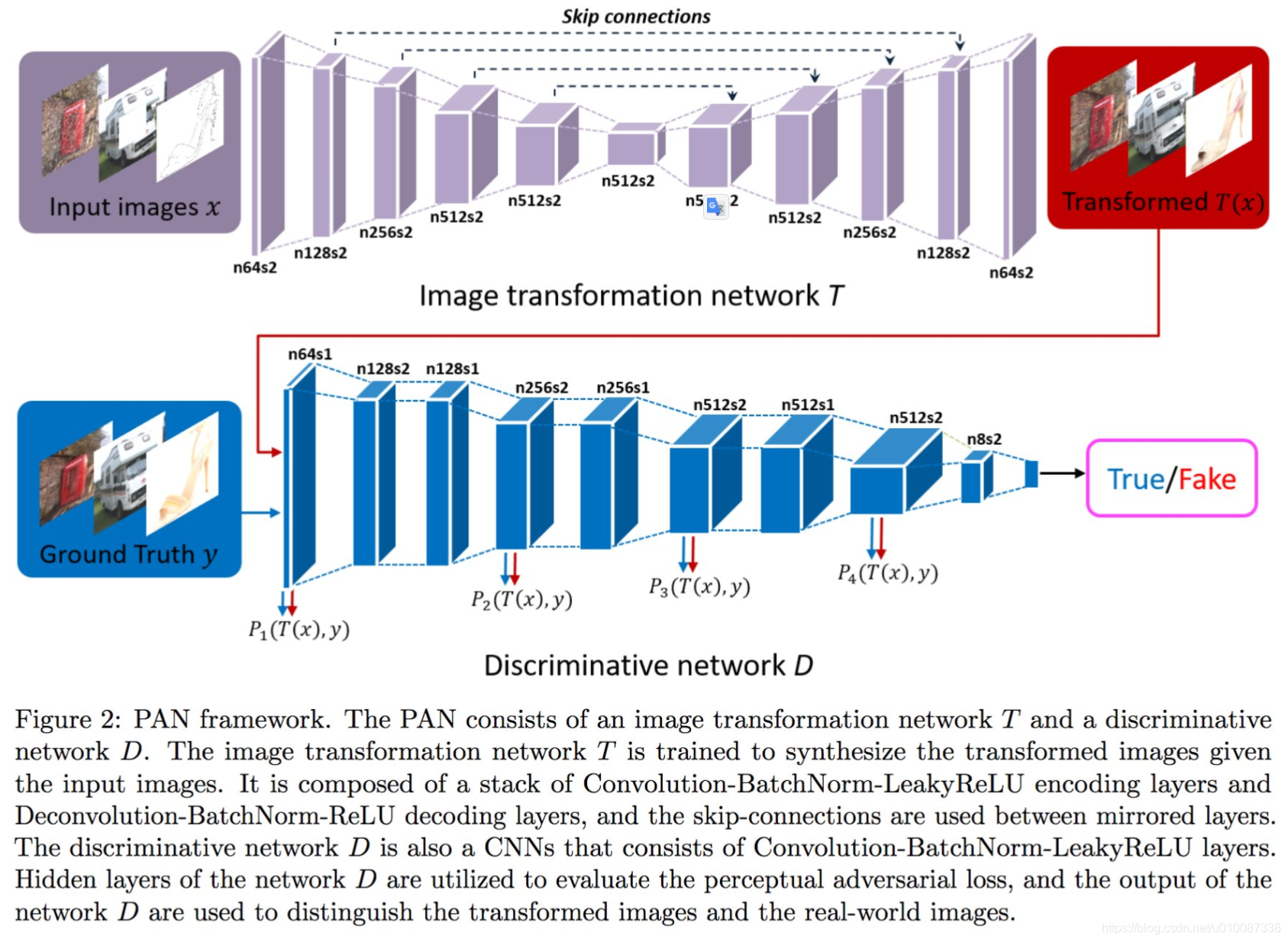
pix2pix(PatchGAN)的网络结构
优化object:

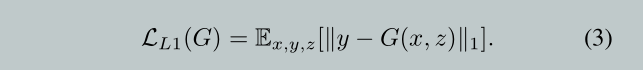
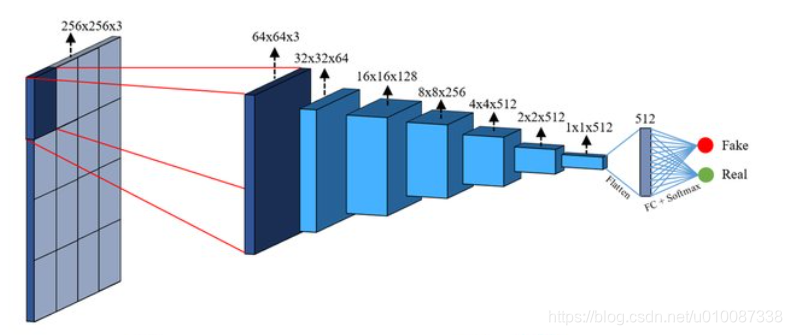
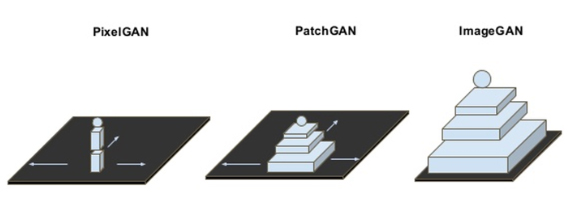
pix2pix的关键PatchGAN
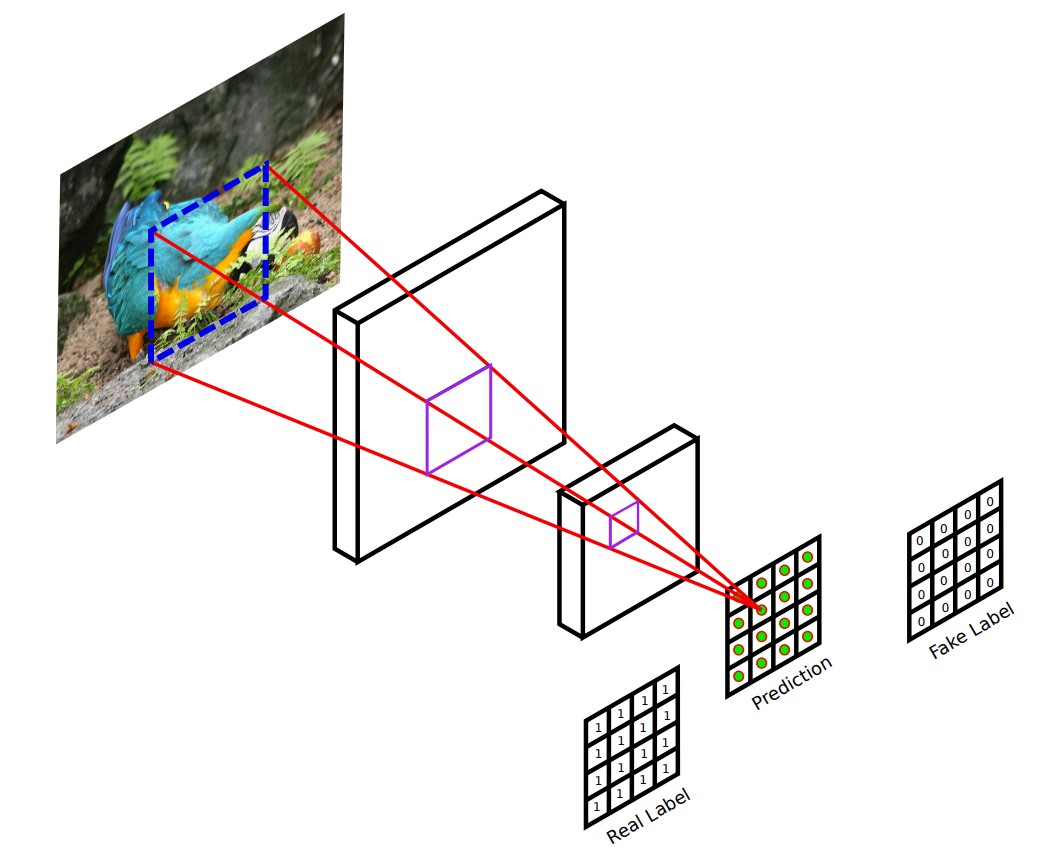
PatchGAN discriminator 专注于高频结构,它限制注意力于图片不同尺度局部的patches,
PatchGAN与 L1 正则化项结合,利用这两种方法来学习低频并锐化局部区域的细节。
This motivates restricting the PatchGAN discriminator to only
model high-frequency structure, relying on an L1 term to
force low-frequency correctness . In order to model
high-frequencies, it is sufficient to restrict our attention to
the structure in local image patches. Therefore, we design
a discriminator architecture – which we term a PatchGAN
– that only penalizes structure at the scale of patches. This
discriminator tries to classify if each N ×N patch in an im-
age is real or fake. We run this discriminator convolution-
ally across the image, averaging all responses to provide the
ultimate output of D.
pix2pix(PatchGAN)网络结构细节


pix2pixHD
顾名思义,是 pix2pix的高清改良版,怎么高清的哪?
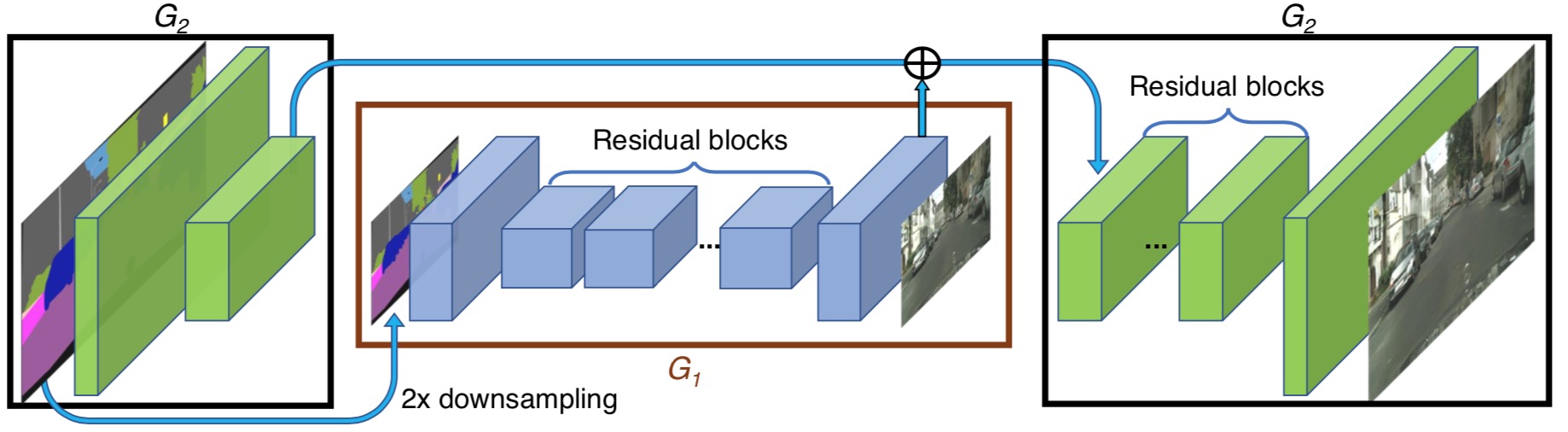
设计的生成器由两部分组成,G1和G2,其中G2又被割裂成两个部分。G1和pix2pix的生成器没有差别,就是一个end2end的U-Net结构。G2的左半部分提取特征,并和G1的输出层的前一层特征进行相加( element-wise sum)融合信息,把融合后的信息送入G2的后半部分输出高分辨率图像。
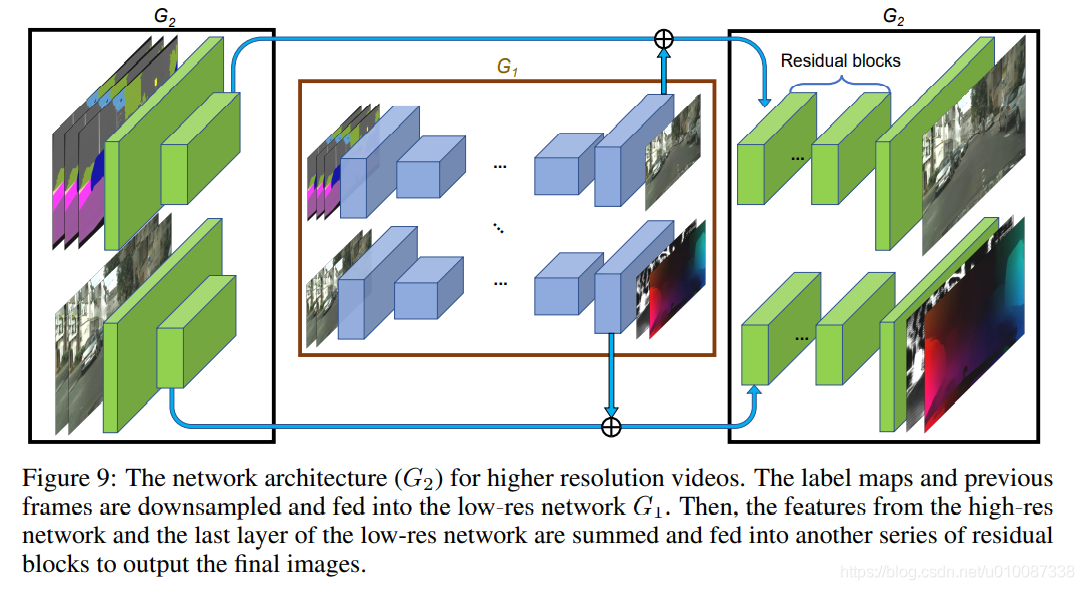
训练时,先用低分辨率图片训练一个residual network G1网络,完后G1首尾拼上G2,联合训练高分辨率图片。
判别器使用多尺度判别器,在三个不同的尺度上进行判别并对结果取平均。判别的三个尺度为:原图,原图的1/2降采样,原图的1/4降采样(实际做法为在不同尺度的特征图上进行判别,而非对原图进行降采样)。显然,越粗糙的尺度感受野越大,越关注全局一致性。
关于loss
- GAN loss:和pix2pix一样,使用PatchGAN。
- Feature matching loss:将生成的样本和Ground truth分别送入判别器提取特征,然后对特征做Element-wise loss
- Content loss:将生成的样本和Ground truth分别送入VGG16提取特征,然后对特征做Element-wise loss
- 使用Feature matching loss和Content loss计算特征的loss,而不是计算生成样本和Ground truth的MSE,主要在于MSE会造成生成的图像过度平滑,缺乏细节。Feature matching loss和Content loss只保证内容一致,细节则由GAN去学习。
关于多样性
不同于pix2pix实现生成多样性的方法(使用Dropout),这里采用了一个非常巧妙的办法,即学习一个条件(Condition)作为条件GAN的输入,不同的输入条件就得到了不同的输出,从而实现了多样化的输出,而且还是可编辑的。具体做法如下图:
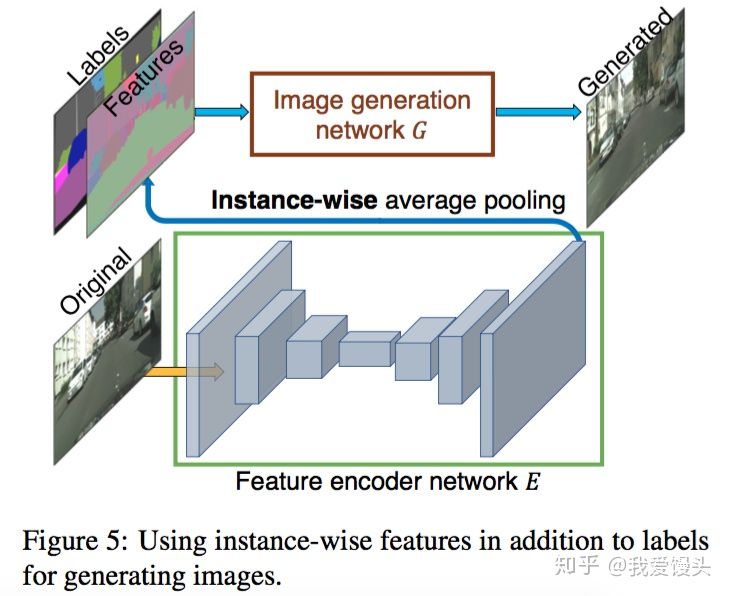
首先训练一个编码器 ,利用编码器提取原始图片的特征,然后根据Labels信息进行Average pooling,得到特征(上图的Features)。这个Features的每一类像素的值都代表了这类标签的信息。
vid2vid
Vid2Vid作为pix2pix, pix2pixHD的改进版本,重点解决了视频到视频转换过程中的前后帧不一致性问题。
视频生成的难点
GAN在图像生成领域虽然研究十分广泛,然而在视频生成领域却还存在许多问题。主要原因在于生成的视频很难保证前后帧的一致性,容易出现抖动。对于视频问题,最直观的想法便是加入前后帧的光流信息作为约束,Vid2Vid也不例外。由于Vid2Vid建立在pix2pixHD基础之上,加入时序约束。因此可以实现高分辨率视频生成
作者给出的方案
- 生成器加入光流约束
- 判别器加入光流信息
- 对前景、背景分别建模



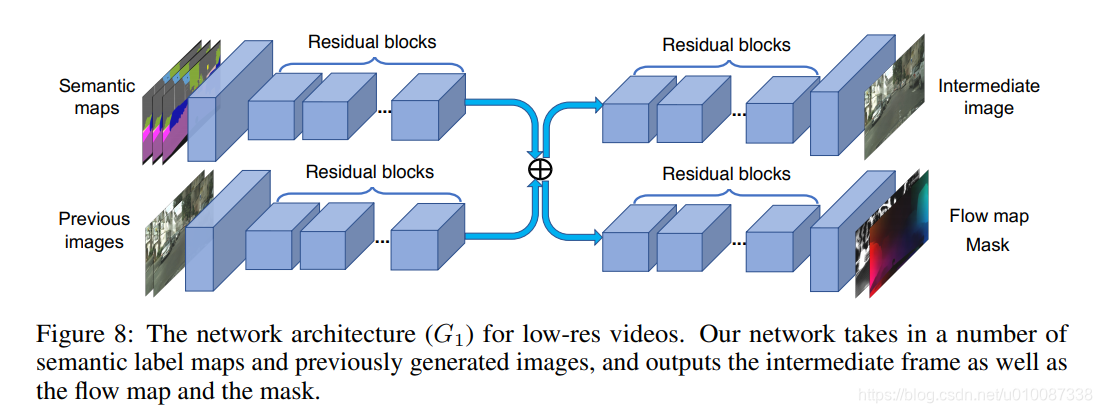
Learning objective function
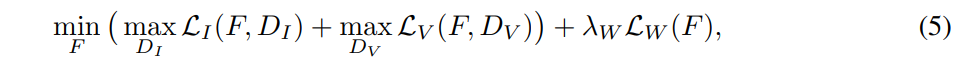
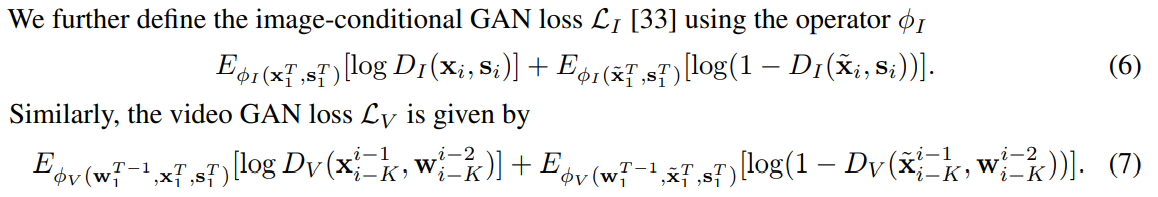
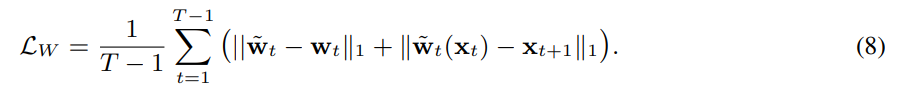
 对前景,背景分别建模
对前景,背景分别建模 
用SPADE替代pix2pixHD
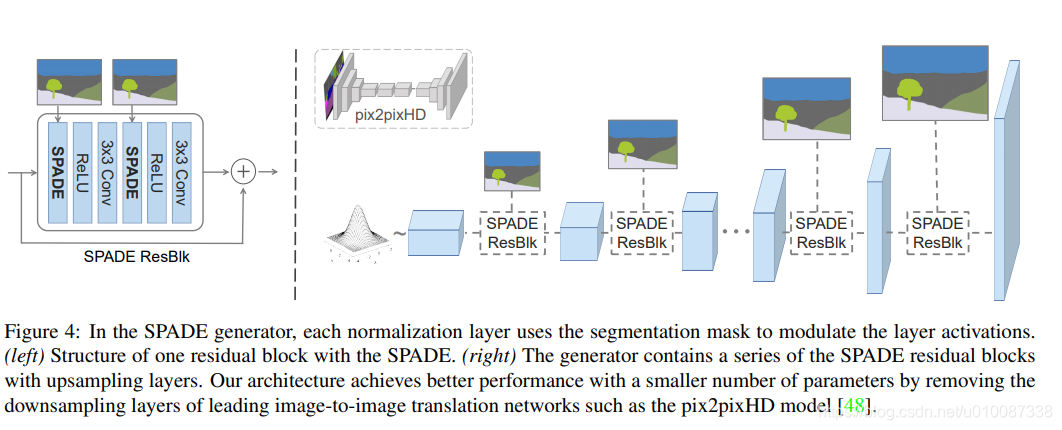
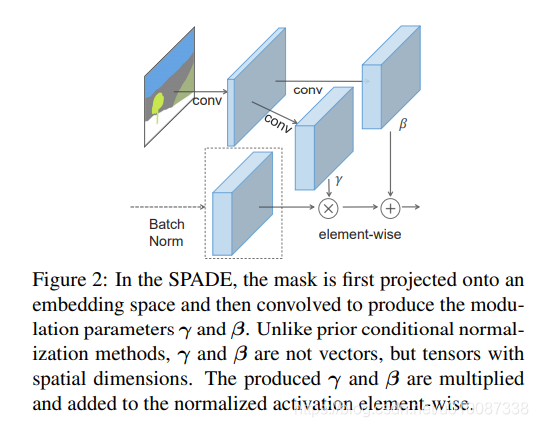
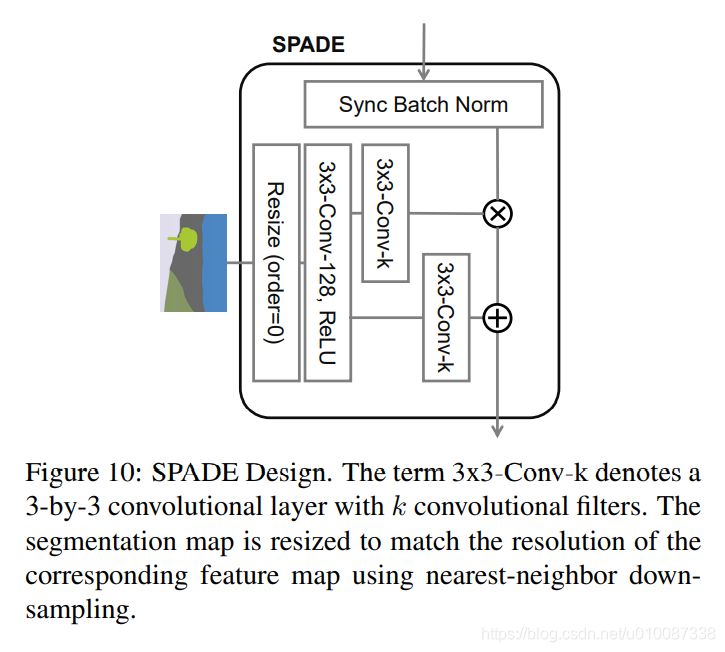
替代之后,效果明显,如下图:

注意:SPADE里面生成器G和判别器D里面的卷积层都用了Spectral Norm谱归一化,来加强训练的稳定性。(简而言之,Spectral Norm 约束了卷积层的 Lipschitz 常数,被用作稳定鉴别器网络训练的一种方式。在实践中,它非常奏效。)
SPADE的多模
对于相同的seg mask,只需要取不同的噪声输入,就会得到不同的输出,避免了同一个seg mask在监督学习下,被强行要求相同于不同target图片,从而造成模糊的问题。
SPADE的loss和D和pix2pixHD可以认为是一样的。
单单生成器G的不同,SPADE 为什么会比pix2pixHD效果好太多?
因为原始的语义输入,会被逐步的直接的调制进入生成图片的流水线,避免了被一些normalization 层wash away掉一些细节信息。
这篇关于图解pix2pix(PatchGAN) ,pix2pixHD,vid2vid,SPADE的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









