本文主要是介绍双塔模型模型结构、样本选择、训练方式、线上服务、模型更新,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
召回模型目的是快速选取用户可能感兴趣的物品,凡事用户可能感兴趣的都取回来 然后交给后续排序模型逐一甄别。
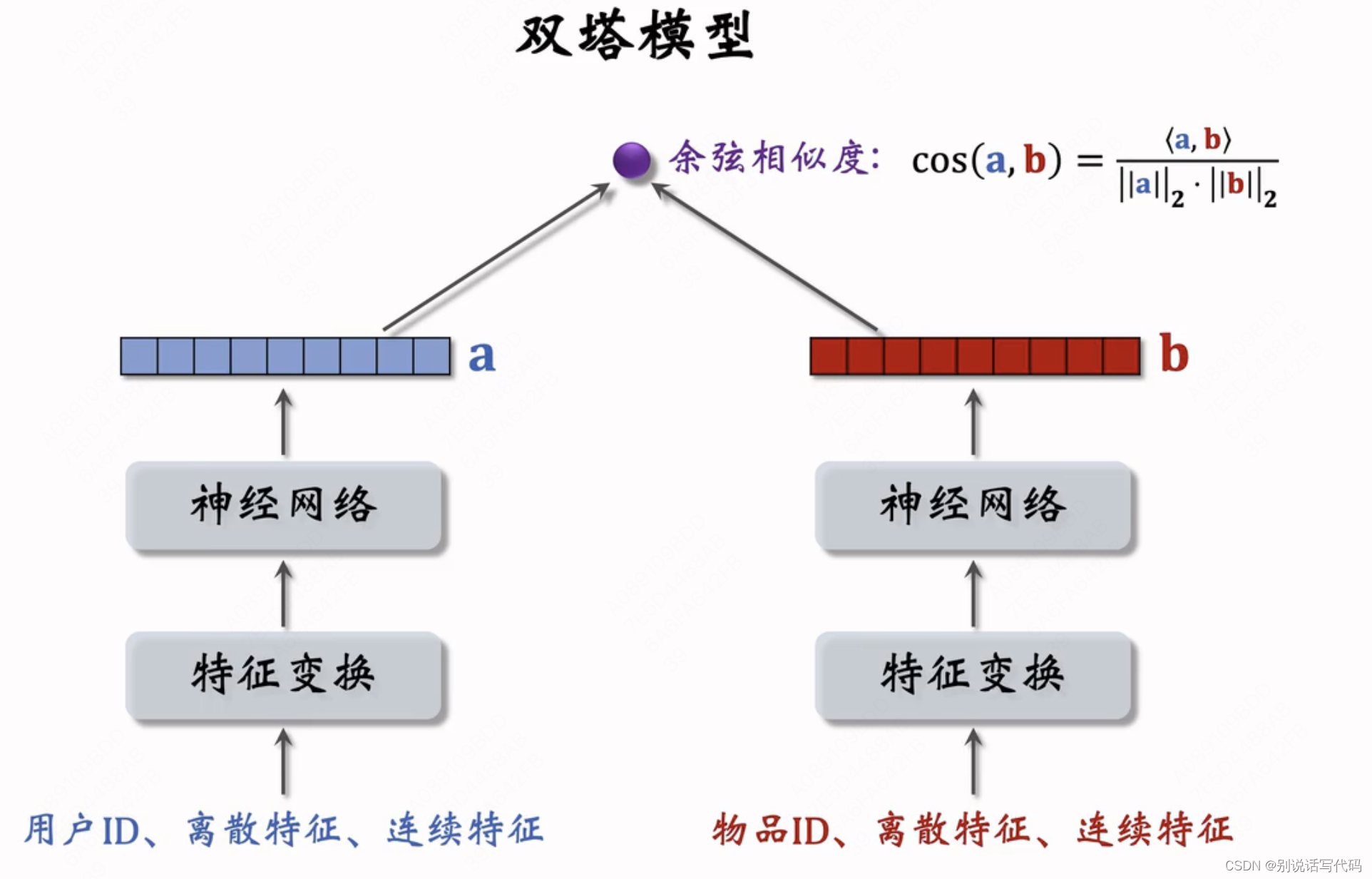
双塔模型结构
不止能使用id特征(能使用id之外的其他特征),用户侧能用画像等其他特征,包括离散特征和连续特征,物品侧除了id特征以外,还可以用更多其他特征,这是与矩阵补充、cf、swing等模型的区别。
双塔有一个用户塔都是用户特征,有一个物品塔,塔可以用DNN,DCN等结构,最后计算相似度(后期融合)。
双塔模型的训练方式
- pointwise:独立看待每个正负样本,做简单二分类,正样本和负样本组成一个数据集,在数据集上做随机梯度下降训练双塔模型。
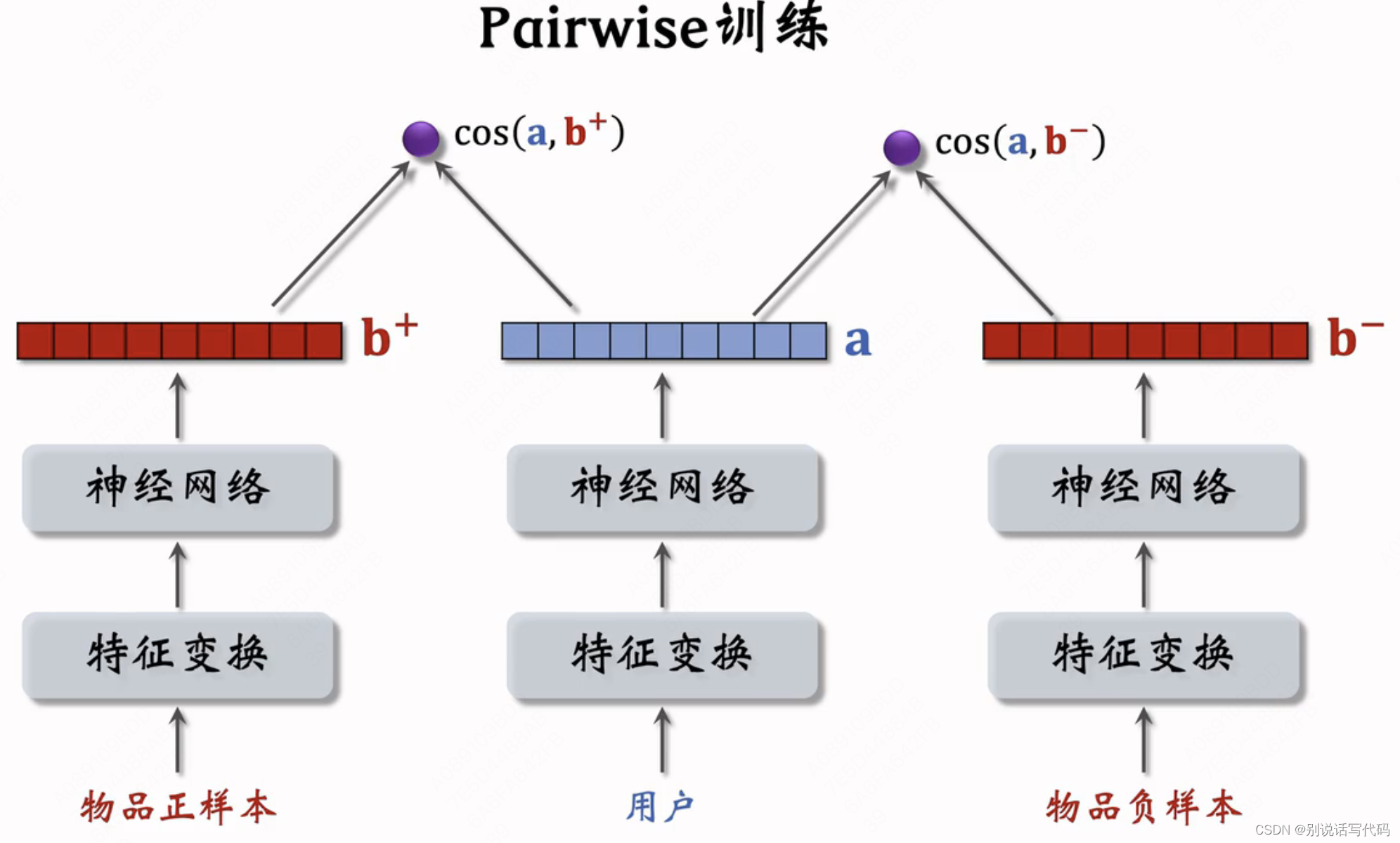
- pairwise:每次取一个正样本和负样本组成一个二元组,用triplet loss
- listwise:每次取一个正样本 和多个负样本组成一个list,训练方式类似于多元分类
pointwise:把召回看做二分类任务,对正样本鼓励cos(a,b)相似度接近+1,对负样本鼓励cos(a,b)相似度接近-1。把正负样本比例控制在1:2~1:3,这是经验值。
pairwise:基本想法是让用户跟正样本相似度尽量大,用户跟负样本相似度尽量小,也就是cos(a,b+)大于cos(a,b-)
- 如果cos(a,b+)大于cos(a,b-)+m,则没有损失,否则损失为cos(a,b-)+m-cos(a,b+)
- Triplet hinge loss: L(a,b+,b-)=max(0,cos(a,b-)+m-cos(a,b+)),m为超参数
- Triplet logistic loss:L(a,b+,b-)=log(1+exp[σ(cos(a,b-)-cos(a,b+))])
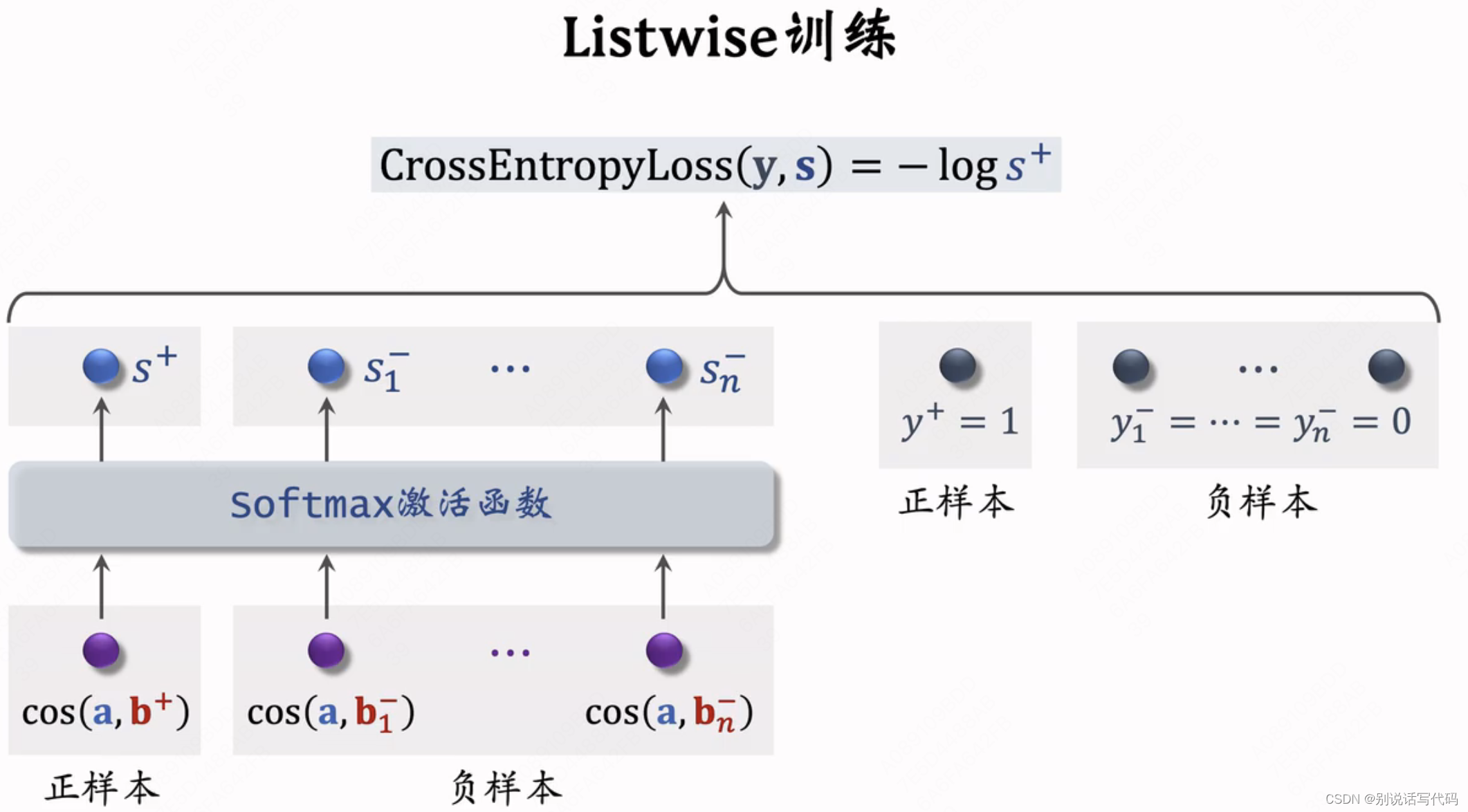
listwise:一条数据包含用户特征记作a,一条正样本记作b+,n个负样本b1-,...,bn-,鼓励cos(a,b+)尽量大,cos(a,bn-)尽量小
- 用softmax激活函数输出n+1个分数(1个正样本和n个负样本),正样本最好都接近1,负样本最好都接近0,用交叉熵最大化用户与正样本相似度,最小化用户与负样本相似度
下图这中是粗排的双塔模型,从千级别选出百级别计算量不会太大。这种是前期融合,如果要用这种结构,就意味着吧所有物品特征都要扫一遍才能计算相似度,无法用最近邻近似查找计算,在召回阶段是做不到的,召回只能用后期融合方式。

双塔模型的样本选择
双塔模型选对正负样本作用大于改进模型结构。
- 正样本:曝光且有点击的用户-物品二元组(用户对物品感兴趣)
- 问题:少部分物品占据大部分点击,导致正样本大多是热门物品,这样让热门物品更热,冷门物品更冷
- 解决方案:降采样热门物品(以一定概率排期正样本,抛弃概率与点击次数正相关),过采样冷门物品(一个物品多采几次)
- 负样本:召回模块是从几亿物品选出几千个,曝光的物品占极少数。应该召排每个链路选负样本。
- 简单负样本(分类准确率高):
- 未被召回的,大概率是用户不感兴趣的,所以直接在全集物品里随机抽负样本
- 均匀抽样:对冷门物品不公平。正样本大多是热门物品,负样本大多是冷门物品。
- 非均匀抽样:目的是打压热门物品,负样本抽样概率与热门程度(点击次数)正相关,一般用 抽样概率正比与(点击次数)^0.75次方
- batch内负样本:一个batch有n个正样本,有n-1个负样本,这个batch内共有n(n-1)个负样本,这些都是简单负样本,对第一个用户来说不喜欢第二个样本,相当于从全局随机抽样的
- 问题:一个batch内物品出现概率正比于点击次数,抽样概率本应是正比于(点击次数)^0.75次方,这里实际是1次,这里热门物品成为负样本概率过大,会被打压太狠
- 解决方案:参考youtube论文,物品i被抽到的概率正比于点击次数,双塔预估用户对物品的兴趣cos(a,bi),在训练时调整为cos(a,bi)-logpi,这样能纠偏,在线上推断时不用-logpi
- 未被召回的,大概率是用户不感兴趣的,所以直接在全集物品里随机抽负样本

- 困难负样本:被排序淘汰的物品,比如物品被召回但被粗排淘汰,召回2000物品粗排值出来200个,有1800个被淘汰 ,多少跟用户兴趣有些相关性,但是没有经过粗排,说明兴趣不够强。
- 被粗排淘汰的物品(比较困难,容易分错)
- 被精排淘汰的物品(非常困哪,更容易分错):比如精排对200个物品打分,排名在后150的 都算负样本,能经过粗排进入精排 已经符合比较用户兴趣了,但是未必是用户最感兴趣的
- 训练数据:混合几种负样本,50%是全体物品(简单负样本),50%是没通过排序的的物品(困难负样本)
- 简单负样本(分类准确率高):
- 常见错误:
- 召回阶段把曝光未点击做负样本:召回模型目的是快速选取用户可能感兴趣的物品,凡事用户可能感兴趣的都取回来 然后交给后续排序模型逐一甄别,召回模块的目标是区分用户不感兴趣的物品和可能感兴趣的物品,而不是区分比较感兴趣和非常感兴趣的物品。曝光未点的样本已经是精排选出来非常匹配 用户的兴趣点了,每次展示的几十物品不可能都点,没点不能说明不感兴趣,可能是对别的更感兴趣,也可能是感兴趣碰巧未点。曝光过得物品已经算是非常匹配了,甚至可以拿来做召回的正样本了,不应该把曝光未点做召回负样本。
- 全体物品easy:绝大多数是用户根本不感兴趣的
- 被排序淘汰hard:用户可能感兴趣,但是没有非常感兴趣
- 曝光未点击(没用):用户可能感兴趣但碰巧没点,一般训练排序模型作为负样本

- 召回阶段把曝光未点击做负样本:召回模型目的是快速选取用户可能感兴趣的物品,凡事用户可能感兴趣的都取回来 然后交给后续排序模型逐一甄别,召回模块的目标是区分用户不感兴趣的物品和可能感兴趣的物品,而不是区分比较感兴趣和非常感兴趣的物品。曝光未点的样本已经是精排选出来非常匹配 用户的兴趣点了,每次展示的几十物品不可能都点,没点不能说明不感兴趣,可能是对别的更感兴趣,也可能是感兴趣碰巧未点。曝光过得物品已经算是非常匹配了,甚至可以拿来做召回的正样本了,不应该把曝光未点做召回负样本。
双塔模型线上服务
- 物品塔:模型训练好后,把物品id和物品向量二元组保存到向量数据库,有多少物品就有多少个向量, 线上用最近邻查找。每天离线t+1更新
- 用户塔:模型训练好后用户来后在线更新,然后再去索引中检索最相似的topk个物品(用的是最近邻查找)。建索引就是把向量空间划分为很多区域,每个区域用一个中心向量表示,这样可以加速最近邻查找。
- 为啥用户塔现算,物品塔离线存:每次只用到1个物品向量,每个用户要对全量物品计算,线上无法承载;同时用户兴趣是时刻变化的,而物品特征相对稳定
- 线上整个召回:双塔召回作为其中一条召回通道,结果与itemcf,swing,mind等其他召回融合进入粗排
模型更新
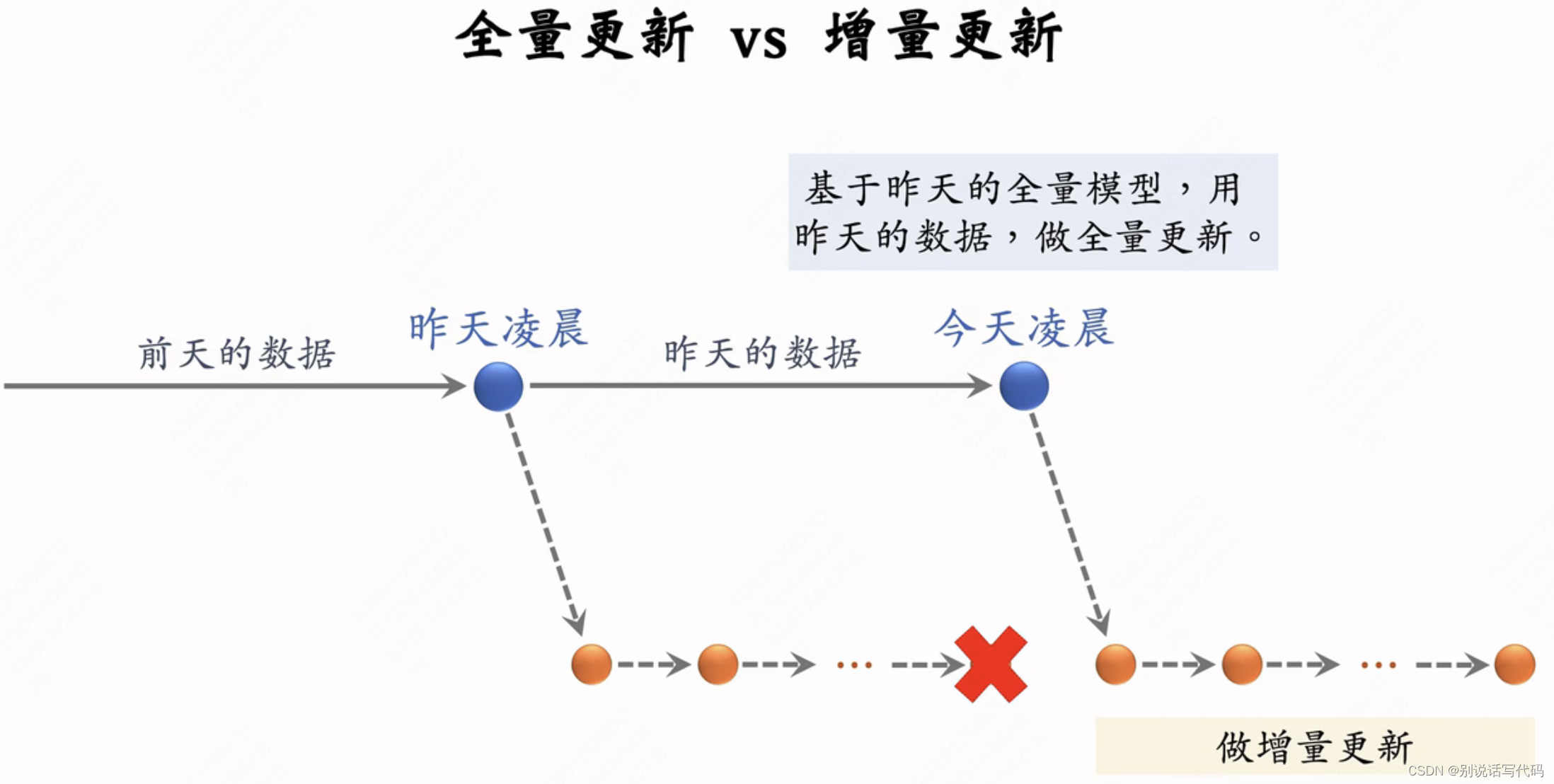
- 全量更新:在昨天训练的模型参数基础上,今天凌晨用昨天全天数据训练模型,训练1个epoch,每条数据只过一遍,然后发布新的用户塔神经网络和物品向量,供线上召回使用。对数据流、系统要求比较低
- 增量更新:做online learning更新模型参数,因为用户兴趣会发生变化,比如用户早上、中午、晚上的兴趣是不一样的。要做到小时级更新,实时收集线上数据,实时做流式处理并成圣TFRecod文件。对模型做online learning梯度下降,增量更新ID Embedding参数(不更新网络其他部分参数),算好之后发布用户embedding,供用户塔在线计算用户向量。也就是过几十分钟后用户向量会更新(捕获了最新的用户兴趣)
- 问题:能否只做增量更新,不做全量更新?
-
效果不好,只看小时数据是有偏的,中午和傍晚数据不一致,和全天差距很大。全量训练时要shuffle一天数据,做1epoch训练,增量更新从早到晚做1epoch训练。增量更新有时间顺序捕捉用户兴趣。全量训练模型更好,而增量训练可以实时捕捉用户兴趣。
-
随机打乱shuffle优于按顺序排列数据,全量更新优于增量更新。
-
本文学习内容参考:王树森课程
这篇关于双塔模型模型结构、样本选择、训练方式、线上服务、模型更新的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




