本文主要是介绍_compile(pattern, flags).findall(string) TypeError: cannot use a string pattern on a bytes-like,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在自学python,做的一个图片爬虫,却出现一些错误,特此总结下来,为了别人遇到同样错误时可以快速解决同样的问题。
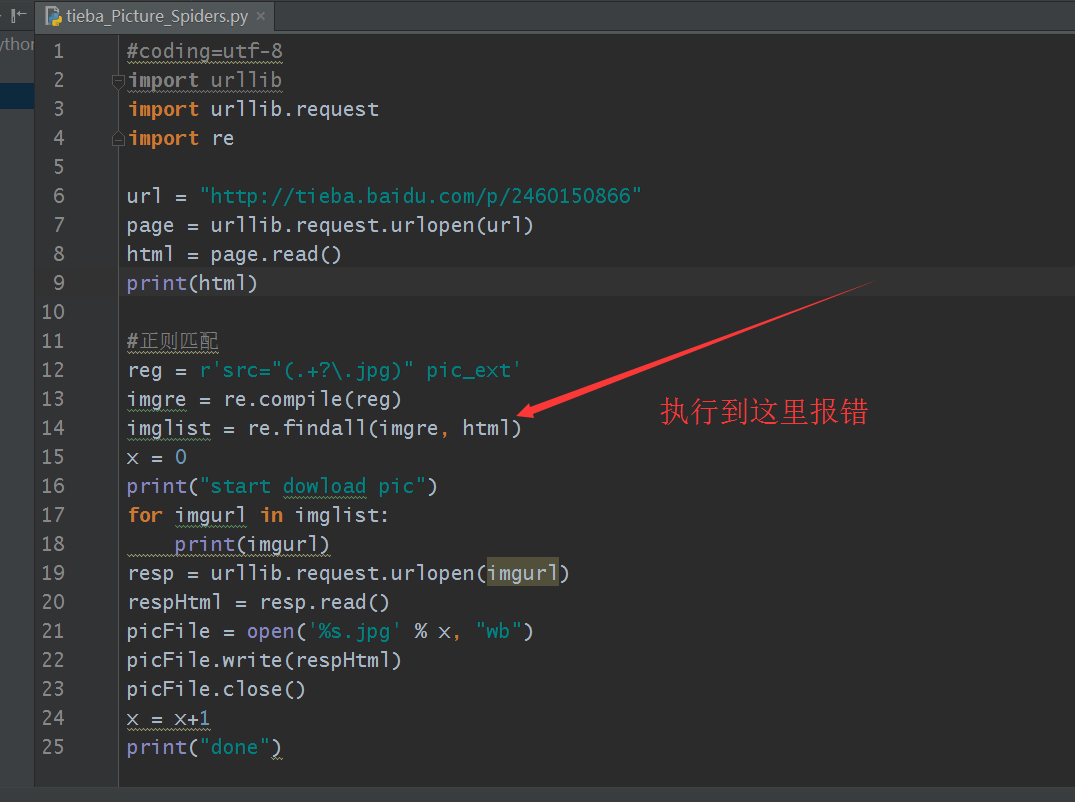
#coding=utf-8
import urllib
import urllib.request
import reurl = "http://tieba.baidu.com/p/2460150866"
page = urllib.request.urlopen(url)
html = page.read()
print(html) #正则匹配
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre, html)
x = 0
print("start dowload pic")
for imgurl in imglist:print(imgurl)resp = urllib.request.urlopen(imgurl)respHtml = resp.read()picFile = open('%s.jpg' % x, "wb")picFile.write(respHtml)picFile.close()x = x+1
print("done")
报错信息如下:
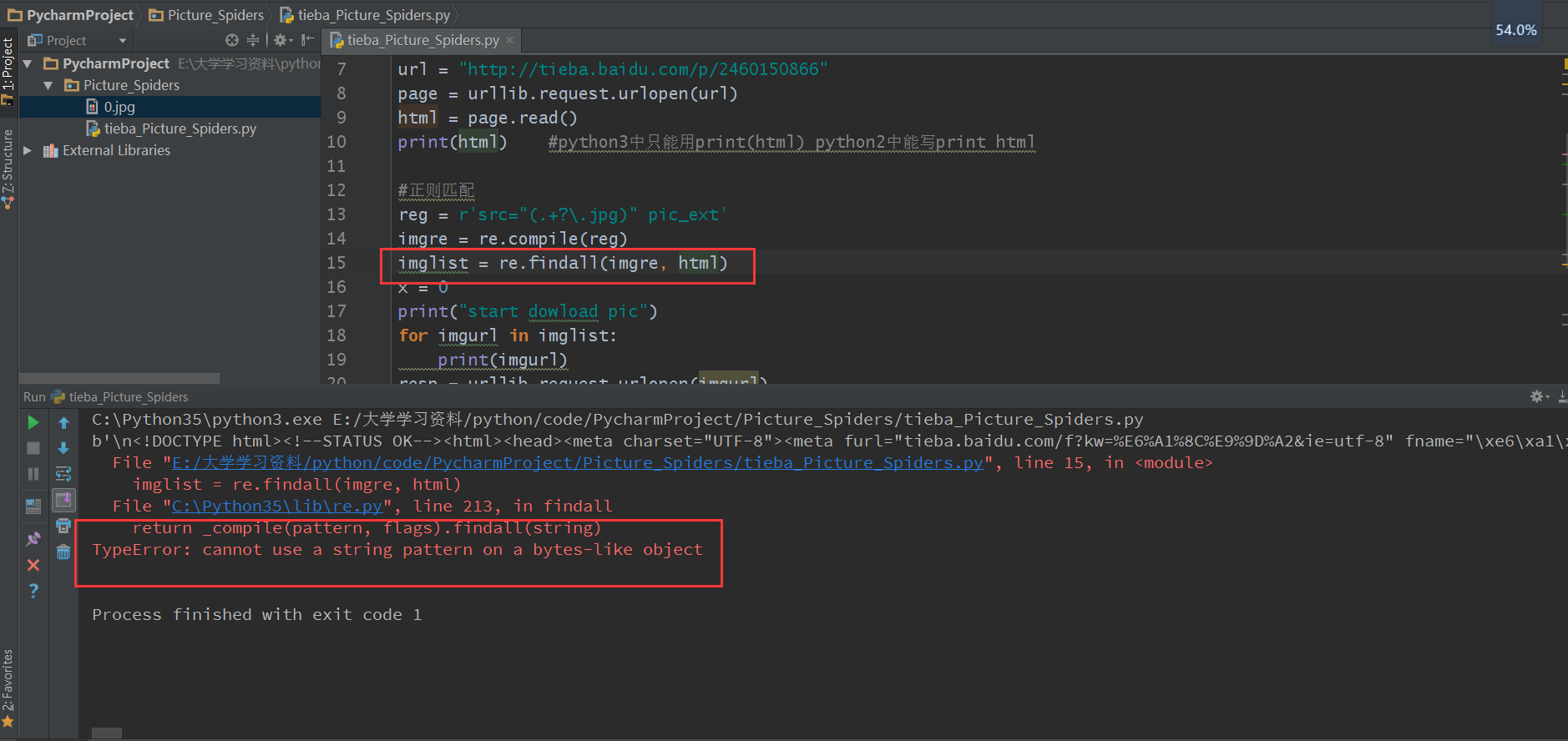
File “C:\Python35\lib\re.py”, line 213, in findall
return _compile(pattern, flags).findall(string)
TypeError: cannot use a string pattern on a bytes-like object
出错的主要原因是因为:
TypeError: can’t use a string pattern on a bytes-like object.
html用decode(‘utf-8’)进行解码,由bytes变成string。
py3的urlopen返回的不是string是bytes。
解决方法是:把’html’类型调整一下:html.decode(‘utf-8’)
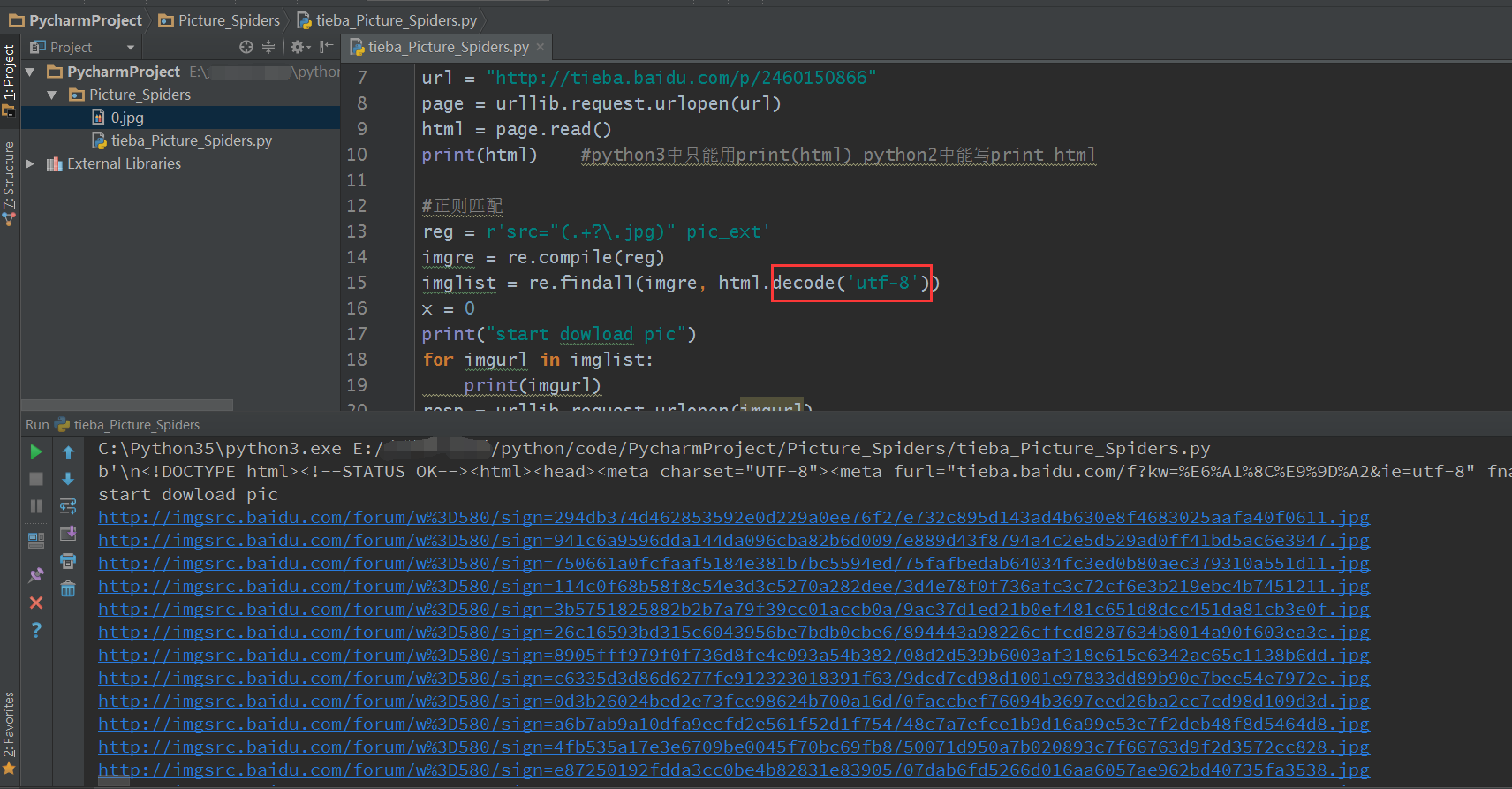
正确代码如下:
#coding=utf-8
import urllib
#在python3.3里面,用urllib.request代替urllib2
import urllib.request
import reurl = "http://tieba.baidu.com/p/2460150866"
page = urllib.request.urlopen(url)
html = page.read()
print(html) #python3中只能用print(html) python2中能写print html#正则匹配
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre, html.decode('utf-8'))
x = 0
print("start dowload pic")
for imgurl in imglist:print(imgurl)resp = urllib.request.urlopen(imgurl)respHtml = resp.read()picFile = open('%s.jpg' % x, "wb")picFile.write(respHtml)picFile.close()x = x+1
print("done")这篇关于_compile(pattern, flags).findall(string) TypeError: cannot use a string pattern on a bytes-like的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





