findall专题

Python 正则表达式(高级用法)- search、findall、sub 、split
仅供学习,转载请注明出处 re模块的高级用法 search 需求:匹配胖子老板说出的香烟价格 In [95]: re.search(r"\d+","胖子老板:一包蓝利群17元啦").group() Out[95]: '17'In [96]: findall 前面寻找smoke的故事中,我用来最终解决胖子老板的smoke次数寻找问题

正则表达式match和findall的区别
在python中match和findall两个方法都可用于寻找字符串中匹配的字符串。其中match方法根据正则模式,从源字符的第一个字符开始匹配,如果寻找到了相应匹配模式,则返回相应结果,例如: import re s='abcd'; p = re.compile('abcd'); m = p.match(s); print m.group(); 这时程序会输出:abcd 如果把源
_compile(pattern, flags).findall(string) TypeError: cannot use a string pattern on a bytes-like
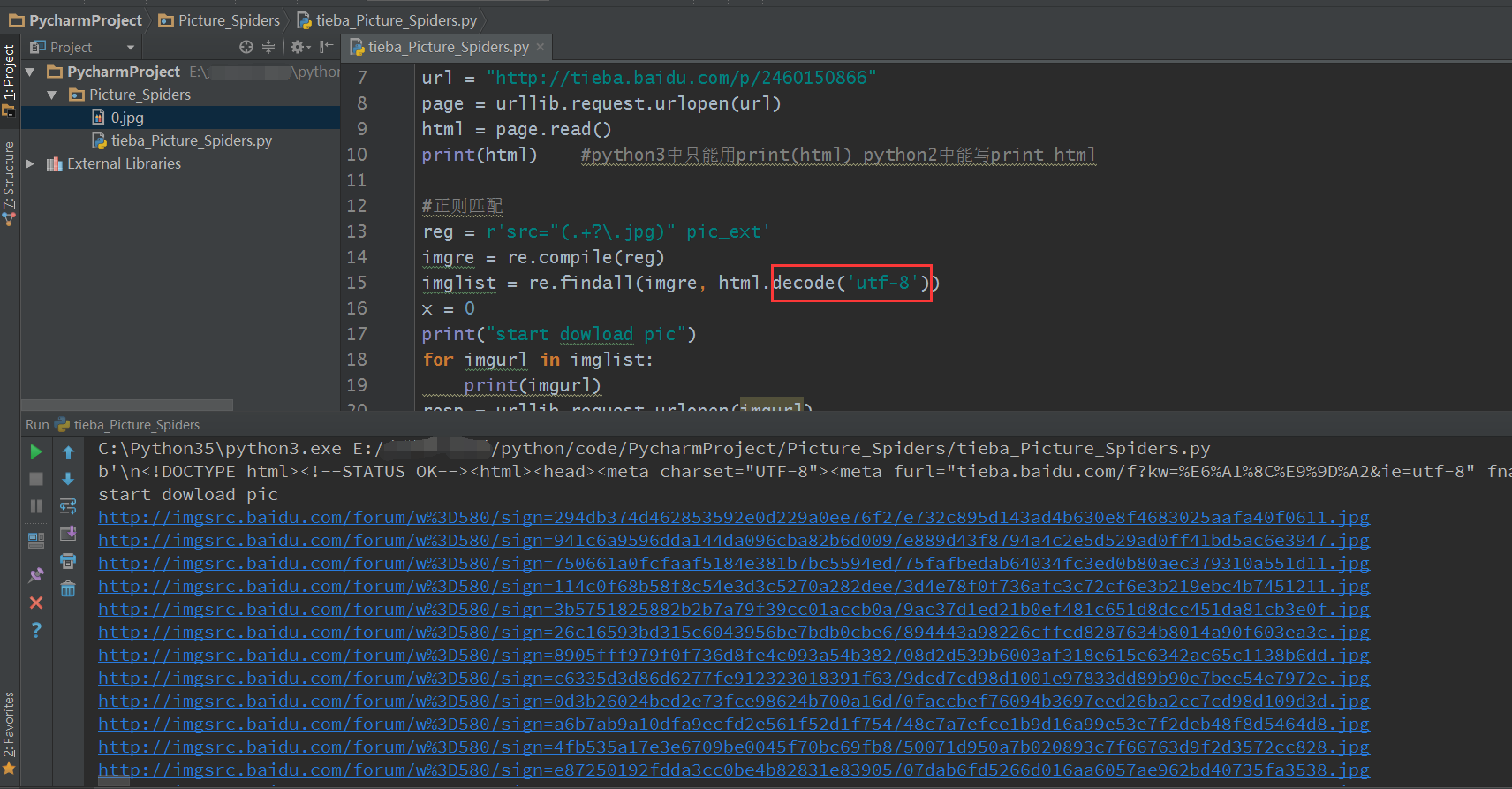
最近在自学python,做的一个图片爬虫,却出现一些错误,特此总结下来,为了别人遇到同样错误时可以快速解决同样的问题。 #coding=utf-8import urllibimport urllib.requestimport reurl = "http://tieba.baidu.com/p/2460150866"page = urllib.request.urlopen(url)
Android WebView findAll API Bug
Android系统开发过的大家不管是framework以上还是native,大家都会遇到过不同Android版本差异带来的问题,Deprecate这个词framework层接触比较多童鞋会见得相当多,甚至一些api还会有一些bug. 本人总结Android开发针对版本不同问题的个人心得: 1.首先查看官方文档和framework源码,这里推荐一个网址在线查看android各个系统版

Python - Regex 之 findall
谨记:我只提取我需要的字符串,其它的扔掉。扫描方向 从左至右 正则 re.findall 的简单用法(返回string中所有与pattern相匹配的全部字串,返回形式为数组) >>> regular_v1 = re.findall(r"docs","https://docs.python.org/3/whatsnew/3.6.html")>>> print (regular_v1)['d
re.findall()从html去除带有\n数据不换行
原始数据: {"errno":0,"data":{"...,"key":"-----BEGIN PUBLIC KEY-----\nMIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDvEpk7iB6BF8ZLXG0vSMr7Qedl\nB9Q4c9qrqiNziUt3RokRkr7pHxWlelQPC3JIMs+UvMkabTkDNE4pvx\/DkFWEMzzu\nH
re.findall-Python字符过滤(前程无忧薪资字符过滤)
import rere.findall 过滤 万/年 '40-80万/年'if re.findall(r'(.*)\-(.*)\万\/\年', i):s = re.findall(r'(.*)\-(.*)\万\/\年', i)[0]print(s)print(s[0])('40', '80')40 前程无忧薪资字符过滤 abb = ['1-1.6万', '1.5-2万', '2-

Spring JPA使用findAll方法查出的数据跟数据库里存储的不一样
今天遇到个有意思的问题:findAll查出的数据竟然很数据库里存储的数据不一样 本来数据库里有全国所有省份的数据但是查出来只有河南和浙江的数据条数一样,数据大量重复 经过分析是Entity的ID字段在数据库中并不是唯一的,而且重复的很多,后来改成联合主键就正常了。 选ID的时候一定要确认是否是唯一的,因为JPA底层会根据这个ID判断俩个Entity是不是一样的。 以下是配置联合主键的代码:

re.findall()识别不了\n换行符的问题
今天小沅在处理数据的时候突然发现一个问题 在这样的顺序下print(qwe2)控制台打印的是[ ]空列表 结果经过翻阅各大神秘籍、各大神的观摩总结了一下: 原因: 1、我们在第二行利用了re.sub()把"<br/">替换成了\n换行符 2、re.findall()括号里的(.*?)非贪婪模式识别不了“\n”换行符,所以当我们打印qwe2的时候是个[]空

正则(re.findall) 抓取script中的数据
以某网站为例(政府性质),路由地址就不发了 1、网站数据如下 数据是动态加载,无法使用xpath标签解析 2、re.findall()抓取 import reimport jsonimport requests# 获取详情页def spider_test(pageid):url = "http://xxxxxxxxxxxxx/view?id=%s" % pageidheader
Python re.findall()中的正则表达式包含多个括号时的返回值——包含元组的列表
当re.findall()中的正则表达式包含多个括号时,返回值是一个列表,其中每个元素都是一个元组。这个元组的长度与正则表达式中括号的数量相同,元组中的每个元素都是与相应括号中的模式匹配的文本。 import re # 定义一个包含三个括号的正则表达式 pattern = r'(\d+)-(\w+)-(\d+)' text = '123-abc-456 789-def-1234' #
Python re.findall()和re.finditer()实现在字符串中查找所有匹配项的功能区别
re.findall() re.findall() 函数返回所有非重叠匹配的列表。它只包含匹配的子串,不包含任何关于匹配位置的信息。 import re text = "Hello, world! This is a test." pattern = r"\w+" # 匹配一个或多个单词字符 matches = re.findall(pattern, text) print(ma
re finditer和findall的区别
re.finditer 函数是 re.findall 函数的惰性版本,返回的不是列表,而是一个生成器,按需生成 re.MatchObject 实例。如果有很多匹配,re.finditer 函数能节省大量内存。 使用finditer版本: import reimport reprlibRE_WORD = re.compile('\w+')class Sentence:def __init__

软件测试|深入理解Python中的re.search()和re.findall()区别
前言 在Python中,正则表达式是一种强大的工具,用于在文本中查找、匹配和处理模式。re 模块提供了许多函数来处理正则表达式,其中 re.search()和 re.findall() 是常用的两个函数,用于在字符串中查找匹配的模式。本文将深入介绍这两个函数的用法,以及详细的使用示例。 re.search() 函数 re.search() 函数用于在字符串中查找匹配的第一个子串,并返回一
python re.compile()和findall()
compile(pattern[,flags] ) 根据包含正则表达式的字符串创建模式对象。 >>>help(re.compile)compile(pattern, flags=0)Compile a regular expression pattern, returning a pattern object. 通过help可以看到compile方法的介绍,返回一个pattern对象,但是却
Spring Data JPA 性能优化之 findAll
优化场景描述 当时是测试环境,进行一个列表的初始化分页查询,pageSize 为8(已经很小了),页面的数据项也很少,就那么几个信息,但是性能压测通过不了。 提出性能问题假设 事关性能问题,我们不妨大胆的假设: pageSize只有8,会不会是返回的数据包含的信息量太大,网络IO顶不住?接口会不会有第三方的调用,有等待延迟?接口内部的查询逻辑会不会过于复杂,需要多表且多次查询?数据库数据量

Idea中运行Maven/Gradle项目报错Invalid bound statement (not found): com.xx.dao.SysSettingMapper.findAll()
文章目录 前言1.Maven/Gradle默认的web目录结构 问题原因解决Maven中Gradle中 总结其它 前言 1.Maven/Gradle默认的web目录结构 若我们没有在pom.xml/build.gradle中显示设置resources/sourceSets,则Maven/Gradle默认的项目目录结构: srcmainjava // source 根
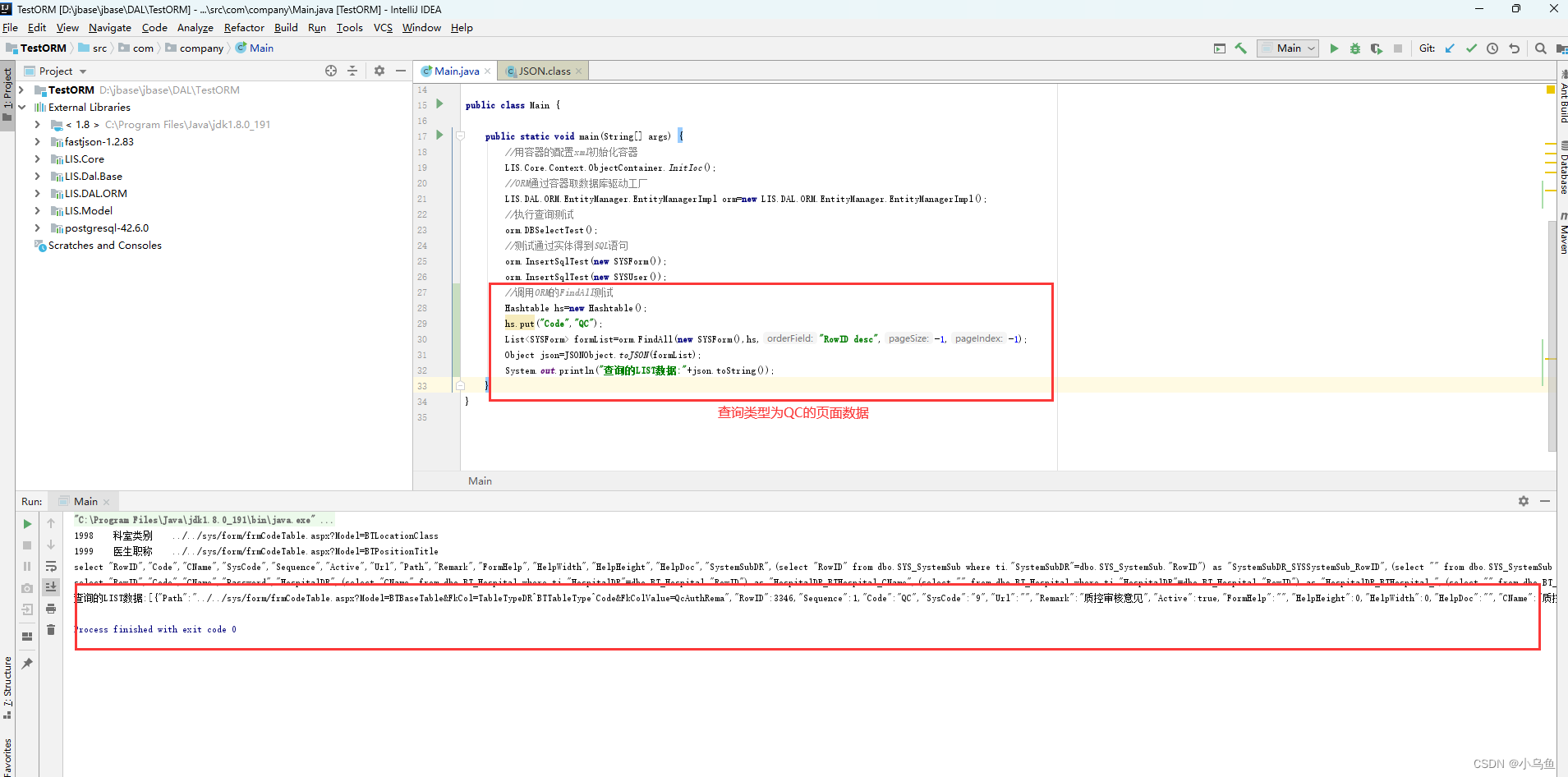
Java实现ORM第一个api-FindAll
经过几天的业余开发,今天终于到ORM对业务api本身的实现了,首先实现第一个查询的api 老的C#定义如下 因为Java的泛型不纯,所以无法用只带泛型的方式实现api,对查询类的api做了调整,第一个参数要求传入实体对象 首先补充基础方法 反射工具类,用来给实体设置属性值 package LIS.Core.Util;import java.io.File;import java.l
正则表达式中re.match、re.search、re.findall的用法和区别
这位作者的例子写的非常好,记录一下,目前用到的比较多的是findall 正则表达式中re.match、re.search、re.findall的用法和区别_<re.match object; span=(0, 270), match='<a href="/-CSDN博客