本文主要是介绍Vue - Table表格渲染上千数据优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Vue - Table表格渲染上千数据优化
这次项目经验会谈谈经常在项目中,针对成千上万数据渲染优化的不断探索来谈谈自己的体会,其目的就是保证用户浏览上万条数据的时候,UI要很流畅,确保用户操作过程中不会出现UI卡顿或者最糟糕的情况,直接浏览器奔溃。
其优化目录如下,由于内容很多,会分两篇文章进行研究,
本文章主要会围绕如何设计一个虚拟滚动来渲染成千上万的数据。
1.表格布局(To be continue)
2.Reflow & Repaint渲染方式(TBC)
3.浏览器API:window.requestAnimationFrame 渲染优化(TBC)
4.虚拟滚动:Virtual scrolling
GITHUB-Vue Table表格渲染上千数据 : 后续会加入Filter功能,针对Reflow和RequestAnimationFrame的渲染效果会更加明显

虚拟滚动(Virtual scrolling)篇
关键字:虚拟行渲染,transform数据移动,列表节点渲染优化
NK0 - Background
本文的前提条件是前端已经缓存了上万条数据,当渲染数据到UI上时,如何让用户在使用过程中不会遭到卡顿,用起来不流畅?
之前很多项目由于数据大体围绕在上千左右,当结果集结合其它功能,例如Filter数据过滤功能一起使用的话,会采用以下几种方式去优化列表渲染,
(1)Version1: 采用display:none(对应Vue的指令是v-show),再结合v-for中的Key来复用DOM元素和隐藏元素 =》该方式会导致UI Reflow即回流,所以UI会经常出现短暂的卡顿,用户体验不是很好
(2)Version2: 采用window对象的内置API,即window.requestAnimation(),来渲染成千上万条数据,即模拟动画效果让用户操作起来特别的顺畅。
以上两种方式都有个特点:DOM中会插入数据量大小的元素,尽管有些数据被隐藏起来,但都会导致HTML文件size会非常大,低端设备的速度会明显变慢。
所以基于以上两种方式,还不能够满足去渲染上万条数据!
也因此trigger出本文的主题 - 基于VUE列表的虚拟滚动
本文的虚拟滚动方式主要围绕着
(1)虚拟行渲染:缓存数据和筛选数据,除了要保留用户的可视区域的数据,还考虑到了如果用户的滚动范围不是很大的话,就不需要去刷新页面,所以DOM中的元素除了可视区域的数据,会多保留视图的上下留闲数据。
(2)布局:主要是为了假装所有数据元素都有在占用空间,浏览过React virtualized库,发现它在复用已有DOM元素的基础上,通过css的绝对定位position:absolute + top:偏移量,来移动数据,但是这样滚动元素的时候会引起浏览器回流,会增加更多的渲染开销,所以我这边会采用另一种方式,即transform:translateY(偏移量)来优化数据移动,因为该CSS3元素不会引起Reflow和Repaint。
(3)DOM复用:使DOM节点的数量保持在较低的水平,因为DOM节点如果太大而无法管理,低端设备的速度会明显变慢,所以我们能做的是复用已有的DOM节点和减少每个节点的布局、样式和绘制方面的开销成本。而VUE提供了数组全新赋值和变异方法来复用DOM和减少DOM操作,但是数组全新赋值的开销成本比数组变异开销更大,所以针对用户的滚动速度来优化列表渲染。
NK1 - 虚拟滚动(Virtual Scrolling)
TL;DR: 复用DOM元素,隐藏不在视图内的其它元素,使用占位符来延迟刷新数据。
下面是当我们用虚拟滚动方式来处理上万条数据在UI的呈现效果,
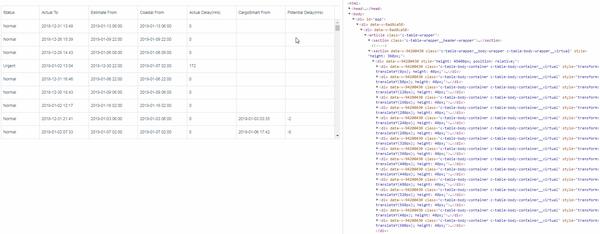
从上面的结果发现,当用鼠标滚动的时候,
(1)尽管数据量是上万条,但是HTML标签元素永远就那么几个
(2)有些HTML元素会被更新,而有些HTML元素不会变化
虚拟滚动能够很好优化上万条数据的呈现跟的上用户滚动操作的速度,犹如动画般的交互顺滑。
接下来会分享下虚拟滚动的设计实现,
NK2 Virtual scrolling - Props Design(属性设计)
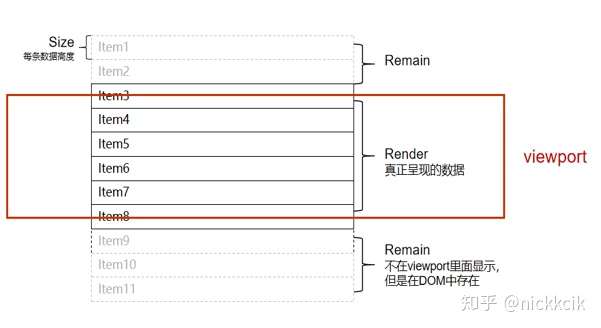
(1)viewport:这里看成是Table数据的可视区域,需要提供可视区域的高度,用于计算实际渲染在DOM中Item的数量。
(2)size:每条数据在DOM中占用的高度,用于统计虚拟列表的高度,默认每行的高度为40px。
(3)Render Items:真正曾现在用户视觉上的items。
(4)Remain Items:(向上/向下)可是区域之外的留闲数据高度,不显示在viewport中,但是存在DOM中,其用于当用户滚动的距离不是很大的时候,UI不需要重新去渲染,为滚动做了一层留长优化。
接下来讲一下虚拟滚动特征,
NK3 Virtual scrolling - Virtual Row Render(虚拟行渲染)
Virtual Row Render - 在已知viewport有高度情况下,我们可以先把每条数据看作是每一个独立的行数据,用索引来标记每条数据,用Map对象封装这些块数据,存在浏览器的内存中,当滚动事件被触发的时候,我们只需要渲染能够映射在viewport中对应的块数据,而不是遍历渲染所有块,能有效的减少HTML file size。
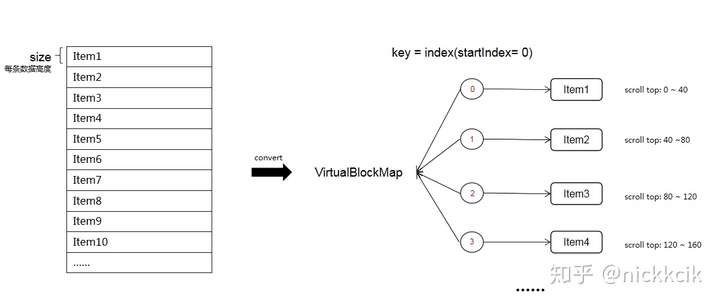
key = index,我们用数据索引和每条数据的高度来作为虚拟块Map的Key,结合滚动的距离和viewport的高度,来标记实际要渲染在DOM中的items,即
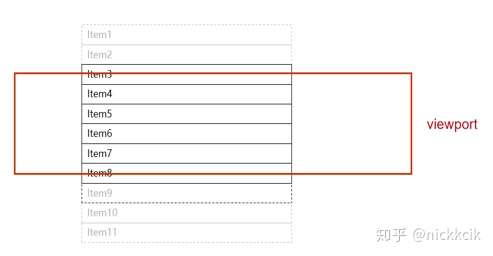
另外每个Item会根据Key值来定义其显示范围,如item1的key为0,则它的显示范围应该是[0~40)这个区间,而item2区间为[40,80),以此类推……其目的是用于计算item的显示区间是否在滚动的范围内。
NK4 Virtual scrolling - 数据移动设计
场景:当我们的列表有上万条数据,我们给定
每条数据的高度为40px,即itemHeight = 40px,
留闲高度为80,即remainHeight = 80px,
而表格的可视区域高度为80px,即viewportHeight = 80px,
由此我们可以设计存在DOM中的items最多可以渲染6条。
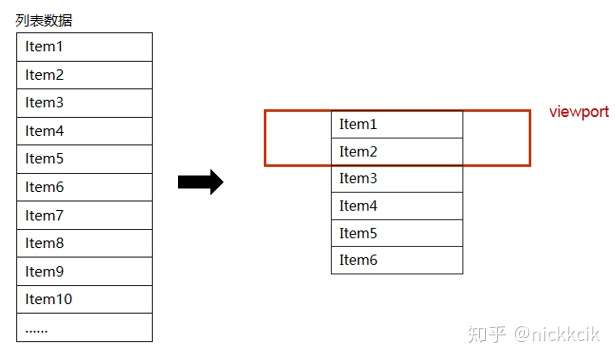
所以当我们在滚动的时候,当滚动的距离到item12的高度的时候,此时我们希望可视区域的数据会被刷新,并且DOM元素会被跟新如下,
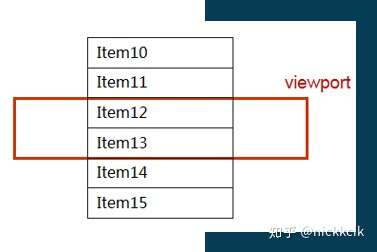
但是,当用户滚动的距离不是很大的话,例如它从item1滚动到item4的时候,我们希望DOM不需要被跟新,即

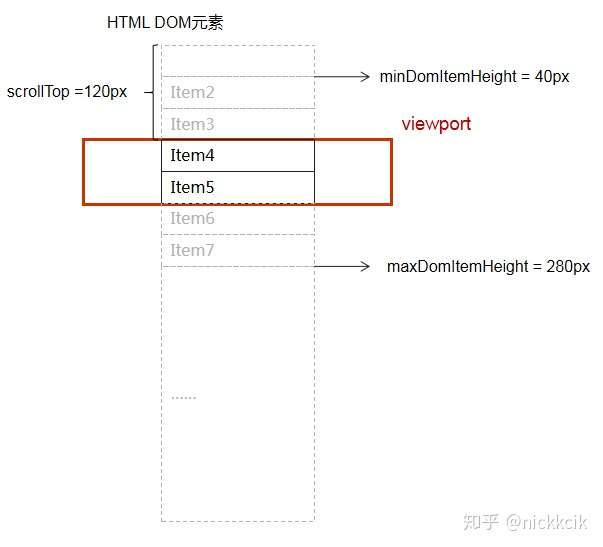
接着我们来细节化模拟数据滚动,如下图
实线,例如item1 ~ item6,代表已经在DOM中存在的数据
黑色实体,例如item1~item2,显示在可视区域的数据,
反之灰色实体item3~item6的被隐藏了起来
而虚拟列表的数据Size决定了可视区域滚动条的大小

滚动公式设计,主要是如何确定Dom items的高度范围,即
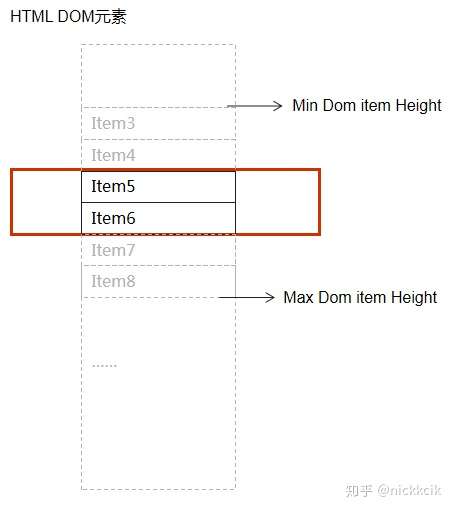
向下滚动场景模拟: 当我们滚动的距离 小于 向上的remainHeight(80px)的时候,
其minDomItemHeight = 0,
maxDomItemHeight = viewportHeight + 2 * remainHeight(向上/向下留闲) = 240px;
即

但DOM中的Items为 [item1,item2,item3,item4,item5,item6] -> 没有变化
当我们向下滚动到100px的时候,
DOM中的Items为 [item1,item2,item3,item4,item5,item6,item7] -> 新增了一个item7
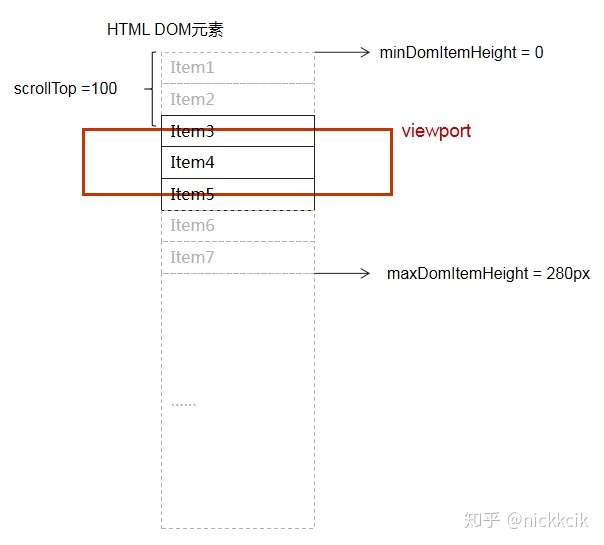
当我们滚动到120px的时候,
DOM中的Items为 [item2,item3,item4,item5,item6,item7] -> item1DOM元素被移除了。
……
所以按照用户滚动的趋势,我们统计了滚动距离时,我们的数据渲染情况如下
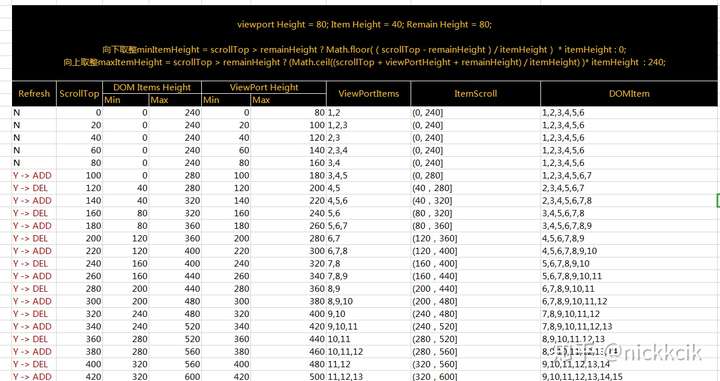
即滚动公式
向下取整 minItemHeight = scrollTop > remainHeight ? Math.floor((scrollTop - remainHeight)/ itemHeight) * itemHeight : 0;
向上取整 maxItemHeight = scrollTop > remainHeight ? (Math.ceil((scrollTop + viewPortHeight + remainHeight) / itemHeight) )* itemHeight : defaultRenderItemsHeight;
而defaultRenderItemsHeight需要跟viewport的高度和留长高度,来决定渲染在DOM中item的数量.
const renderItems = Math.ceil(viewPortHeight / itemHeight) + 2 * remainItems;
const renderItemsHeight = renderItems * itemHeight;
NK5 Virtual scrolling - CSS3 transform优化数据移动
当数据往上/下滚动的时候,我们需要复用和移动DOM中的元素,使其能根据我们算出的高度显示在viewport中,一般情况会使用position:relative + top来进行元素垂直方向的偏移,但是我们知道当采用top属性,它会使UI Reflow,性能不是很好,所以我们采用CSS3中的transform变形属性来移动,其优点是不会是UI重新的Reflow和Repaint.
transform - translateY的特点如下,
(1)范围:适用所有的HTML标签元素
(2)它是指Y轴(垂直轴)方向的移动,单位可以是px,em或百分比等
(3)当y为正时,表示元素在垂直方向向下移动;
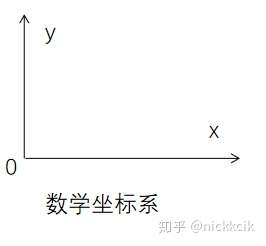
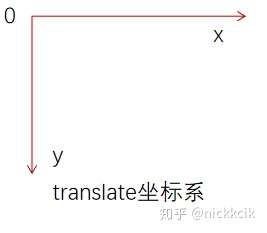
当y为负时,表示元素在垂直方向向上移动,跟我们的数学坐标系不同
而
(4)性能优化:元素移动,不会引起Reflow和Repaint
所以我们在初始化/跟新要渲染数据的时候,可以为其绑定translateY的值
(translateY=itemIndex * itemHeight),如,
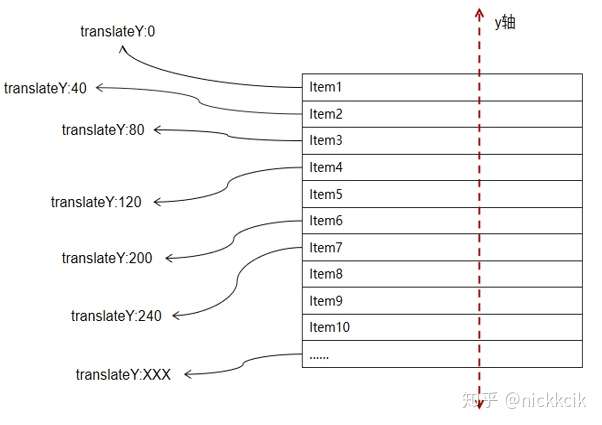
NK6 Virtual scrolling - 列表渲染优化
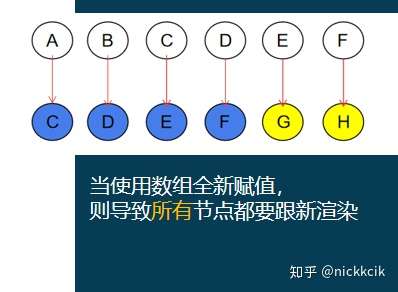
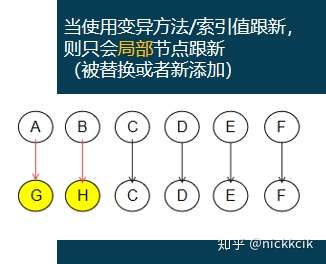
我们来比较下数组跟新的两种方式:变异方法和替换数组如下


即变异方式和替换数组方式中的索引值替换,会复用需要更改的DOM元素,
而数组全新赋值方式则会复用渲染整个列表(DOM元素移位),
当滚动元素的时候,数组全新赋值节点渲染情况如下,
而局部跟新节点的渲染取下,
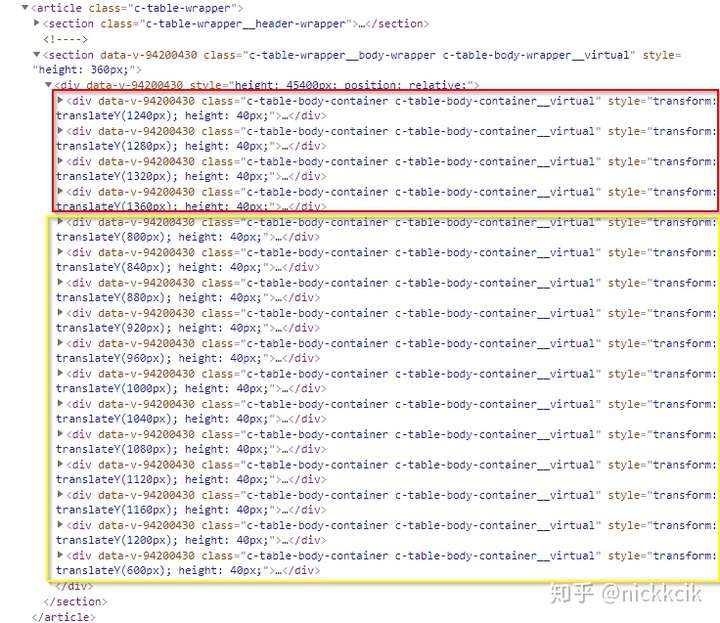
所以当我们用translateY属性来进行元素位置移动的时候,
即使元素插入DOM的位置不是按顺序排列的,但是translateY能确保其元素它在垂直方向的距离如下图,
红色区域代表当鼠标往下滚动的时候,需要跟新的DOM元素
黄色区域则代表不需要重新渲染
所以针对列表的优化渲染,建议不要对数组全新赋值,可以考虑用数组替换 + 数组变异的方式来复用已有的节点。如果前后数组变化完全不相等的话,可以直接使用数组全新赋值方式。
彩蛋: 使用AVA成为该项目的测试驱动框架,整个过程采用的是TDD(测试驱动开发)来实践数据移动的功能模块,例如,
当要计算一个minDomItemHeight的时候,其测试用例如下,
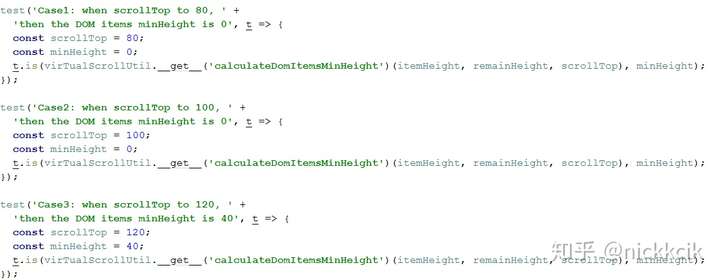
而功能实现块:

当要计算一个maxDomItemHeight的时候,其测试用例如下,
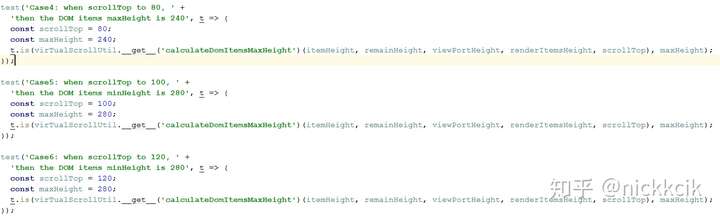
当要计算一个minDomItemHeight和maxDomItemHeight的时候,其测试用例只需要一个来验证就行,其结果如下,

而功能实现

小编是一个有着5年工作经验的前端开发工程师,关于前端编程,自己有做材料的整合,一个完整的前端编程学习路线,学习材料和工具,+我的威信收取,免费送给tanzhou-10838大家,希望你也能凭着自己的努力,成为下一个优秀的程序员。
这篇关于Vue - Table表格渲染上千数据优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






