本文主要是介绍redis核心数据结构——跳表项目设计与实现(跳表结构介绍,节点类设计,随机层级函数),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
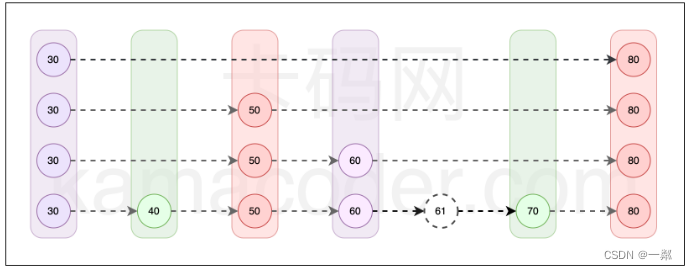
跳表结构介绍。跳表是redis等知名软件的核心数据结构,其实现的前提是有序链表,思想的本质是在原有一串存储数据的链表中,间隔地抽出一半元素作为上一级链表,并将抽提出的元素和原先的位置相关联,这样重复下去直到最上层只有一个节点。构建时比较复杂,但在查找元素时可以达到log(n)的时间复杂度。这也就是跳表这一名称的由来了。
此外等会要写ACM模式,cin cout大家都知道是iostream里面重载运算符后的输入输出方式,但也要注意下没有写using namespace std时cin和cout前都要加上std::,来说明是在标准命名空间下使用的,写了之后就不用加了。
还有new的使用方式。用过很多次new了,一直没有做个总结,这里顺便提下,
int *p = new int[6];int (*p)[10] = new int[3][10];int (*p)[10][20] = new int[5][10][20];//注意使用时不要越界了下面正式进入跳表节点类设计的部分。
首先看设计需求
你的任务是实现跳表中用于表示节点的 Node 类。
Node 类有以下属性:
- 键(key):节点存储的节点存储的数据键,可以是整数或者其他类型
- 值(value):与键关联的数据值
- 节点的层级标识(node_level):标示节点在跳表中的层级位置
- 前向指针(forwards):一个指针数组,forwards[i] 表示当前节点在第 i 层的下一个节点
Node 类有以下成员函数:
- 构造函数:接受键、值和节点级别(level)作为参数,节点级别决定了 forwards 数组的大小。
- 析构函数:销毁 Node 以及回收内存空间
- get_key() :获取节点的键
- get_value() 和 set_value() 获取和设置节点的值
输入共一行,三个整数,用空格隔开,分别为 K, V, L,分别表示节点的键、值和节点的层数,请使用 Node 构造方法,创建一个节点。
输出共一行,两个整数,分别为 Node 的 key 和 value,空格隔开,末尾换行,请通过调用 Node 的 get_key() 和 get_value() 方法进行输出。
输入示例:
1 2 3
输出示例:
1 2
代码如下:
#include <iostream>class Node {
private:int key;int val;int node_level;Node* forwards;public:Node(int inkey, int value, int level): key(inkey), val(value), node_level(level),forwards(nullptr) {}~Node(){};int getKey() {return key;}int get_value() {return val;}void set_value(int value) {val = value;}};int main() {int k, v, l;std::cin >> k >> v >> l;Node* newNode = new Node(k, v,l);std::cout << newNode->getKey() << ' ';std::cout << newNode->get_value() << std::endl;delete newNode;
}设计完类之后,我们要进入下一阶段,将类节点插入到链表中。我们首先需要确定它的层级,这里简单看下就行了,在做项目的过程中,也许并不需要去关注所有的全局细节,否则项目可能根本就做不好了。采用的是一种随机决定层数的手段。依据数学上的大数定律,在随机的次数多了,发生的频率就会贴近事情本来的概率,这也就是跳表的核心原理之一了。
代码如下:
#include<stdlib.h>
#include <iostream>
const int _max_level = 500;int getrandomLevel() {srand((int)time(0));int k = 1;while (rand() % 2) {k++;}k = (k < _max_level) ? k : _max_level;return k;
}int main() {int k = getrandomLevel();std::cout << k;
}其中srand(time(0))是利用time函数取0为参数时返回值的变化来随机初始化rand,让其产生一种随机数的效果。
这篇关于redis核心数据结构——跳表项目设计与实现(跳表结构介绍,节点类设计,随机层级函数)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





