本文主要是介绍【RAG 博客】Haystack 中的 DiversityRanker 与 LostInMiddleRanker 用来增强 RAG pipelines,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Blog:Enhancing RAG Pipelines in Haystack: Introducing DiversityRanker and LostInTheMiddleRanker
⭐⭐⭐⭐
文章目录
- Haystack 是什么
- 1. DiversityRanker
- 2. LostInTheMiddleRanker
- 使用示例
这篇 blog 介绍了什么是 Haystack,以及如何在 Haystack 框架中使用 DiversityRanker 和 LostInTheMiddleRanker 来增强 RAG pipeline 效果。我们重点是从这篇文章中学习到 RAG pipeline 中 re-rank 的思想。
我们知道,LLM 是根据他的上下文窗口中的文本内容来生成响应,但是 LLM 的上下文窗口是有 token 个数限制的,因此,我们需要充分利用 LLM 的上下文窗口来最大限度地提高其生成答案的质量。但在现实使用 RAG 时,检索到的文档可能高度相关,很多重复且数量众多,导致很有可能溢出 LLM 的上下文窗口。
本文介绍的组件 —— DiversityRanker 和 LostInTheMiddleRanker,就是用来解决这些挑战并改进 RAG pipeline 生成的答案。
Haystack 是什么
Haystack 是一个开源框架,为 NLP 研究者提供端到端的解决方案,其模块化的设计允许其集成最先进的 NLP 模型、文档存储以及 NLP 工具箱中所需的各种其他组件。
Haystack 的一个关键概念是 pipeline,它表示一系列由特定 component 执行的处理步骤,这些 component 可以执行各种类型的文本处理,并允许用户通过定义数据如何流经 pipeline 以及执行处理步骤的节点顺序,轻松创建强大且可定制的系统。
1. DiversityRanker
DiversityRanker 是一个 Haystack 的 component,它旨在增强 RAG 管道中上下文窗口所选 documents 的多样性。这样做的原因是:多样化的 documents 可以辅助 LLM 生成更广泛、更深入的答案。
DiversityRanker 使用 sentence transformers 库来计算 doc 之间的 similarity。sentence transformers 库提供了强大的 embedding 模型,可以用于创建句子、段落甚至整个 doc 的有意义的 embedding representation。
DiversityRanker 使用以下算法处理文档:
- 首先使用 sentence transformers 模型计算每个 doc 和 query 的嵌入。
- 然后选择语义上与 query 最接近的文档作为第一个选定的文档 A。
- 对于每个剩余的文档,计算与已选定的文档 A 的 similarity。从中选出一个与 A 的 similarity 最不高的文档作为下一个选中的文档。
- 重复以上步骤,直到选择出一个文档列表,其顺序从对整体多样性贡献最大的文档到贡献最小的文档。
需要注意的是,DiversityRanker 的算法是贪心的思想,其最终得到的文档列表的顺序可能并非是全局最优的。
DiversityRanker 强调了 doc 的多样性而非相关性,所以它在 RAG 的 pipeline 中应该放在像 TopPSampler 或者其他 similarity ranker 之后,这些 similarity ranker 选出了最相关的 docs,然后再使用 DiversityRanker 来从中按照多样性再次排序。
2. LostInTheMiddleRanker
在论文 Lost in the Middle: How Language Models Use Long Contexts 中,LLM 会更加着重把他的注意力放在文本开头和结尾的位置。
这个 LostInTheMiddleRanker 就是利用了这个发现和思想,将最需要让 LLM 关注的 documents 放在开头和结尾的位置,中间位置的则是相对最不重要的。
下图还展示了对于 LLM 来说,LLM 更擅长在开头和结尾的文本中提取出答案来:
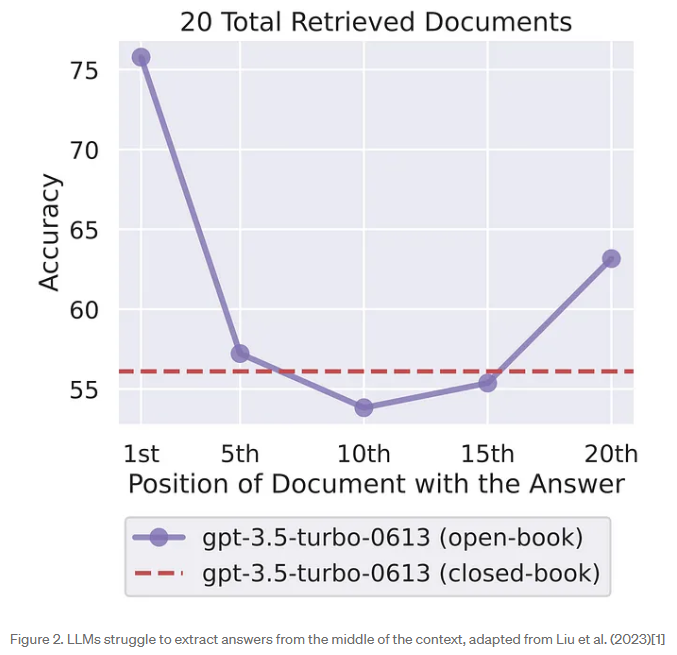
这也佐证了 LostInTheMiddleRanker 做法的正确性。
注意,LostInTheMiddleRanker 最好放置的位置是 RAG pipeline 的最后一个 ranker,它对已经基于 similarity 和 diversity 排好序的 docs 再次排序。
使用示例
如下就是一个使用 Haystack 的多个 component 搭建的 RAG pipeline:
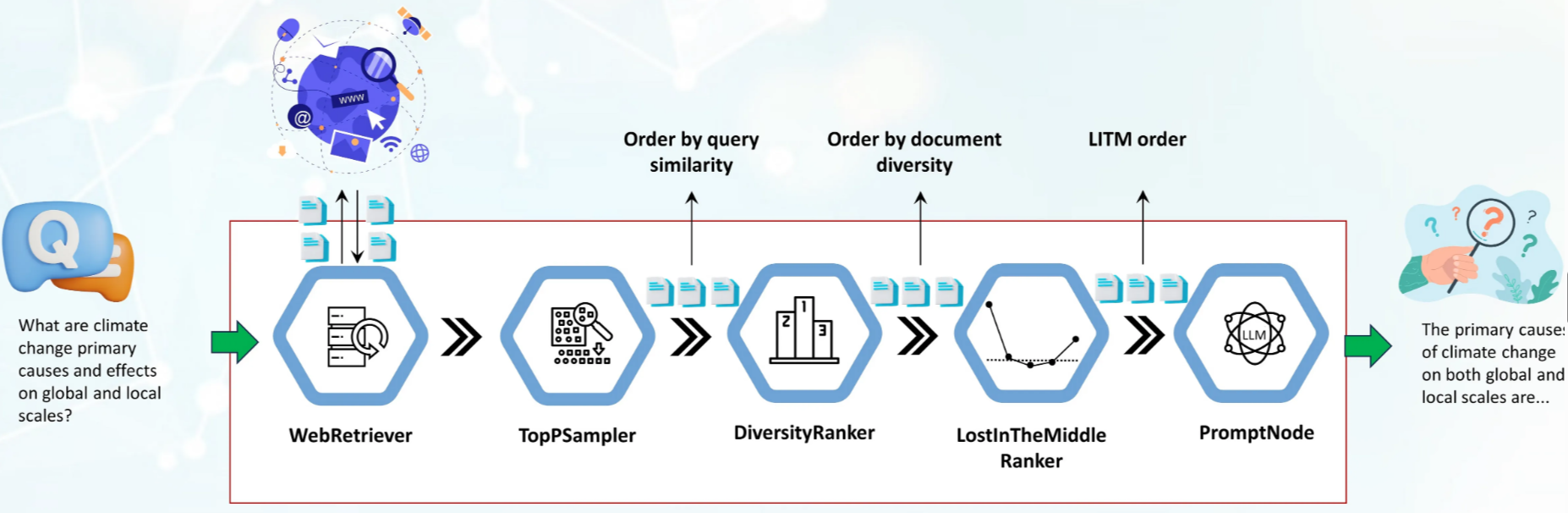
最开始是一个 WebRetriever,它根据 user query 使用 search engine API 从互联网上检索相关 HTML,并对其进行抽取转化为原生文本,然后再对其预处理切分为更短的 chunks。
之后,使用 TopPSampler 和 DiversityRanker 基于 similarity 和 diversity 对这些检索到的 docs 进行 re-rank,再使用 LostInTheMiddleRanker 做 re-rank,得到最终的文档列表。
最后,这个文档列表被传给 PromptNode,它组装成 prompt 输入给 LLM 让其基于检索到的文档来生成针对 user query 的回复。
在实践中证明,DiversityRanker 和 LostInTheMiddleRanker 的使用能够有效提升 RAF pipeline 的效果,这种在 pipeline 中针对 retrieved docs 进行 re-rank 的思想和做法值得我们学习。
这篇关于【RAG 博客】Haystack 中的 DiversityRanker 与 LostInMiddleRanker 用来增强 RAG pipelines的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







