本文主要是介绍Python 全栈体系【四阶】(三十七),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第五章 深度学习
八、目标检测
3. 目标检测模型
3.1 R-CNN 系列
3.1.1 R-CNN
3.1.1.1 定义
R-CNN(全称 Regions with CNN features) ,是 R-CNN 系列的第一代算法,其实没有过多的使用“深度学习”思想,而是将“深度学习”和传统的“计算机视觉”的知识相结合。比如 R-CNN pipeline 中的第二步和第四步其实就属于传统的“计算机视觉”技术。使用 selective search 提取 region proposals,使用 SVM 实现分类。
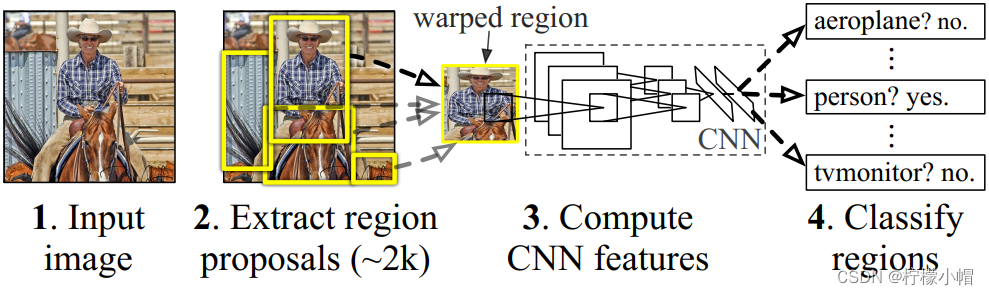
3.1.1.2 思路
- 给定一张图片,从图片中选出 2000 个独立的候选区域(Region Proposal)。
- 将每个候选区域输入到预训练好的 AlexNet 中,提取一个固定长度(4096)的特征向量。
- 对每个目标(类别)训练一 SVM 分类器,识别该区域是否包含目标。
- 训练一个回归器,修正候选区域中目标的位置:对于每个类,训练一个线性回归模型判断当前框定位是否准确。
3.1.1.3 训练
-
使用区域生成算法,生成 2000 个候选区域,这里使用的是 Selective search。
-
对生成的 2000 个候选区域,使用预训练好的 AlexNet 网络进行特征提取。将候选区域变换到网络需要的尺寸(227×227)。 在进行变换的时候,在每个区域的边缘添加 p 个像素(即添加边框,设置 p=16)。同时,改造预训练好的 AlexNet 网络,将其最后的全连接层去掉,并将类别设置为 21(20 个类别,另外一个类别代表背景)。每个候选区域输入到网络中,最终得到 4096×21 个特征。
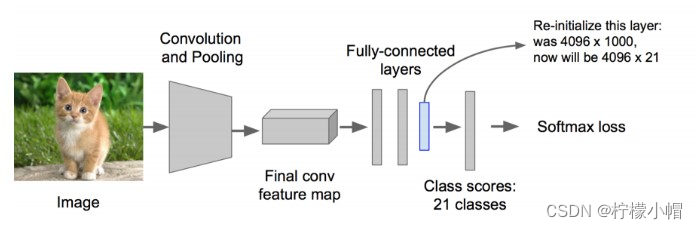
- 利用上面提取到的候选区域的特征,对每个类别训练一个 SVM 分类器(二分类),判断候选框中物体的类别,输出 Positive/Negative。如果该区域与 Ground truth 的 IOU 低于某个阈值,就将给区域设置为 Negative(阈值设置为 0.3)。如下图所示:

3.1.1.4 效果
- R-CNN 在 VOC 2007 测试集上 mAP 达到 58.5%,打败当时所有的目标检测算法。
3.1.1.5 缺点
- 重复计算,训练耗时,每个 region proposal,都需要经过一个 AlexNet 特征提取,为所有的 RoI(region of interest)提取特征大约花费 47 秒。
- 训练占用空间,特征文件需要保存到文件,5000 张的图片会生成几百 G 的特征文件。
- selective search 方法生成 region proposal,对一帧图像,需要花费 2 秒。
- 三个模块(提取、分类、回归)是分别训练的,并且在训练时候,对于存储空间消耗较大。
3.1.2 Fast R-CNN
3.1.2.1 定义
Fast R-CNN 是基于 R-CNN 和 SPPnets 进行的改进。SPPnets,其创新点在于只进行一次图像特征提取(而不是每个候选区域计算一次),然后根据算法,将候选区域特征图映射到整张图片特征图中。
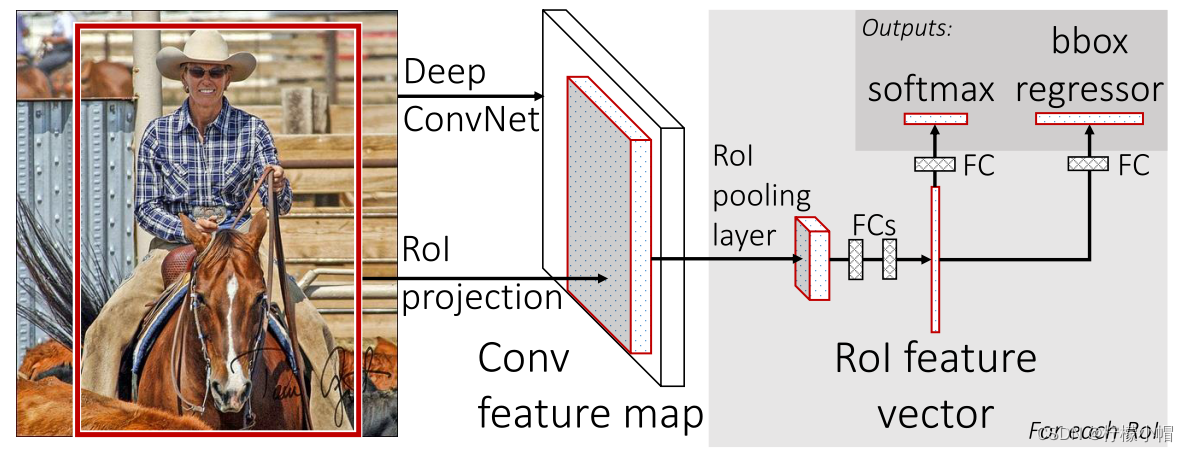
3.1.2.2 流程
-
使用 selective search 生成 region proposal,大约 2000 个左右区域候选框
-
使用 CNN 对图像进行卷积运算,得到整个图像的特征图
-
对于每个候选框,通过 RoI Projection 映射算法取出该候选框的特征图,再通过 RoI 池化层形成固定长度的特征向量
-
每个特征向量被送入一系列全连接(fc)层中,最终分支成两个同级输出层 :一个输出个类别加上 1 个背景类别的 Softmax 概率估计,另一个为个类别的每一个类别输出 4 个定位信息
3.1.2.3 改进
- 和 RCNN 相比,训练时间从 84 小时减少为 9.5 小时,测试时间从 47 秒减少为 0.32 秒。在 VGG16 上,Fast RCNN 训练速度是 RCNN 的 9 倍,测试速度是 RCNN 的 213 倍;训练速度是 SPP-net 的 3 倍,测试速度是 SPP-net 的 3 倍
- Fast RCNN 在 PASCAL VOC 2007 上准确率相差无几,约在 66~67%之间
- 加入 RoI Pooling,采用一个神经网络对全图提取特征
- 在网络中加入了多任务函数边框回归,实现了端到端的训练
3.1.2.4 缺点
- 依旧采用 selective search 提取 region proposal(耗时 2~3 秒,特征提取耗时 0.32 秒)
- 无法满足实时应用,没有真正实现端到端训练测试
- 利用了 GPU,但是 region proposal 方法是在 CPU 上实现的
3.1.3 Faster RCNN
经过 R-CNN 和 Fast-RCNN 的积淀,Ross B.Girshick 在 2016 年提出了新的 Faster RCNN,在结构上将特征抽取、region proposal 提取, bbox regression,分类都整合到了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
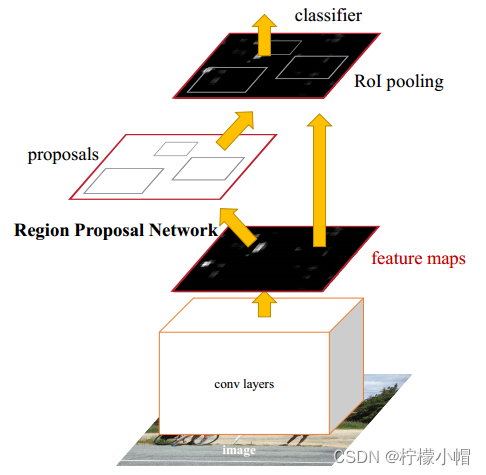
3.1.3.1 整体流程
- Conv Layers。作为一种 CNN 网络目标检测方法,Faster RCNN 首先使用一组基础的卷积/激活/池化层提取图像的特征,形成一个特征图,用于后续的 RPN 层和全连接层。
- Region Proposal Networks(RPN)。RPN 网络用于生成候选区域,该层通过 softmax 判断锚点(anchors)属于前景还是背景,在利用 bounding box regression(包围边框回归)获得精确的候选区域。
- RoI Pooling。该层收集输入的特征图和候选区域,综合这些信息提取候选区特征图(proposal feature maps),送入后续全连接层判定目标的类别。
- Classification。利用取候选区特征图计算所属类别,并再次使用边框回归算法获得边框最终的精确位置。
3.1.3.2 RPN 网络
RPN 网络全称 Region Proposal Network(区域提议网络),是专门用来从特征图生成候选区域的网络。其结构如下所示:
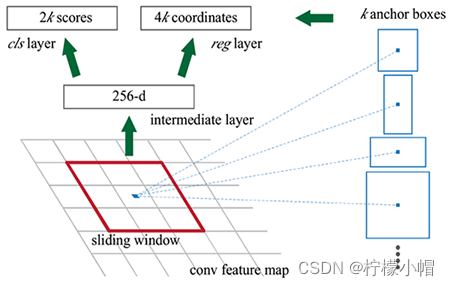
流程步骤:
(1)输入:通过主干网卷积得到的特征图
(2)对于特征图上的每一个点(称之为 anchor point,锚点),生成具有不同 尺度 和 宽高比 的锚点框,这个锚点框的坐标(x,y,w,h)是在原图上的坐标
(3)然后将这些锚点框输入到两个网络层中去,一个(rpn_cls_score)用来分类,即这个锚点框里面的特征图是否属于前景;另外一个(rpn_bbox_pred)输出四个位置坐标(相对于真实物体框的偏移)
(4)将锚点框与 Ground Truth 中的标签框进行 IoU 对比,如果其 IoU 高于某个阈值,则该锚点框标定为前景框,否则属于背景框;对于前景框,还要计算其与真实标签框的 4 个位置偏移;将这个标注好的锚点框(带有 前背景类别 和 位置偏移 标注)与 3 中卷积网络层的两个输出进行 loss 比较(类别:CrossEntrpy loss 和 位置回归:smooth L1 loss),从而学习到如何提取前景框
(5)学习到如何提取前景框后,就根据 rpn_cls_score 层的输出概率值确定前景框;位置偏移值则被整合到锚点框的坐标中以得到实际的框的坐标;这样子就得到了前景框,起到了 selective search 的作用。RPN 生成的 proposal 就称为 Region of Interest.由于他们具有不同的尺度和长度,因此需要通过一个 ROI pooling 层获得统一的大小
3.1.3.3 Anchors
Anchors(锚点)指由一组矩阵,每个矩阵对应不同的检测尺度大小。如下矩阵:
[[ -84. -40. 99. 55.][-176. -88. 191. 103.][-360. -184. 375. 199.][ -56. -56. 71. 71.][-120. -120. 135. 135.][-248. -248. 263. 263.][ -36. -80. 51. 95.][ -80. -168. 95. 183.][-168. -344. 183. 359.]]
其中每行 4 个值( x 1 , y 1 , x 2 , y 2 x_1, y_1, x_2, y_2 x1,y1,x2,y2),对应矩形框左上角、右下角相对于中心点的偏移量。9 个矩形共有三种形状,即 1:1, 1:2, 2:1,即进行多尺度检测。
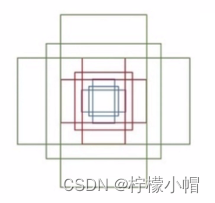
例如,一张 800*600 的原始图片,经过 VGG 下采样后(生成特征矩阵)16 倍大小,大小变为 50*38,每个点设置 9 个 anchor,则总数为:
ceil(800 / 16) * ceil(600 / 16) * 9 = 50 * 38 * 9 = 17100
3.1.3.4 Bounding box regression
物体识别完成后,通过一种方式对外围框进行调整,使得和目标物体更加接近。
3.1.3.5 损失函数
对一个图像的损失函数,是一个分类损失函数与回归损失函数的叠加:
L ( { p i } , { t i } ) = 1 N c l s ∑ L c l s ( p i , p i ∗ ) + λ 1 N r e g ∑ p i ∗ L r e g ( t i , t i ∗ ) L(\{p_i\},\{t_i\}) = \frac{1}{N_{cls}}\sum{L_{cls}(p_i, p_i^*)} + \lambda\frac{1}{N_{reg}}\sum{p_i^*L_{reg}(t_i, t_i^*)} L({pi},{ti})=Ncls1∑Lcls(pi,pi∗)+λNreg1∑pi∗Lreg(ti,ti∗)
-
i 是一个 mini-batch 中 anchor 的索引
-
p i p_i pi是 anchor i 为目标的预测概率
-
ground truth 标签 p i ∗ p_i^* pi∗就是 1,如果 anchor 为负, p i ∗ p_i^* pi∗就是 0
-
t i t_i ti是一个向量,表示预测的包围盒的 4 个参数化坐标
-
N c l s N_{cls} Ncls是与正 anchor 对应的 ground truth 的坐标向量
-
N r e g N_{reg} Nreg为 anchor 位置的数量(大约 2400), λ \lambda λ=10
分类损失函数:
L c l s ( p i , p i ∗ ) = − l o g [ p i ∗ p i + ( 1 − p i ∗ ) ( 1 − p i ) ] L_{cls}(p_i, p_i^*) = -log[p_i^*p_i + (1-p_i^*)(1-p_i)] Lcls(pi,pi∗)=−log[pi∗pi+(1−pi∗)(1−pi)]
位置损失函数:
L r e g ( t i , t i ∗ ) = R ( t i − t i ∗ ) L_{reg}(t_i, t_i^*) = R(t_i - t_i^*) Lreg(ti,ti∗)=R(ti−ti∗)
其中:
R = s m o o t h L 1 ( x ) = { 0.5 x 2 i f ∣ x ∣ < 1 ∣ x ∣ − 0.5 o t h e r w i s e R = smooth_{L1}(x) = \begin{cases}{0.5x^2} \ \ if |x| < 1\\ |x|-0.5 \ \ otherwise \end{cases} R=smoothL1(x)={0.5x2 if∣x∣<1∣x∣−0.5 otherwise
3.1.3.6 改进
- 在 VOC2007 测试集测试 mAP 达到 73.2%,目标检测速度可达 5 帧/秒
- 提出 Region Proposal Network(RPN),取代 selective search,生成待检测区域,时间从 2 秒缩减到了 10 毫秒
- 真正实现了一个完全的 End-To-End(端对端)的 CNN 目标检测模型
- 共享 RPN 与 Fast RCNN 的特征
3.1.3.7 缺点
- 还是无法达到实时检测目标
- 获取 region proposal, 再对每个 proposal 分类计算量还是较大
3.1.4 RCNN 系列总结
3.1.4.1 RCNN
解决什么问题:能够从图像中检测出物体
使用了什么方法:
- SS 算法产生候选区
- 对每个候选区进行卷积,得到每个区域的特征图
- 将特征图送到一组 SVM 做多分类,再训练一个模型定位
取得了什么效果:mAP 能达到 58.5%,速度极慢
特点及适用性:慢,几乎不用
3.1.4.2 Fast RCNN
解决什么问题:对 RCNN 模型进行优化,提升速度
使用了什么方法:
- SS 算法产生候选区
- 对整个图像进行卷积,得到整个图像的特征图(最主要的优化)
- 将分类器、定位模型整合到一起,用神经网络来替代
取得了什么效果:
- 速度:速度较上一代模型 RCNN 成倍提升,达到 0.5F/S
- mAP:66~67%
3.1.4.3 Faster RCNN
解决什么问题:对 Fast RCNN 进行优化,提升速度和精度
使用了什么方法:
- 改进候选区域产生方法:使用 RPN,在特征图而不是在原图上产生候选区,只需 10ms
- 引入 Anchor Box 机制:在同一个检测点,使用大小不同、比例不同的检测框
- 将所有步骤(提取特征、生成候选区、产生分类+定位输出)整合到同一个模型中
取得了什么效果:
- 速度:5F / S
- mAP:73.2%
特点及适用性:
- 缺点:检测速度还是较慢,无法检测视频,无法实现实时性检测
- 优点:精度不错
- 适用性:适用于精度要求较高,速度要求不高的情况
这篇关于Python 全栈体系【四阶】(三十七)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








