本文主要是介绍SparkRDD之——RDD概述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1、什么是RDD
①弹性:
②分布式
③数据集
④数据抽象
⑤不可变
2、RDD特征
①分区列表
②分区计算函数
③依赖于其他RDD
④(Key,Value)数据类型的RDD分区器(可选特征)
⑤首选位置(可选特征)
3、执行原理
4、RDD的依赖
①窄依赖
②宽依赖
4、创建RDD
①在内存中创建
②读取文件创建
5、spark分区方式
①读取数据分区方式
②如何分区
1、什么是RDD
①弹性:
⚫存储的弹性:内存与磁盘的自动切换,Spark优先把数据放到内存中,如果内存放不下,就会放到磁盘里面,程序进行自动的存储切换。
⚫容错的弹性:数据丢失可以自动恢复,在RDD进行转换和动作的时候,会形成RDD的Lineage依赖链即血统,当某一个RDD失效的时候,可以通过重新计算上游的RDD来重新生成丢失的RDD数据。
⚫计算的弹性:计算出错重试机制,RDD的计算任务如果运行失败,会自动进行任务的重新计算,默认次数是4次。
⚫分片的弹性:可根据需要重新分片,动态调整数据分片的个数即可以重分区,提升整体的应用执行效率。
②分布式
数据存储在大数据集群不同节点上
③数据集
RDD 封装了计算逻辑,并不保存数据。数据在内存中的多个 RDD 操作之间进行传递,不需要在磁盘上进行存储和读取,避免了不必要的读写磁盘开销;
④数据抽象
RDD 是一个抽象类,需要子类具体实现
⑤不可变
RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
2、RDD特征
RDD总共有五个特征,三个基本特征,两个可选特征。
①分区列表
每个RDD被分为多个分区(Partitions),这些分区运行在集群中的不同节点,每个分区都会被一个计算任务处理,分区数决定了并行计算的数量,创建RDD时可以指定RDD分区的个数。如果不指定分区数量,当RDD从集合创建时,默认分区数量为该程序所分配到的资源的CPU核数(每个Core可以承载2~4个Partition),如果是从HDFS文件创建,默认为文件的Block数。
②分区计算函数
Spark的RDD的计算函数是以分区为基本单位计算的,每个RDD都会实现 compute函数,对具体的分区进行计算。
③依赖于其他RDD
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。因为RDD中是不保存数据的,所以要得到该分区数据必须从头开始计算。而如果出现shuffer即重分区,那么会从shuffer这里会产生一个新的血缘,如果要恢复数据那么需要从头开始重新计算。
④(Key,Value)数据类型的RDD分区器(可选特征)
当数据为 KV 类型数据时,可以通过设定自定义分区器自定义数据的分区
⑤首选位置(可选特征)
3、执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。 执行时,需要将计算资源和计算模型进行协调和整合。
Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。 即RDD 采用了惰性调用,即在 RDD 的执行过程中,所有的转换操作都不会执行真正的操作,只会记录依赖关系,而只有遇到了行动操作,才会触发真正的计算,并根据之前的依赖关系得到最终的结果。
正是 RDD 的这种惰性调用机制,使得转换操作得到的中间结果不需要保存,而是直接管道式的流入到下一个操作进行处理。




4、RDD的依赖
RDD的依赖关系分为两种模型,一种是窄依赖(narrow dependency)和宽依赖(wide dependency)。
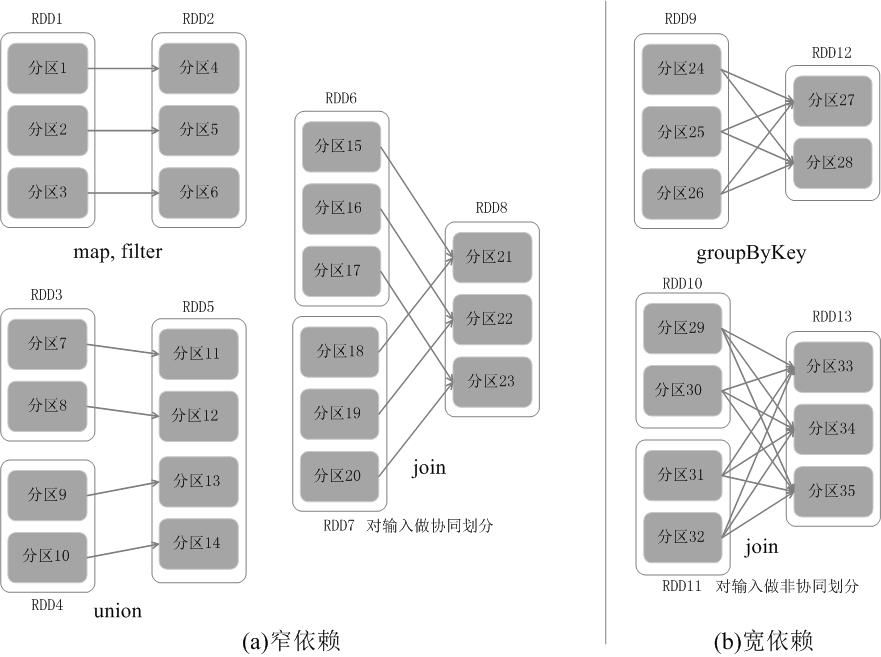
①窄依赖
父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区(第一类),或者是多个父RDD的分区对应于一个RDD的分区(第二类),也就是说一个父RDD的一个分区不可能对应于一个子RDD的多个分区。
如下图所示,对输入进行协同划分(co-partitioned)的join属于第二类。当子RDD的分区依赖于单个父RDD的分区的时候,分区的结构不会发生改变,如下图中的map,filter等操作,相反的,对于一个子RDD的分区依赖于多个RDD的分区的时候,分区的结构会发生改变,如下图的union操作。
②宽依赖
宽依赖是值子RDD的每一个分区都要依赖于所有父RDD的所有分区或者多个分区。也就是说存在一个父RDD的一个分区对应着一个子RDD的多个分区。如下图的groupByKey就属于宽依赖。其中宽依赖会出发shuffle操作。
4、创建RDD
①在内存中创建
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))②读取文件创建
val rdd: RDD[String] = sc.TextFile("Input/input.txt")③读取多个文件创建
val rdd: RDD[(String, String)] = sc.wholeTextFiles("Input/WordCount")
//返回的是一个[String, String]类型元组,第一个元素表示文件路径,第二个元素表示文件内容5、spark分区方式
①读取数据分区方式
makeRDD方法可以传递第二个参数,这个参数可以表示分区的数量
val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("Partition")
sparkConf.set("spark.default.parallelism", "3")
val sc: SparkContext = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
rdd.saveAsTextFile("OutPut/par-memory")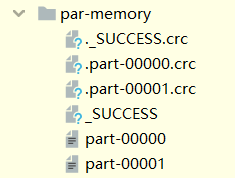
第二个参数可以不传递,makeRDD方法会使用默认值:defaultParallelism
spark在默认情况下,从配置对象中获取配置参数:spark.default.parallelism的值作为分区数
如果获取不到,那么使用totalCores属性得到分区数,即为当前运行环境的最大可用核数
val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("Partition")
sparkConf.set("spark.default.parallelism", "3")
val sc: SparkContext = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
rdd.saveAsTextFile("OutPut/par-memory")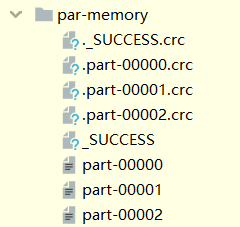
textFile分区数从配置对象中获取配置参数:spark.default.parallelism的值作为分区数如果获取不到,那么使用totalCores属性得到分区数,即为当前运行环境的最大可用核数
②如何分区
//两个分区时:【1,2】,【3,4】
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)//三个分区时:【1】,【2】,【3,4】
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 3)//五个值三个分区时:【1】,【2,3】,【4,5】
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5), 3)根据该函数进行分区
i为分区的分区号,length为数据长度,numSilence为分区数量
(start, end)为左开右闭(0 until numSlices).iterator.map { i =>val start = ((i * length) / numSlices).toIntval end = (((i + 1) * length) / numSlices).toInt(start, end)
}
这篇关于SparkRDD之——RDD概述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







