sparkrdd专题

SparkRDD转DataSet/DataFrame的一个深坑
大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! By 大数据技术与架构 场景描述:本文是根据读者反馈的一个问题总结而成的。 关键词:Saprk RDD 原需求:希望在map函数中将每一

SparkRDD之mapPartitions和mapPartitionsWithIndex
1.mapPartitions mapPartition可以这么理解,先对RDD进行partition,再把每个partition进行map函数。 下面的例子,将整数转为字符串: package com.cb.spark.sparkrdd;import java.util.ArrayList;import java.util.Arrays;import java.util.Iterato
SparkRDD之filter、filterByRange
1.filter:使用一个布尔函数为RDD的每个数据项计算,并将函数返回true的项放入生成的RDD中。 package com.cb.spark.sparkrdd;import java.util.Arrays;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apac
SparkRDD之distinct和first
distinct:对RDD中的元素进行去重。 first:返回RDD中第一个元素。 package com.cb.spark.sparkrdd;import java.util.Arrays;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.a
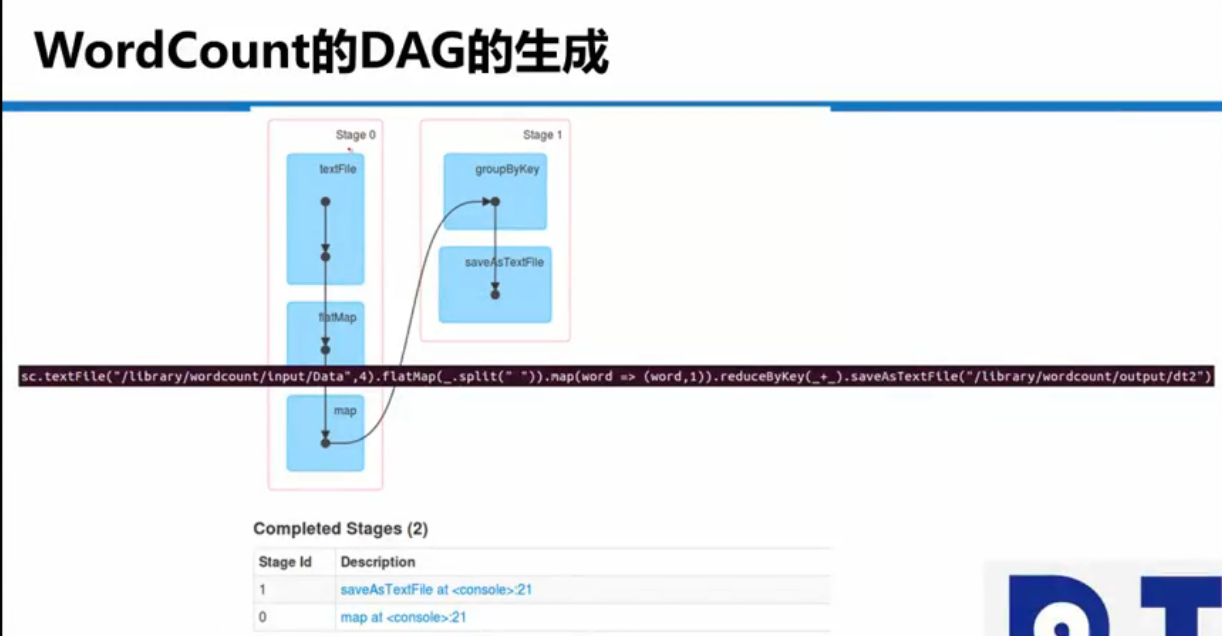
sparkRDD操作
RDD介绍 标签(空格分隔): spark hadoop,spark,kafka交流群:224209501 RDD 操作 1,RDD五大特点: 1,A list of partions 一系列的分片:比如64M一个分片,类似于hadoop的splits。 2,A function for computing each split 在每个分区上都有一个函数去迭代、执行、计算它。

sparkRDD中key-value类型类型数据的三种方法对比
reduceBykey | groupByKey | sortByKey 的区别! reduceBykey操作——reduceBykey在源码中reduce之前使用预先聚合的combine操作 groupByKey——直接进行shuffle的操作 sortByKey ——根据key进行排序的操作 总结: reduc

SparkRDD——行动算子
一、行动算子定义 spark的算子可以分为trans action算子 以及 action算子 ,即变换/转换 算子。如果执行一个RDD算子并不触发作业的提交,仅仅只是记录作业中间处理过程,那么这就是trans action算子 ,相反如果执行这个 RDD 时会触发 Spark Context 提交 Job 作业,那么它就是 action算子及行动算子。 总结来说就是在Spark中,转换算子并不

SparkRDD——转换算子
转换算子 一、单value型转换算子(只使用1个RDD):1、map 将数据进行转换,数据量不会增加和减少2、mapPartitions 以分区为单位将一个分区内的数据进行批处理操作,且可以执行过滤操作3、mapPartitionsWithIndex 功能类似mapPartiutions算子,只是加入了每个分区的索引,可以
SparkRDD之——RDD概述
目录 1、什么是RDD ①弹性: ②分布式 ③数据集 ④数据抽象 ⑤不可变 2、RDD特征 ①分区列表 ②分区计算函数 ③依赖于其他RDD ④(Key,Value)数据类型的RDD分区器(可选特征) ⑤首选位置(可选特征) 3、执行原理 4、RDD的依赖 ①窄依赖 ②宽依赖 4、创建RDD ①在内存中创建 ②读取文件创建 5、spark分区方式 ①读取数据
sparkRDD转DataFrame写hive的坑
在RDD使用schema和RDD的Row转成DataFrame再写到hive时,中间遇到一个坑, 我的写入代码是这样 // 创建schemaval schema: types.StructType = StructType(Seq(StructField("capture_time",IntegerType,true),StructField("color_id",IntegerType,t
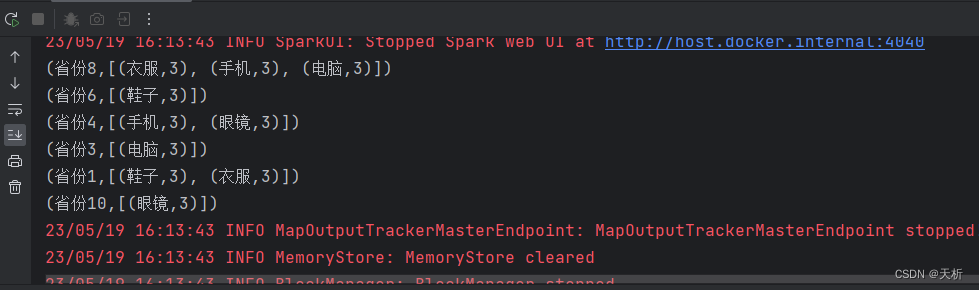
【Java】SparkRDD算子案例:统计出每一个省份广告被点击次数的TOP3
题目描述 统计出每一个省份广告被点击次数的TOP3 假设这些信息都存储在一个文件里,并且该文件的格式如下,时间戳,省份,城市,用户,广告,中间字段使用空格分割。 构造样例数据 1684484483 省份1 北京 1001 鞋子1684484483 省份1 上海 1002 衣服1684484483 省份3 广州 1003 电脑1684484483 省份4 深圳 1004 手机16844

关于SparkRdd和SparkSql的几个指标统计,scala语言,打包上传到spark集群,yarn模式运行
需求: ❖ 要求:分别用SparkRDD, SparkSQL两种编程方式完成下列数据分析,结合webUI监控比较性能优劣并给出结果的合理化解释.1、分别统计用户,性别,职业的个数:2、查看统计年龄分布情况(按照年龄分段为7段)3、查看统计职业分布情况(按照职业统计人数)4、统计最高评分,最低评分,平均评分,中位评分,平均每个用户的评分次数,平均每部影片被评分次数:5、统计评分分布情况