本文主要是介绍【Java】SparkRDD算子案例:统计出每一个省份广告被点击次数的TOP3,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题目描述
统计出每一个省份广告被点击次数的TOP3
假设这些信息都存储在一个文件里,并且该文件的格式如下,时间戳,省份,城市,用户,广告,中间字段使用空格分割。
构造样例数据
1684484483 省份1 北京 1001 鞋子
1684484483 省份1 上海 1002 衣服
1684484483 省份3 广州 1003 电脑
1684484483 省份4 深圳 1004 手机
1684484483 省份4 成都 1005 眼镜
1684484483 省份6 天津 1001 鞋子
1684484483 省份8 重庆 1002 衣服
1684484483 省份8 杭州 1003 电脑
1684484483 省份8 南京 1004 手机
1684484483 省份10 厦门 1005 眼镜
1684484483 省份1 北京 1001 鞋子
1684484483 省份1 上海 1002 衣服
1684484483 省份3 广州 1003 电脑
1684484483 省份4 深圳 1004 手机
1684484483 省份4 成都 1005 眼镜
1684484483 省份6 天津 1001 鞋子
1684484483 省份8 重庆 1002 衣服
1684484483 省份8 杭州 1003 电脑
1684484483 省份8 南京 1004 手机
1684484483 省份10 厦门 1005 眼镜
1684484483 省份1 北京 1001 鞋子
1684484483 省份1 上海 1002 衣服
1684484483 省份3 广州 1003 电脑
1684484483 省份4 深圳 1004 手机
1684484483 省份4 成都 1005 眼镜
1684484483 省份6 天津 1001 鞋子
1684484483 省份8 重庆 1002 衣服
1684484483 省份8 杭州 1003 电脑
1684484483 省份8 南京 1004 手机
1684484483 省份10 厦门 1005 眼镜
Java Spark代码实现
package T051801;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class AdClickTop3 {public static void main(String[] args) {// 创建SparkConf和JavaSparkContextSparkConf conf = new SparkConf();// 设置应用名称conf.setAppName("AdClickTop3");// 设置运行模式// local:表示在本地单机上以单线程模式运行// local[*]:表示在本地单机上以多线程模式运行,线程数由系统自动决定// spark://HOST:PORT:表示连接到指定的 Spark 集群运行// mesos://HOST:PORT:表示连接到指定的 Mesos 集群运行// yarn:表示在 YARN 集群上运行conf.setMaster("local[*]");// 创建 JavaSpark 上下文对象JavaSparkContext sc = new JavaSparkContext(conf);// 读取数据文件JavaRDD<String> fileRDD = sc.textFile("ad.txt");// 按照空格分割数据取得省份和广告 ((省份, 广告), 1)JavaPairRDD<Tuple2<String, String>, Integer> pairRDD = fileRDD.mapToPair(s -> new Tuple2<>(new Tuple2<>(s.split(" ")[1], s.split(" ")[4]), 1));// 计算点击数 ((省份, 广告), 点击数和)JavaPairRDD<Tuple2<String, String>, Integer> reduceRDD = pairRDD.reduceByKey(Integer::sum);// 转换 key 的结构 ((省份, 广告), 点击数和) => (省份, (广告, 点击数和))JavaPairRDD<String, Tuple2<String, Integer>> provinceAdClicksRDD = reduceRDD.mapToPair((PairFunction<Tuple2<Tuple2<String, String>, Integer>, String, Tuple2<String, Integer>>) tuple -> {String province = tuple._1()._1();String ad = tuple._1()._2();int clicks = tuple._2();return new Tuple2<>(province, new Tuple2<>(ad, clicks));});// 按照省份进行分组,将同一省份的元素放到同一个 Iterable 中JavaPairRDD<String, Iterable<Tuple2<String, Integer>>> provinceAdClicksListRDD = provinceAdClicksRDD.groupByKey();// 获取每个城市 Top3 点击广告JavaPairRDD<String, Iterable<Tuple2<String, Integer>>> topTwoAdsByProvinceRDD = provinceAdClicksListRDD.mapValues((Function<Iterable<Tuple2<String, Integer>>, Iterable<Tuple2<String, Integer>>>) tuple2s -> {ArrayList<Tuple2<String, Integer>> tuple2s1 = new ArrayList<>();for (Tuple2<String, Integer> next : tuple2s) {tuple2s1.add(next);}// 降序排列tuple2s1.sort((o1, o2) -> o2._2() - o1._2());ArrayList<Tuple2<String, Integer>> t = new ArrayList<>();Iterator<Tuple2<String, Integer>> iterator1 = tuple2s1.iterator();// 遍历前 Top3 点击广告添加到 Listint i = 0;while (iterator1.hasNext() & i < 3) {t.add(iterator1.next());i++;}return t;});// 计算结果收集到 ListList<Tuple2<String, Iterable<Tuple2<String, Integer>>>> data = topTwoAdsByProvinceRDD.collect();// 输出结果data.forEach(System.out::println);sc.stop();}}结果验证
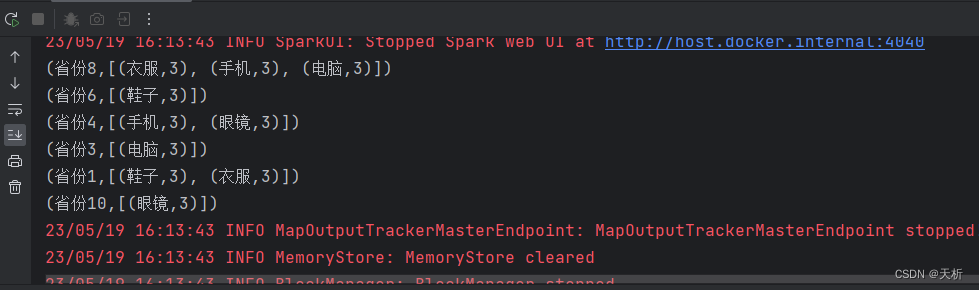
这篇关于【Java】SparkRDD算子案例:统计出每一个省份广告被点击次数的TOP3的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






