本文主要是介绍基于光伏电站真实数据集的深度学习预测模型(Python代码,深度学习五个模型),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
效果视频链接:基于深度学习光伏预测系统(五个模型)_哔哩哔哩_bilibili

界面设计

注册界面
登录界面

主界面

展示界面
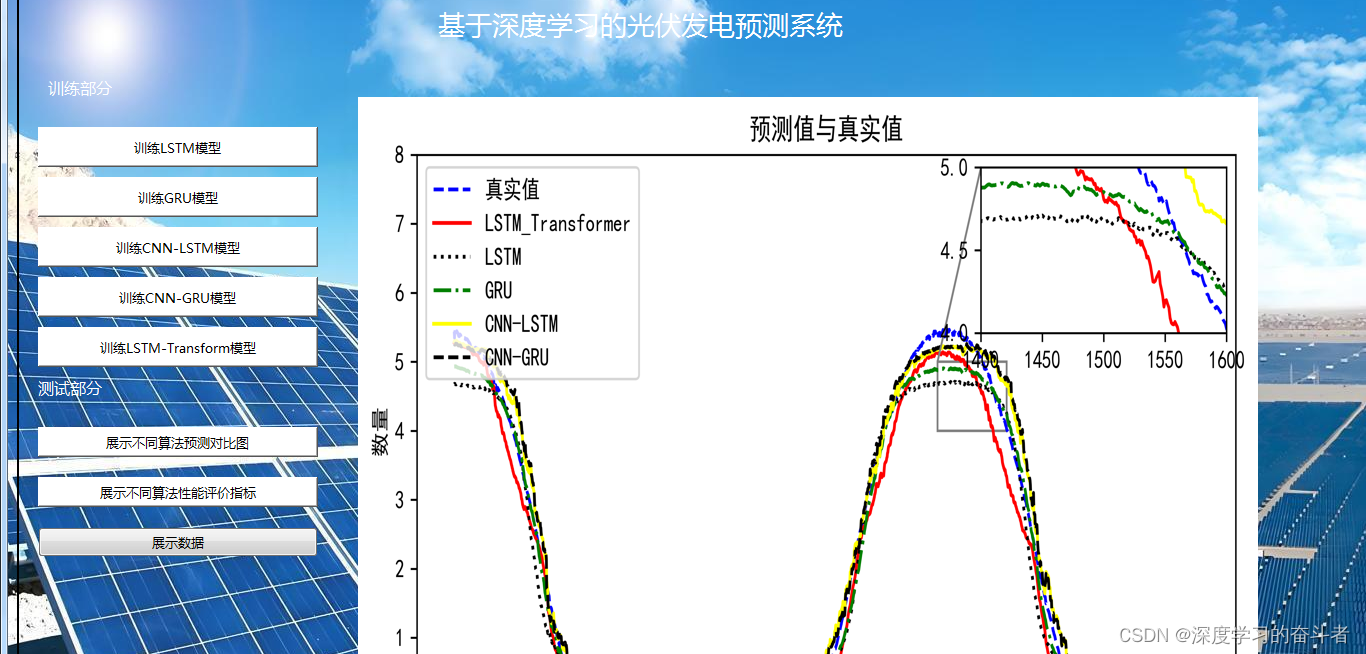
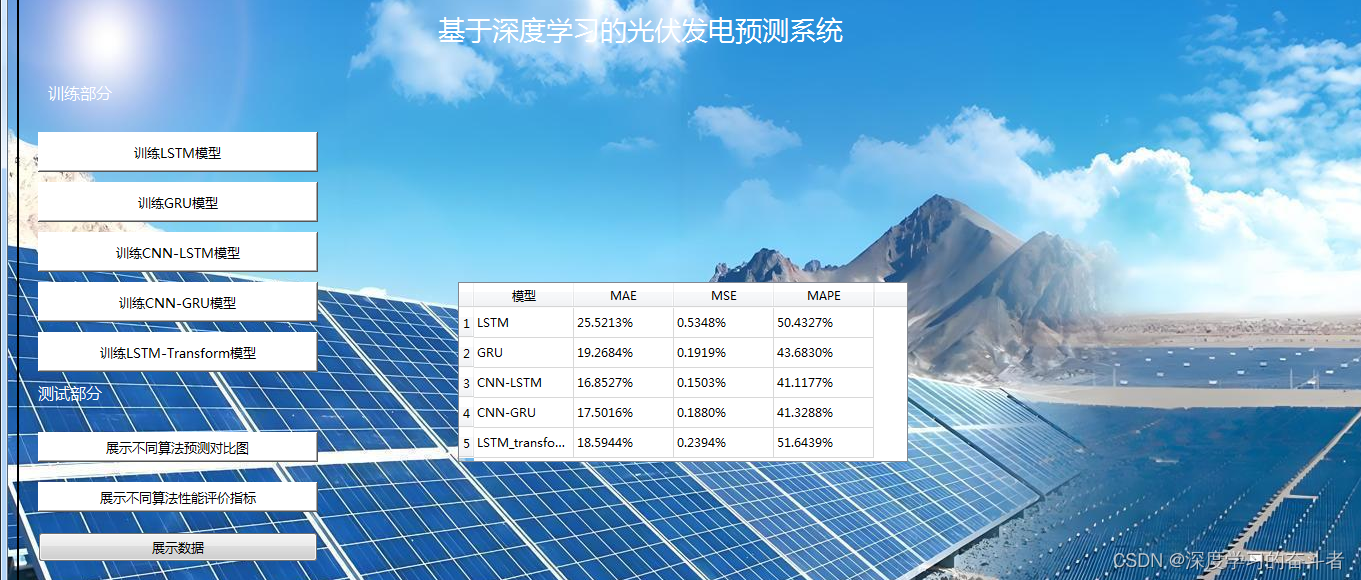
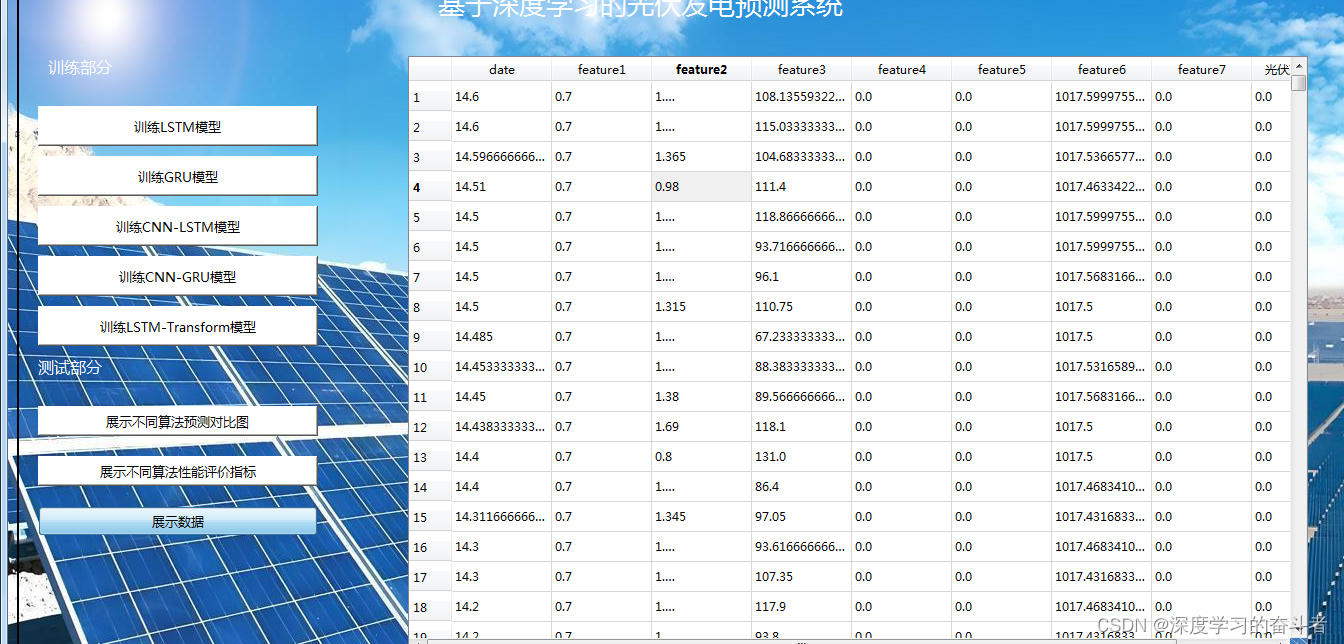
1.数据集来源
The SOLETE dataset
这里分别保存了不同间隔采样时间表格

1min是以1min 间隔采集的数据集
数据集截图(开始位置截图)
截止位置截图
2.关于特征与标签选择(在交通流量预测方面主要有以下两种方式,本文是第二种)
2.1.第一种方式如下图所示

每一行前9列(黄色部分) 作为特征输入,每一行的第10列值作为标签(红色部分)
2.2.第二种方式如下图所示

前6行的10列数据(黄色部分)作为特征输入,第7行的第10列数据(红色部分)为标签。
根据已获取的历史数据预测下一个时间点或者未来多个时间点 更符合实际。
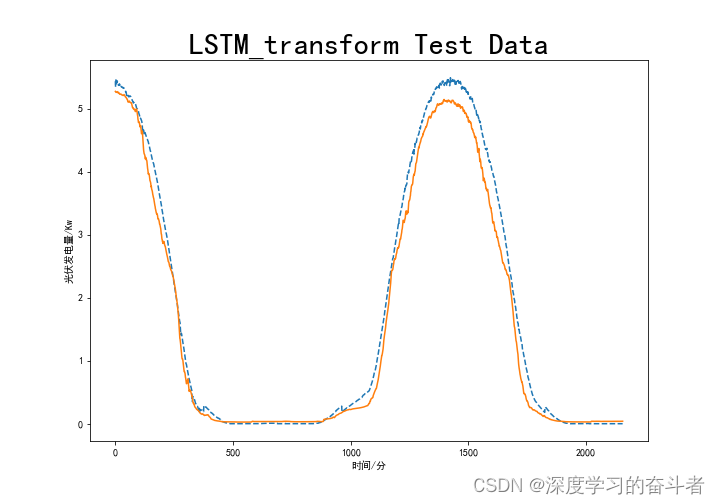
3.模型(LSTM;GRU;CNN-LSTM;CNN-GRU;LSTM_transform模型)评价指标
MAE;MSE;MAPE
LSTM 26.3020%; 0.5736% ;49.3607%
GRU 19.3869% ;0.1793%; 44.0200%
CNN-LSTM 16.0719% ;0.1367%; 39.5737%
CNN-GRU 17.2165%; 0.1541% ;41.5540%
LSTM_transform 15.9017%; 0.1385%; 39.7443%
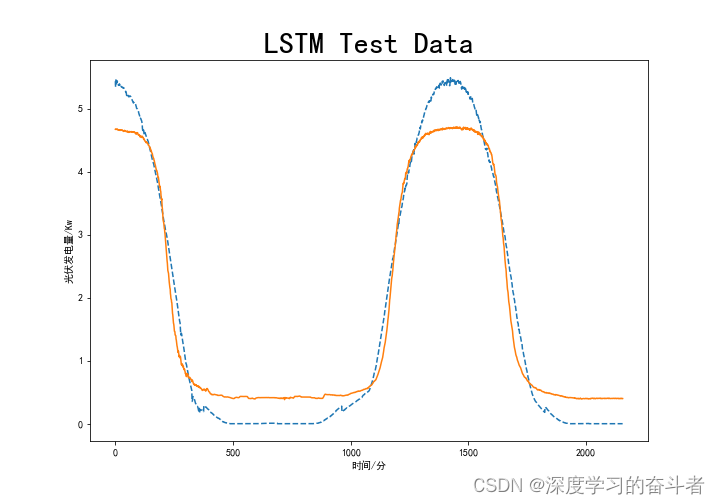
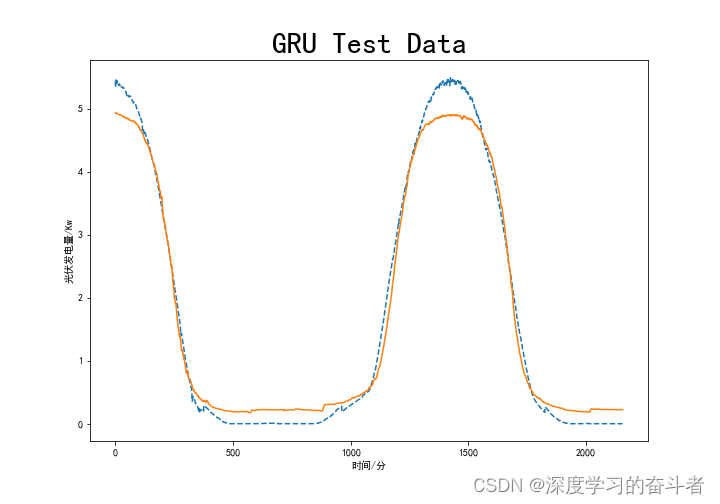
4.效果图(测试集)
LSTM
GRU
CNN-LSTM
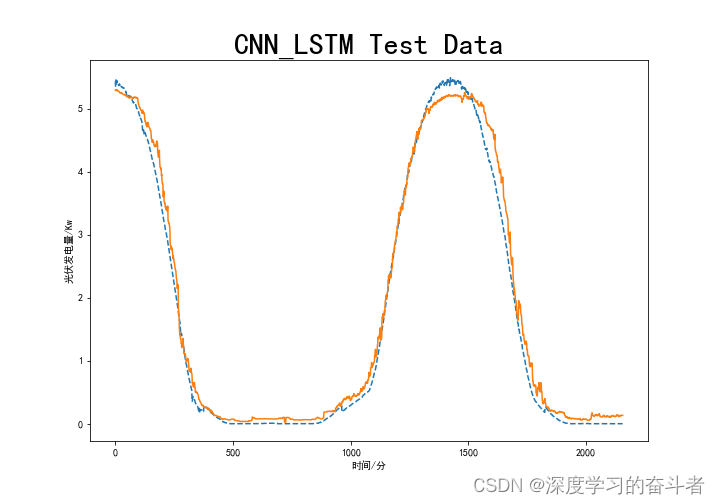
CNN-GRU
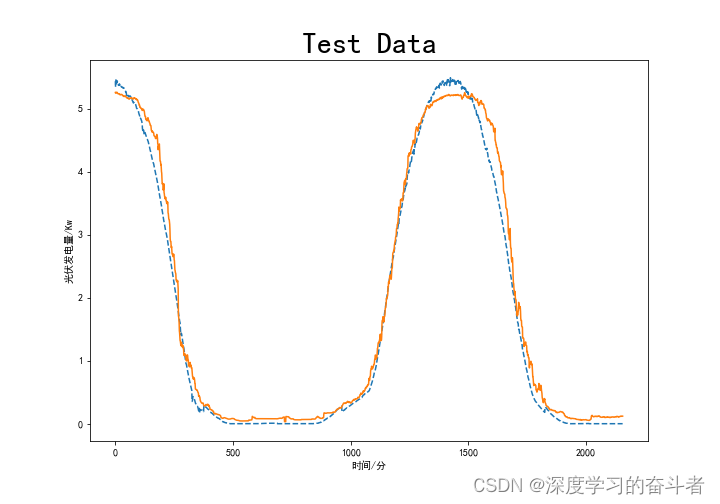
LSTM+transform
5. 对数据集和代码感兴趣的,可以关注最后一行
import sys
import numpy as np
from PIL import Image
from PyQt5.QtCore import Qt
from PyQt5.QtGui import QPainter,QPen,QImage,QPixmap,QFont,QPalette,QBrush
from PyQt5.QtWidgets import QWidget,QLabel,QPushButton,QLineEdit,QApplication,QMessageBox,QTableWidget,QTableWidgetItem
import matplotlib.pyplot as plt
import pandas as pd
#数据集和代码:https://mbd.pub/o/bread/ZpWVm5xv这篇关于基于光伏电站真实数据集的深度学习预测模型(Python代码,深度学习五个模型)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





