本文主要是介绍三篇多模态大模型进展综述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- Modality Bridging 综述
多模态大型语言模型(MLLM)可实现基于图像撰写故事和无 OCR 的数学推理,在传统方法中很少见,这表明了通向通用人工智能的潜在路径。
通常人们会在 pair 数据上进行大规模(相对于 instruction tuning)的预训练,对齐数据集通常是图像文本对或自动语音识别(ASR)数据集,它们都包含文本。对齐预训练的常见方法是保持预训练模块(例如视觉编码器和 LLMs)冻结,并训练一个可学习的接口,本文调研了到近期位置不同的接口设计以及学习方法相关的文章。Ref
论文标题:
Flamingo: a Visual Language Model for Few-Shot Learning
论文链接:
https://arxiv.org/abs/2204.14198
- 多模态大语言模型综述
论文链接:
https://arxiv.org/pdf/2306.13549.pdf
项目链接(每日更新最新论文):
https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
相比于以往的多模态方法,例如以 CLIP 为代表的判别式,或以 OFA 为代表的生成式,新兴的 MLLM 展现出一些典型的特质:(1)模型大。MLLM 通常具有数十亿的参数量,更多的参数量带来更多的潜力;(2)新的训练范式。
为了激活巨大参数量的潜力,MLLM 采用了多模态预训练、多模态指令微调等新的训练范式,与之匹配的是相应的数据集构造方式和评测方法等。
在这两种特质的加持下,MLLM 涌现出一些以往多模态模型所不具备的能力,例如给定图片进行 OCR Free 的数学推理、给定图片进行故事创作和理解表情包的深层含义等。
本综述主要包括:
-
MLLM 的基础构成与相关概念,包括架构、训练策略、数据和评测;
-
MLLM 的拓展延伸,包括输入输出粒度、模态、语言和场景的支持;
-
MLLM 的相关研究课题,包括多模态幻觉、多模态上下文学习(Multimodal In-Context Learning,M-ICL)、多模态思维链(Multimodal Chain of Thought,M-CoT)、LLM 辅助的视觉推理(LLM-Aided Visual Reasoning,LAVR)。Ref
-
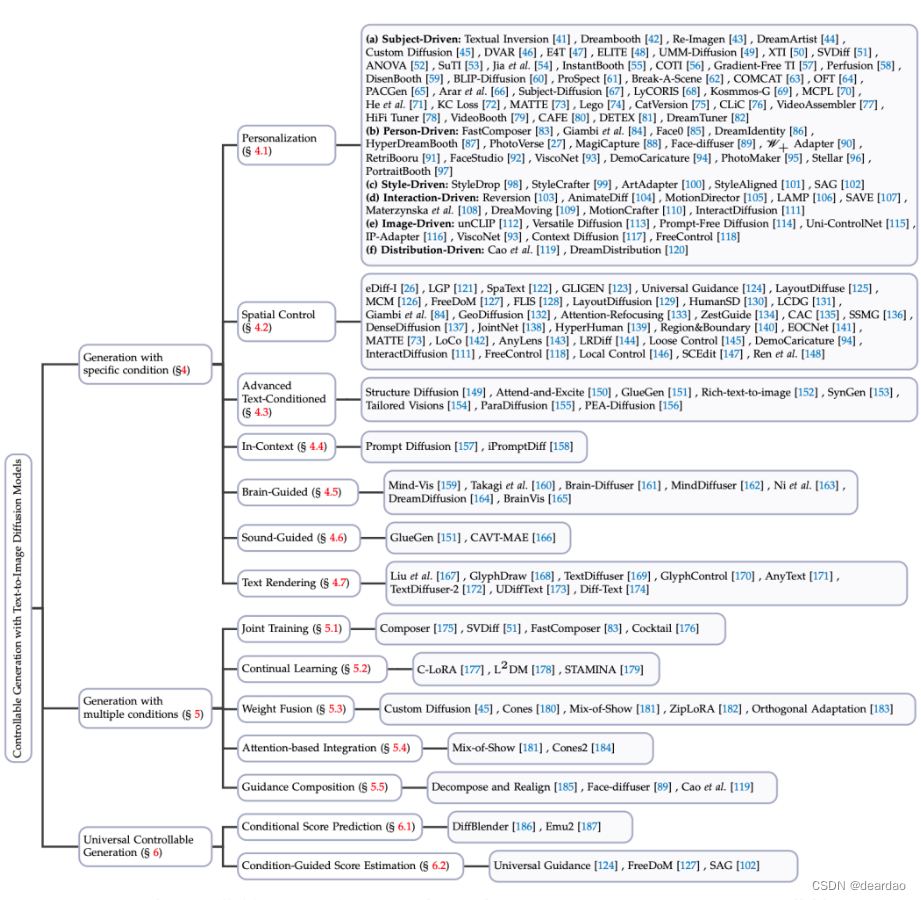
文本到图像Diffusion可控生成最新综述
论文链接:
https://arxiv.org/abs/2403.04279
代码链接:
https://github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models
Text-to-Image, T2I 引入了更多类型的条件来生成图像,具体方法包括:
Ref
这篇关于三篇多模态大模型进展综述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








