本文主要是介绍基于数据挖掘的斗鱼直播数据可视化分析系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
随着网络直播平台的兴起,斗鱼直播作为其中的佼佼者,吸引了大量用户和观众。为了更好地理解和分析斗鱼直播中的数据,本项目介绍了一个基于数据挖掘的斗鱼直播数据可视化分析系统。该系统利用Python编程语言,结合网络爬虫技术,从斗鱼直播平台抓取相关数据,并使用Pandas进行高效的数据分析处理。最终,通过Flask框架搭建Web应用,并结合ECharts实现数据的可视化展示。
B站详情与代码下载:基于数据挖掘的斗鱼直播数据可视化分析系统_哔哩哔哩_bilibili
基于数据挖掘的斗鱼直播数据可视化分析系统
2. 系统设计与实现
- 数据采集:首先,利用Python编写网络爬虫程序,对斗鱼直播平台进行数据抓取。爬虫程序能够自动访问直播间页面,提取关键信息如直播标题、观看人数、弹幕内容等。
- 数据分析:收集到的原始数据经过清洗后,使用Pandas库进行进一步的分析处理。通过对数据的统计、聚合和筛选,得到关于直播内容、主播人气和观众互动等方面的洞察。
- 系统架构:采用Flask框架构建Web应用,将分析结果以API的形式提供给前端页面。Flask的轻量级特性使得系统的开发和部署更加灵活高效。
- 数据可视化:借助ECharts图表库,在前端页面上实现数据的可视化展示。通过柱状图、折线图、饼图等多种图表形式,直观地呈现分析结果,帮助用户快速把握数据背后的规律和趋势。
3. 直播数据网络爬虫
本次我们采集的数据是播酱网下斗鱼平台的主播直播数据,且该网站关于主播直播数据的展示是以月报的形式进行展示的,所以我们就可以确定本次采集的目标网址为该网站下直播平台的直播月报的网址。
for page in range(1, 151):print("采集 {} 的斗鱼直播数据,page: {}".format(month, page))url = base_url.format(month, page, page_size)resp = requests.get(url, headers=headers)resp = resp.json()batch_insert = []for data in resp['data']['rows']:# 处理“直播时长”的数据类型duration = data['duration'].split(":")[-1].replace('小时', '')info = {# 主播账号名称"name": data['name'],# 主播头像"avator": data['avator'],# 直播类别"cate_name": data['cate_name'],# 主播所属公会"club_name": data['club_name'],# 活跃观众"audience_count": data["audience_count"],# 弹幕数量"danmu_count": data["danmu_count"],# 礼物总值"yc_gift_value": float(data['yc_gift_value']),# 峰值热度"hn_max": data['hn_max'],# 弹幕人数"danmu_person_count": data['danmu_person_count'],# 礼物人数"gift_person_count": data['gift_person_count'],# 单月直播时长"duration": float(duration),# 月份"month": data['month']}batch_insert.append(list(info.values()))print(info)if batch_insert:cursor.executemany(insert_sql, batch_insert)conn.commit()batch_insert.clear()4. 直播数据可视化分析系统
4.1 系统首页

4.2 直播类型与签约公会分析
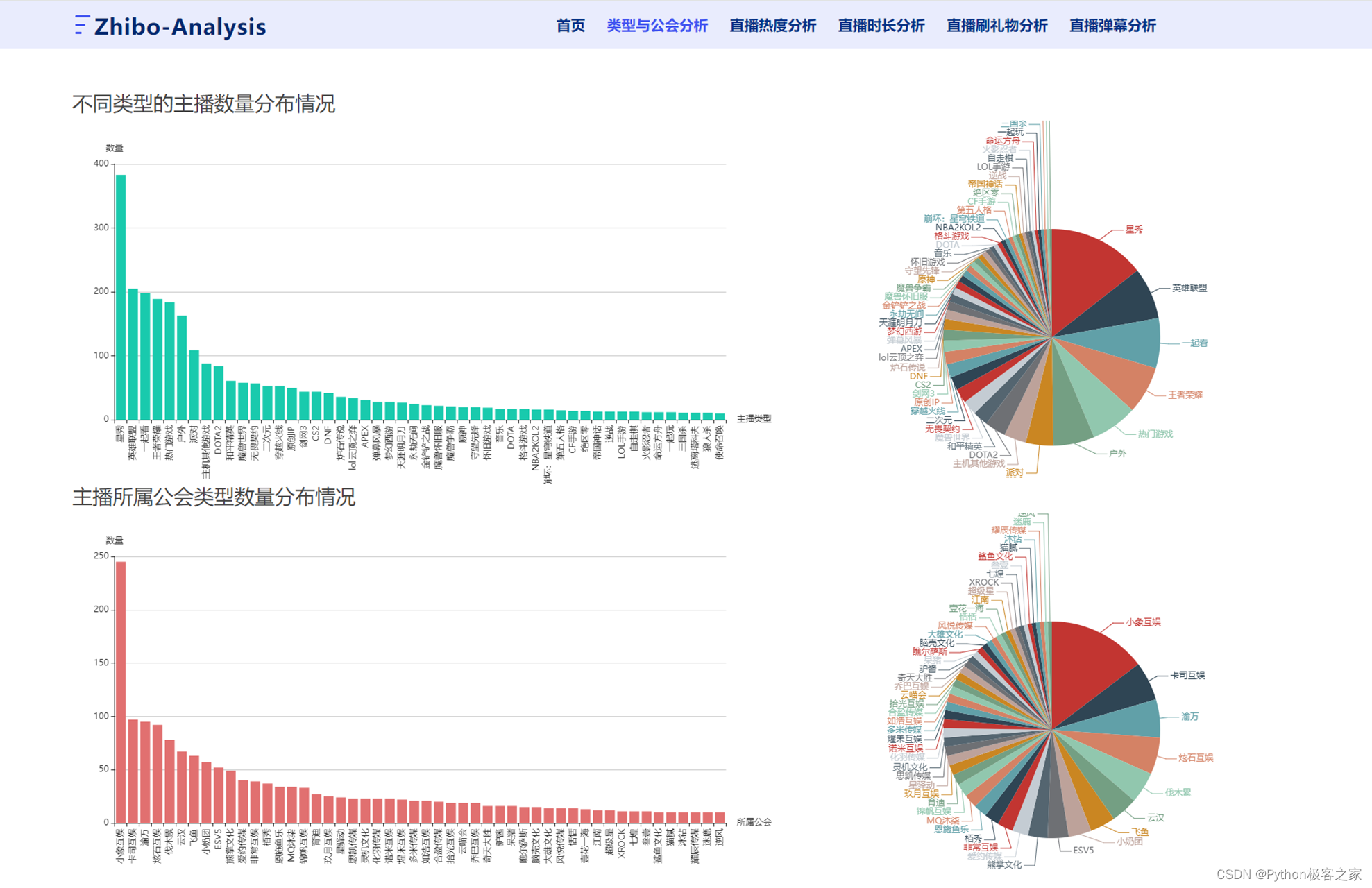
4.3 直播热度分析
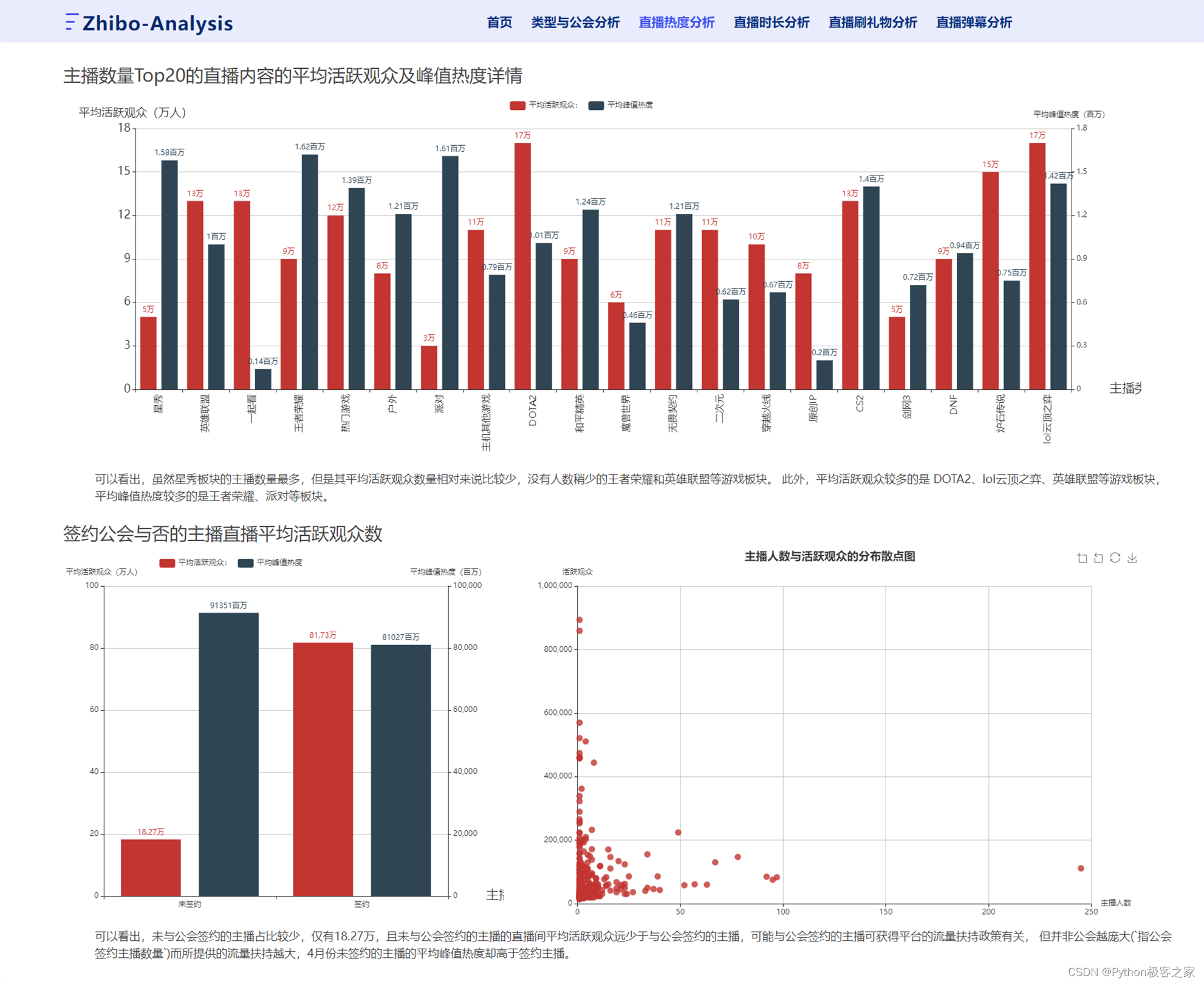
可以看出,虽然星秀板块的主播数量最多,但是其平均活跃观众数量相对来说比较少,没有人数稍少的王者荣耀和英雄联盟等游戏板块。 此外,平均活跃观众较多的是 DOTA2、lol云顶之弈、英雄联盟等游戏板块,平均峰值热度较多的是王者荣耀、派对等板块。未与公会签约的主播占比较少,仅有18.27万,且未与公会签约的主播的直播间平均活跃观众远少于与公会签约的主播,可能与公会签约的主播可获得平台的流量扶持政策有关, 但并非公会越庞大(`指公会签约主播数量`)而所提供的流量扶持越大,4月份未签约的主播的平均峰值热度却高于签约主播。
4.4 直播时长分析
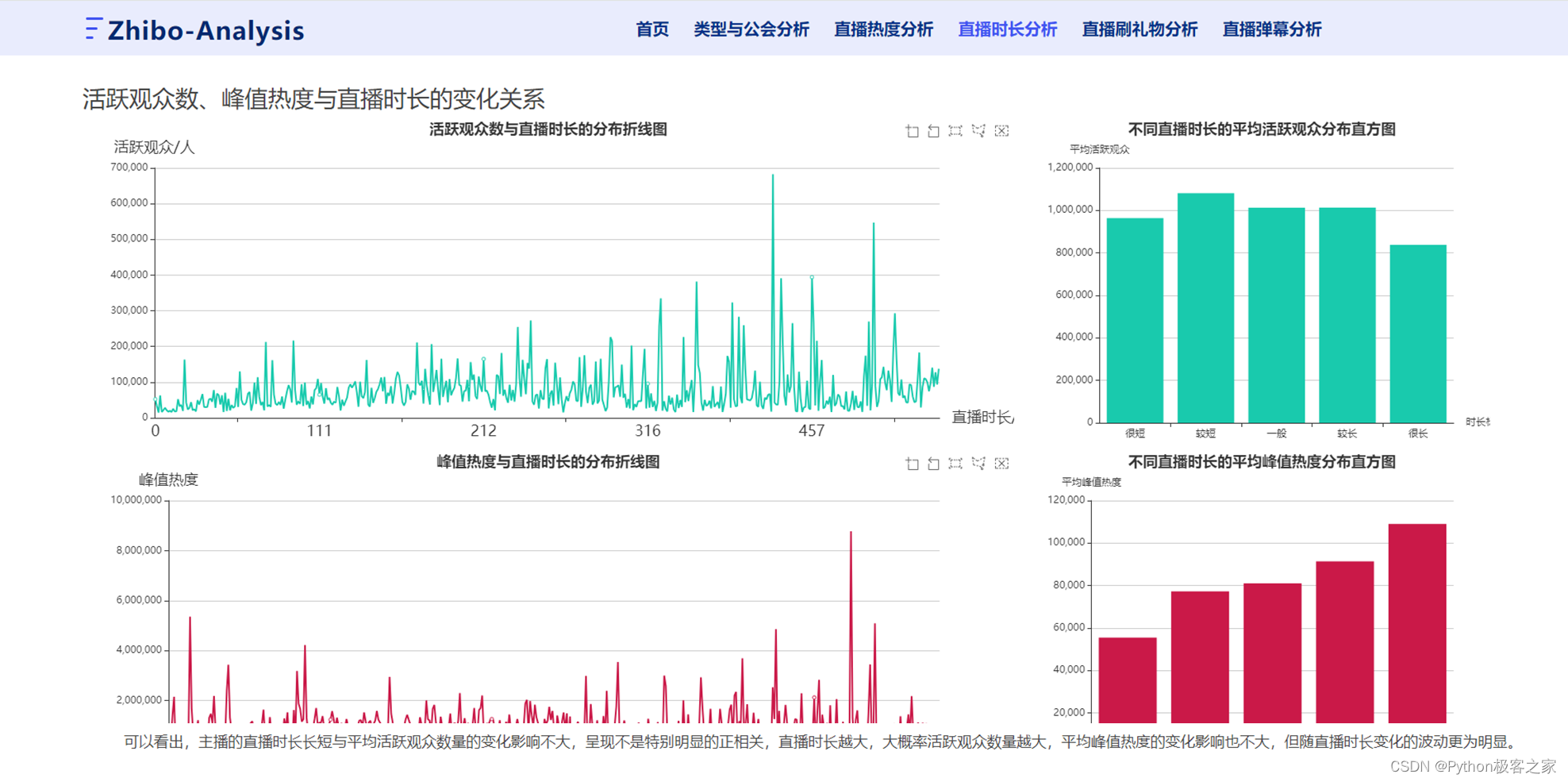
可以看出,主播的直播时长长短与平均活跃观众数量的变化影响不大,呈现不是特别明显的正相关,直播时长越大,大概率活跃观众数量越大,平均峰值热度的变化影响也不大,但随直播时长变化的波动更为明显。
4.5 直播刷礼物分析
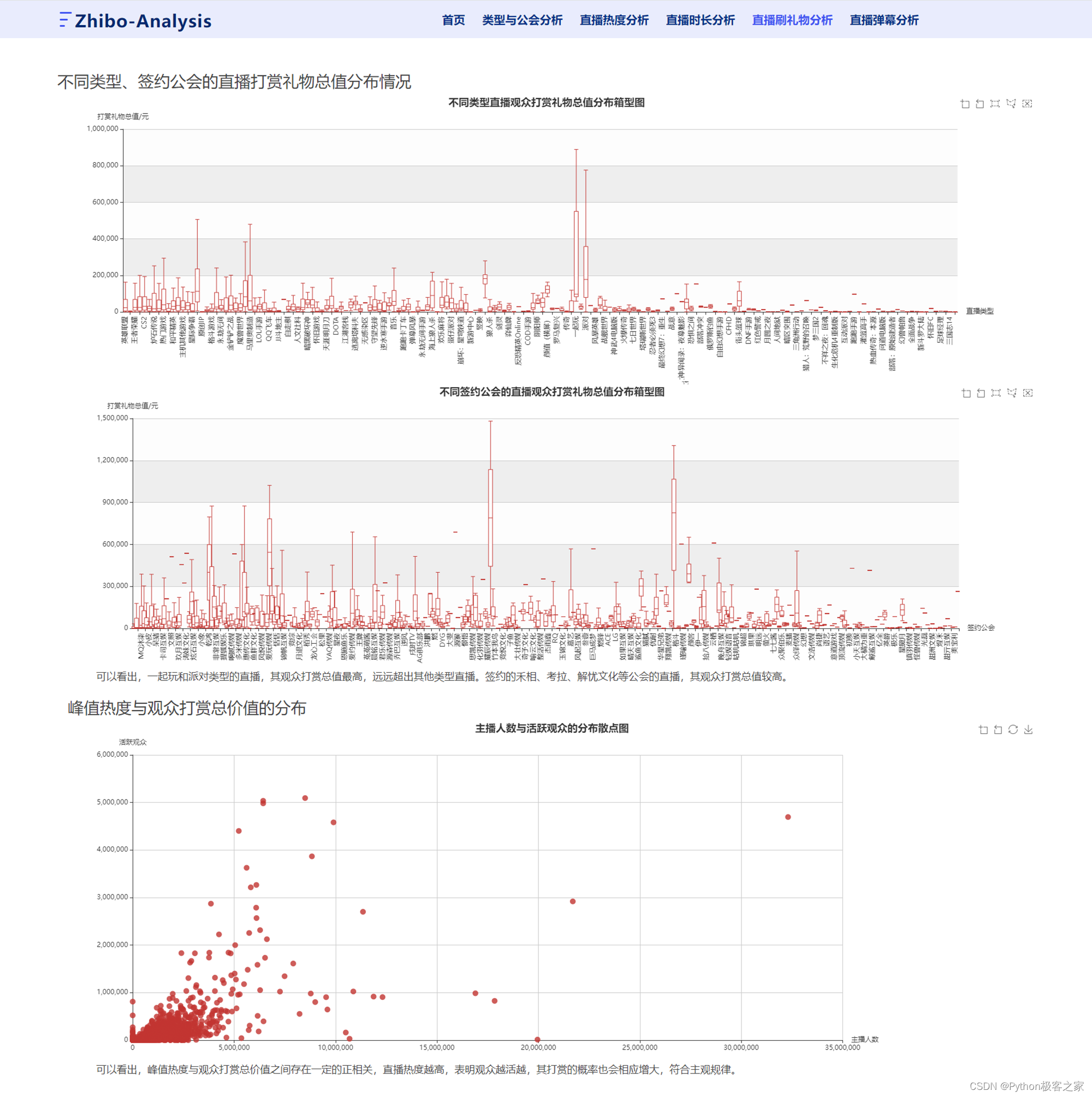
可以看出,一起玩和派对类型的直播,其观众打赏总值最高,远远超出其他类型直播。签约的禾相、考拉、解忧文化等公会的直播,其观众打赏总值较高。峰值热度与观众打赏总价值之间存在一定的正相关,直播热度越高,表明观众越活越,其打赏的概率也会相应增大,符合主观规律。
4.6 直播弹幕分析
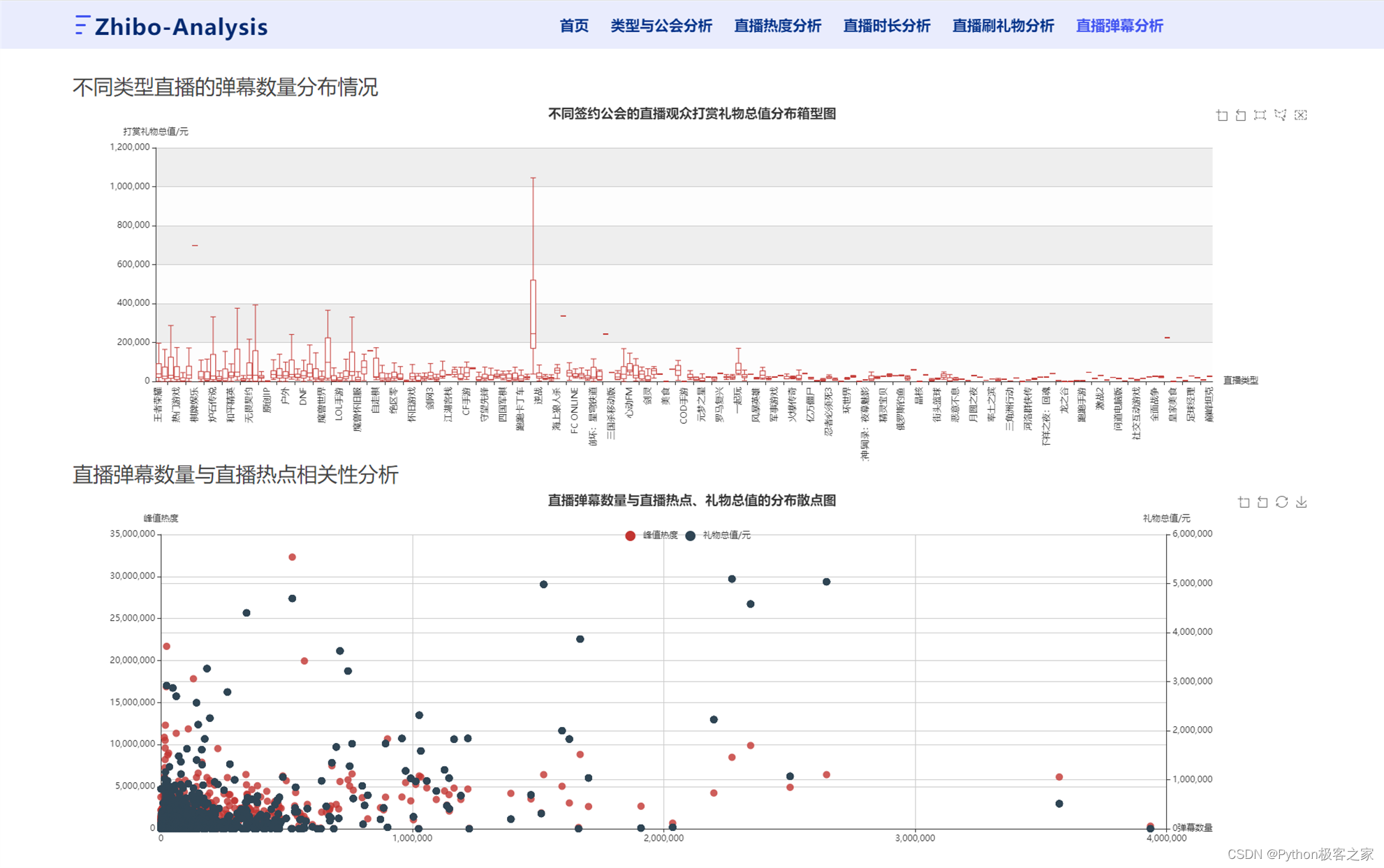
5. 总结
本项目介绍了一个基于数据挖掘的斗鱼直播数据可视化分析系统。该系统利用Python编程语言,结合网络爬虫技术,从斗鱼直播平台抓取相关数据,并使用Pandas进行高效的数据分析处理。最终,通过Flask框架搭建Web应用,并结合ECharts实现数据的可视化展示。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
1. Python数据挖掘精品实战案例
2. 计算机视觉 CV 精品实战案例
3. 自然语言处理 NLP 精品实战案例

这篇关于基于数据挖掘的斗鱼直播数据可视化分析系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







