本文主要是介绍Stability AI 推出稳定音频 2.0:为创作者提供先进的 AI 生成音频 - Circle 阅读助手,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概述
Stability AI 的发布再次突破了创新的界限。这一尖端模型以其前身的成功为基础,引入了一系列突破性的功能,有望彻底改变艺术家和音乐家创建和操作音频内容的方式。
Stable Audio 2.0 代表了人工智能生成音频发展的一个重要里程碑,为质量、多功能性和创意潜力设定了新标准。该模型能够生成完整长度的曲目、使用自然语言提示转换音频样本以及产生各种音效,为各行业的内容创作者开辟了一个充满可能性的世界。
随着对创新音频解决方案的需求不断增长,Stability AI 的最新产品有望成为寻求增强创意输出和简化工作流程的专业人士不可或缺的工具。通过利用先进人工智能技术的力量,Stable Audio 2.0使用户能够探索音乐创作、声音设计和音频后期制作方面的未知领域。
Stable Audio 2.0特点如下:
-
创新突破:Stable Audio 2.0 似乎在人工智能生成音频领域取得了重大进展,这可能会对音乐制作和音频处理产生深远的影响。
-
多功能性:该模型不仅能够生成完整的曲目,还能根据自然语言的提示转换音频样本,并产生各种音效,显示了其多功能性。
-
创意潜力:通过这些新功能,艺术家和音乐家可以探索新的创意领域,这可能会激发新的音乐风格和音频应用的诞生。
-
行业应用:Stable Audio 2.0 为不同行业的专业人士提供了工具,帮助他们增强创意输出并简化工作流程,这可能包括音乐制作、电影和视频游戏的声音设计,以及音频后期制作等。
-
技术力量:利用先进的人工智能技术,Stable Audio 2.0 为用户提供了探索音乐创作和声音设计新领域的能力。
音频到音频功能演示:
人工智能Stability AI 推出稳定音频 2.0
2.0的特点
Stable Audio 2.0 拥有一系列令人印象深刻的功能,可以重新定义人工智能生成音频的格局。从完整长度的音轨生成到音频到音频的转换、增强的音效制作和风格转换,该模型为创作者提供了一个全面的工具包,将他们的听觉视觉变为现实。
全长轨道生成
Stable Audio 2.0 与其他人工智能生成的音频模型不同,它能够创建长达三分钟的完整曲目。这些作品不仅仅是扩展的片段,而是结构化的片段,包括不同的部分,例如前奏、展开和结尾。此功能允许用户生成具有连贯叙事和进展的完整音乐作品,从而提升了人工智能辅助音乐创作的潜力。
此外,该模型还结合了立体声效果,为生成的音频增加了深度和维度。这种空间元素的包含进一步增强了曲目的真实感和沉浸感质量,使其适用于从视频中的背景音乐到独立音乐作品的广泛应用。
音频到音频生成
Stable Audio 2.0 最令人兴奋的新增功能之一是音频到音频生成功能。用户现在可以上传自己的音频样本并使用自然语言提示进行转换。此功能开辟了一个充满创意可能性的世界,使艺术家和音乐家能够以以前难以想象的方式尝试声音操纵和再生。
通过利用人工智能的力量,用户可以轻松修改现有的音频资产,以满足他们的特定需求或艺术愿景。无论是改变乐器的音色、改变乐曲的基调,还是根据现有样本创建全新的声音,Stable Audio 2.0 都提供了一种探索音频转换的直观方法。
增强音效制作
除了音乐生成功能外,Stable Audio 2.0 在创建多样化音效方面也表现出色。从树叶的沙沙声或机械的嗡嗡声等微妙的背景噪音,到熙熙攘攘的城市街道或自然环境等更加身临其境和复杂的音景,该模型可以生成各种音频元素。
这种增强的音效制作功能对于从事电影、电视、视频游戏和多媒体项目的内容创作者来说尤其有价值。借助 Stable Audio 2.0,用户可以快速轻松地生成高质量的音效,否则需要大量的拟音工作或昂贵的许可资产。
风格转移
Stable Audio 2.0 引入了风格转换功能,允许用户无缝修改生成或上传的音频的美感和音质。此功能使创作者能够定制音频输出,以匹配其项目的特定主题、流派或情感基调。
通过应用风格迁移,用户可以尝试不同的音乐风格、混合流派或创建全新的声音调色板。此功能对于创建有凝聚力的音轨、调整音乐以适应特定的视觉内容或探索创意混搭和混音特别有用。
3.技术特点
在底层,Stable Audio 2.0 由尖端的人工智能技术提供支持,使其具有令人印象深刻的性能和高质量的输出。该模型的架构经过精心设计,可以应对生成连贯、完整长度的音频作品的独特挑战,同时保持对细节的细粒度控制。
潜在扩散模型架构
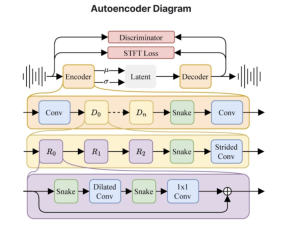
Stable Audio 2.0 的核心是一个针对音频生成进行了优化的潜在扩散模型架构。该架构由两个关键组件组成:高度压缩的 自动编码器 的网络 扩散变压器 (迪特)。
自动编码器负责有效地将原始音频波形压缩为紧凑的表示形式。这种压缩允许模型捕获音频的基本特征,同时过滤掉不太重要的细节,从而产生更加连贯和结构化的生成输出。
扩散变压器与 Stability AI 突破性的 Stable Diffusion 3 模型中使用的扩散变压器类似,取代了之前版本中使用的传统 U-Net 架构。 DiT 特别擅长处理长数据序列,使其非常适合处理和生成扩展音频作品。
提高性能和质量
高度压缩的自动编码器和扩散变压器的结合使稳定音频2.0与其前身相比在性能和输出质量方面取得了显着的改进。
自动编码器的高效压缩使模型能够以更快的速度处理和生成音频,减少所需的计算资源,并使更广泛的用户更容易使用。同时,扩散变压器识别和再现大型结构的能力确保生成的音频保持高水平的连贯性和音乐完整性。
这些技术进步最终形成了一个模型,该模型可以生成极其逼真且情感共鸣的音频,无论是完整的音乐作品、复杂的音景还是微妙的音效。 Stable Audio 2.0 的架构为人工智能生成音频的未来创新奠定了基础,为创作者提供更复杂、更具表现力的工具铺平了道路。
4.创作者权利
随着人工智能生成的音频不断发展并变得更加容易获取,解决道德影响并确保创作者的权利受到保护至关重要。 Stability AI 已采取积极主动的措施,优先考虑道德发展和对为 Stable Audio 2.0 培训做出贡献的艺术家的公平报酬。
Stable Audio 2.0 专门在 AudioSparx 的许可数据集上进行训练,AudioSparx 是一个著名的高质量音频内容来源。该数据集包含超过 800,000 个音频文件,包括音乐、音效和单乐器主干,以及相应的文本元数据。通过使用许可的数据集,Stability AI 确保模型建立在合法获得且适当归属的音频数据的基础上。
认识到创作者自主权的重要性,Stability AI 为所有作品包含在 AudioSparx 数据集中的艺术家提供了选择不将其音频用于 Stable Audio 2.0 训练的机会。这种选择退出机制允许创作者保持对其作品使用方式的控制,并确保只有那些对将音频用于人工智能训练感到满意的人才会包含在数据集中。
Stability AI 致力于确保为 Stable Audio 2.0 的发展做出贡献的创作者的努力得到公平的补偿。通过授权 AudioSparx 数据集并提供退出选项,该公司展示了其致力于为人工智能生成的音频建立可持续且公平的生态系统的决心,在这个生态系统中,创作者的贡献将受到尊重和奖励。
为了进一步保护创作者的权利,防止版权侵权,Stability AI 与领先的内容识别技术提供商 Audible Magic 合作。通过将 Audible Magic 的高级内容识别 (ACR) 系统集成到音频上传过程中,Stable Audio 2.0 可以识别并标记任何潜在的侵权内容,确保在平台内仅使用原始或经过适当许可的音频。
通过这些道德考虑和以创作者为中心的举措,Stability AI 为音频领域负责任的 AI 开发树立了良好的先例。通过优先考虑创作者的权利并制定明确的数据使用和补偿准则,该公司营造了一个协作和可持续的环境,让人工智能和人类创造力能够共存和繁荣。
5.音频创作的未来
Stable Audio 2.0 标志着人工智能生成音频的一个重要里程碑,为创作者提供了一整套工具来探索音乐、声音设计和音频制作的新领域。凭借其尖端的潜在扩散模型架构、令人印象深刻的性能以及对道德考虑和创作者权利的承诺,Stability AI 处于塑造音频创作未来的最前沿。随着这项技术的不断发展,人工智能生成的音频显然将在创意领域发挥越来越关键的作用,为艺术家和音乐家提供他们所需的工具,以突破他们的工艺界限并重新定义世界的可能性的声音。
这篇关于Stability AI 推出稳定音频 2.0:为创作者提供先进的 AI 生成音频 - Circle 阅读助手的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





