本文主要是介绍可以在手机端运行的大模型标杆:微软发布第三代Phi-3系列模型,评测结果超过同等参数规模水平,包含三个版本,最小38亿,最高140亿参数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文原文来自DataLearnerAI官方网站:
可以在手机端运行的大模型标杆:微软发布第三代Phi-3系列模型,评测结果超过同等参数规模水平,包含三个版本,最小38亿,最高140亿参数 | 数据学习者官方网站(Datalearner)![]() https://www.datalearner.com/blog/1051713851616894
https://www.datalearner.com/blog/1051713851616894
Phi系列大语言模型是微软开源一个小规模参数的语言模型。第一代和第二代的Phi模型参数规模都不超过30亿,但是在多个评测结果上都取得了非常亮眼的成绩。今天,微软发布了第三代Phi系列大模型,最高参数规模也到了140亿,其中最小的模型参数38亿,评测结果接近GPT-3.5的水平。

- Phi系列模型简介
- 第三代Phi-3模型简介
- Phi-3系列模型评测结果接近GPT-3.5
- Phi-3系列的开源情况
Phi系列模型简介
大语言模型的一个重要应用方向就是在手机端运行。为此,30亿参数规模几乎是上限(超过这个规模的模型,需要通过量化等手段牺牲模型性能)。在这其中,微软的Phi系列模型是最具有竞争力的。
Phi系列模型的目的是希望在小规模参数的模型上获得传统大模型的能力。微软发布了第三代Phi模型,这一代的模型最小参数38亿,最大规模拓展到了140亿,包含3个版本,分别是Phi-mini-3.8B、Phi-small-7B和Phi-medium-14B。参数规模增长的同时,能力也大幅提高。
第三代Phi-3模型简介
第三代的Phi模型是微软继续探索小规模参数语言模型的成果。尽管Phi-3包含了70亿和140亿两个较大规模版本的模型。但是最小的38亿参数模型依然可以在手机端运行。
Phi-3-mini-3.8B模型采用了transformer的decoder架构,默认上下文长度是4K,采用了和Llama-2类似的block结构,使用同样的tokenizer,词汇表大小为32064。因此,任何为Llama2开发的工具套件几乎可以直接应用在phi-3-mini上,这个模型训练数据量达到了3.3万亿tokens。
Phi-3-small-7B是新增的一个更大规模参数版本的Phi模型,参数70亿,但是tokenizer换成了tiktoken,使之有更好的多语言能力,词汇表大小也拓展到了100352,默认上下文长度是8K,模型也有分组查询注意力机制(Group Query Attention,GQA),从这个变化看,和Llama3的架构非常接近(Llama3的详细分析参考:开源王者!全球最强的开源大模型Llama3发布!15万亿数据集训练,最高4000亿参数,数学评测超过GPT-4,全球第二! | 数据学习者官方网站(Datalearner) )。模型的数据训练量达到了4.8万亿tokens。
Phi-3还有一个140亿参数规模的Phi-3-medium-14B版本,架构与最小的Phi-3-mini-3.8B相同,但是训练的epoch更多,训练的数据量和Phi-3-small一样,4.9万亿tokens。但是这个模型比Phi-3-small-7B的提升不如Phi-3-small-7B相比Phi-3-mini-3.8B提升多。作者认为可能是数据问题,所以后面他们还会改进,因此,把这个Phi-3-medium-14B称为preview版本。
Phi-3模型系列更多的详情参考DataLearnerAI模型信息卡地址:
| 模型版本 | Phi3模型信息卡地址 |
|---|---|
| Phi3-mini | Phi-3-mini 3.8B(Phi-3-mini 3.8B)详细信息 | 名称、简介、使用方法,开源情况,商用授权信息 | 数据学习(DataLearner) |
| Phi3-small | Phi-3-small 7B(Phi-3-small 7B)详细信息 | 名称、简介、使用方法,开源情况,商用授权信息 | 数据学习(DataLearner) |
| Phi3-medium-preview | Phi-3-medium 14B-preview(Phi-3-medium 14B-preview)详细信息 | 名称、简介、使用方法,开源情况,商用授权信息 | 数据学习(DataLearner) |
Phi-3系列模型评测结果接近GPT-3.5
Phi系列模型的评测结果一直非常优秀,尽管在复杂任务上与大规模参数版本的大模型有差距,但是作为一个几十亿参数模型来说,已经表现很不错了。
本次第三代Phi模型的提升也比较大。首先,我们看一下在30亿参数规模左右模型的对比结果:
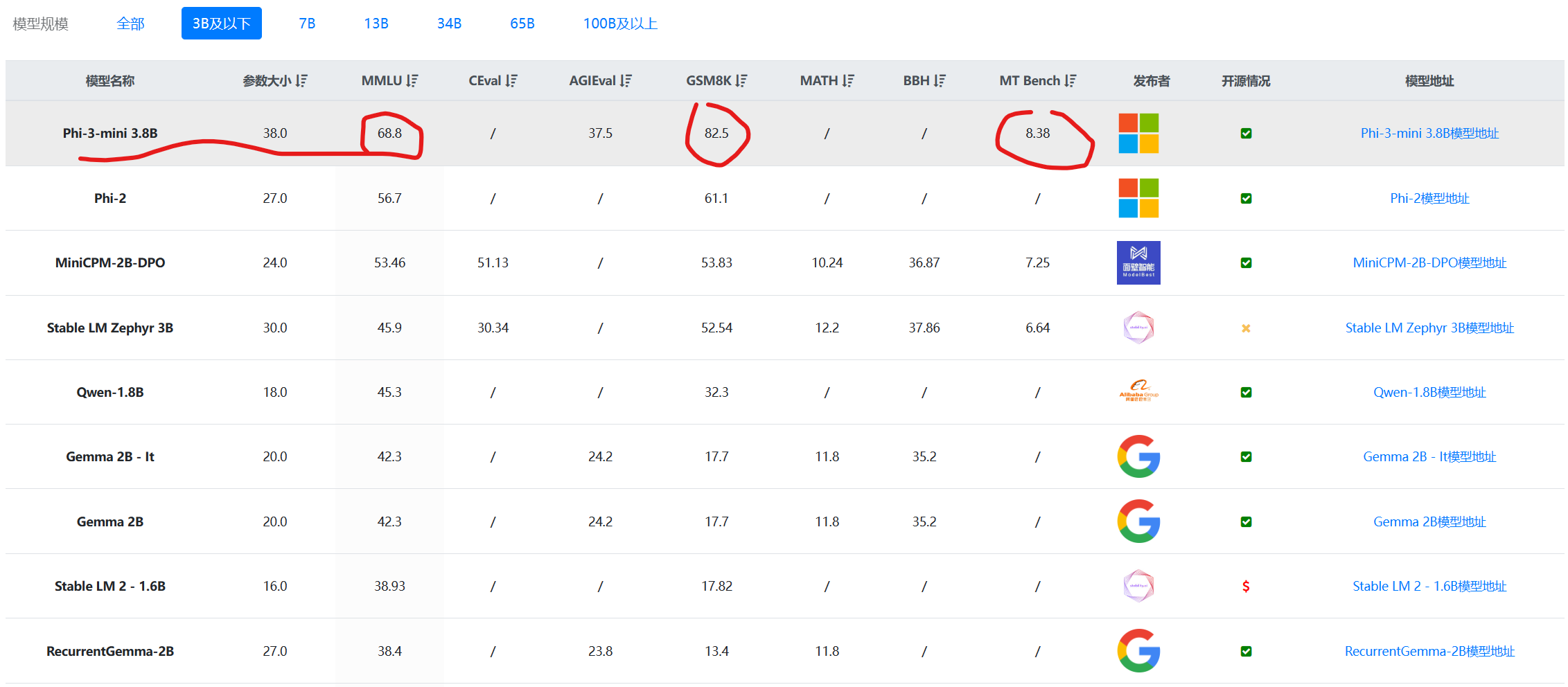
数据来源:30亿参数规模大模型综合评测对比 | 当前主流大模型在各评测数据集上的表现总榜单 | 数据学习 (DataLearner)
上图是DataLearnerAI收集的30亿参数以下大模型评测对比结果。可以看到,Phi-3-mini-3.8B得分远超其它同等参数规模的模型,效果非常好。而且不仅仅是MMLU的综合评测理解上,在数学推理GSM8K以及MT-Bench上表现也非常好。其70亿参数规模版本的模型在MMLU测评上甚至超过了Anthropic旗下的Claude3-Haiku模型!
如果不限制参数规模,与所有其它模型相比,Phi-3-medium超过了此前Mixtral-8×22B-MoE模型,表现非常亮眼:
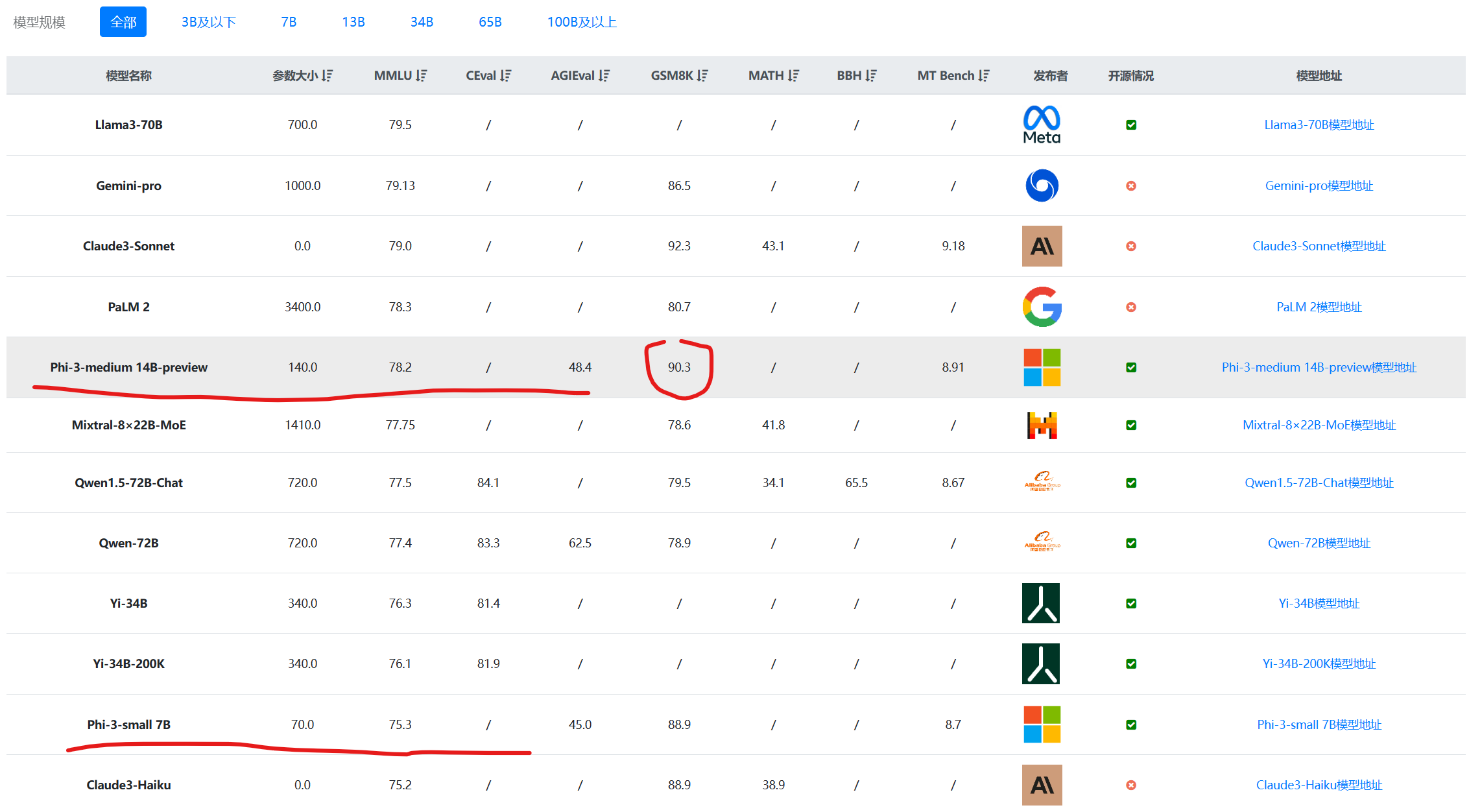
数据来源L:大模型综合评测对比 | 当前主流大模型在各评测数据集上的表现总榜单 | 数据学习 (DataLearner)
在编程评测HumanEval上,这三个模型相差不大,甚至最大的140亿参数规模的Phi-3-medium-14B水平表现略有下降,十分奇怪:
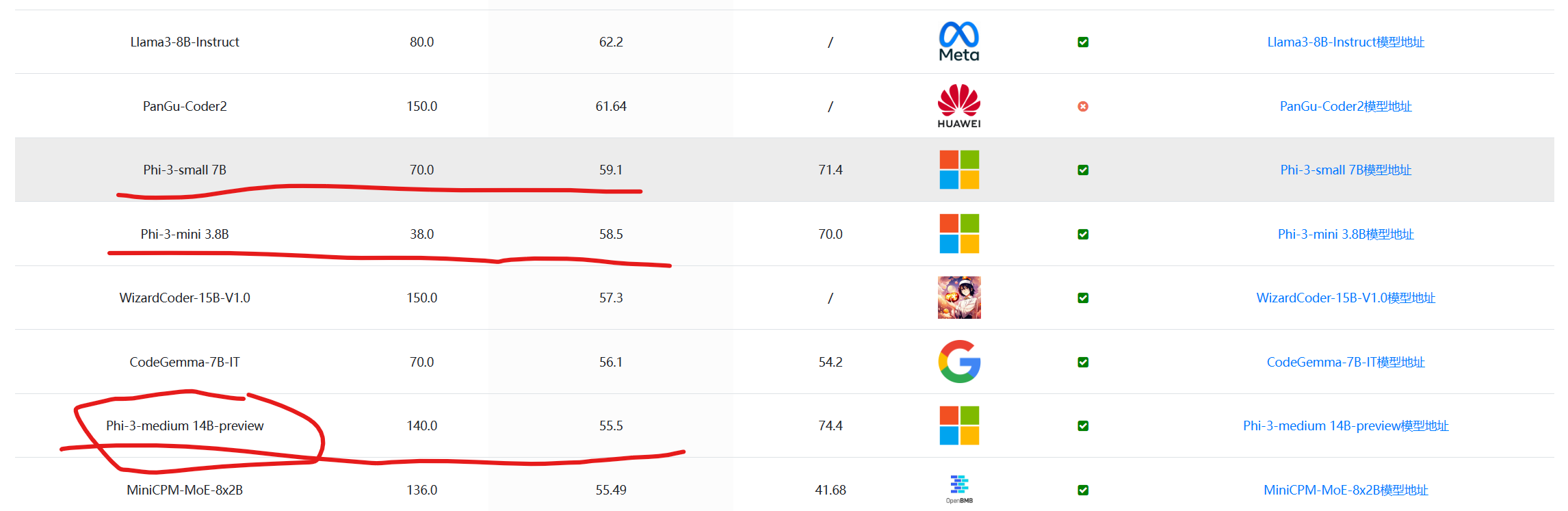
数据来源:大模型代码能力评测对比 | 当前主流大模型在代码能力上的表现总榜单 | 数据学习 (DataLearner)
从这些评测结果看,Phi-3模型的变现十分优秀。不过,有争议的是Phi系列模型一直因为评测结果很高但是参数量很少受到质疑。其实,从现在的情况看,因为大多数评测的数据过于陈旧,导致模型评测结果的区分度已经降低。而且很多模型都会在有监督微调(SFT)阶段针对性的做微调,会导致评测分数虚高。不过,从侧面看,在30亿参数规模的模型中,Phi系列一直是标杆,还是值得关注的。
Phi-3系列的开源情况
目前,Phi-3系列模型只发布了论文信息,还没有预训练结果发布。大家关注DataLearnerAI的模型信息卡可以获取后续的情况。根据Phi-2模型发布的情况看,最早Phi2模型是不可以商用的,但是过了一段时间,开源协议改成MIT开源协议,没有任何商用限制。Phi-3可以期待也是类似的开源协议。
这篇关于可以在手机端运行的大模型标杆:微软发布第三代Phi-3系列模型,评测结果超过同等参数规模水平,包含三个版本,最小38亿,最高140亿参数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





