本文主要是介绍刷题日记 ---- 顺序表与链表相关经典算法题(C语言版),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 1. 移除元素
- 2. 合并两个有序数组
- 3. 移除链表元素
- 4. 反转链表
- 5. 合并两个有序链表
- 6. 链表的中间结点
- 7. 环形链表的约瑟夫问题
- 8. 分割链表
- 总结
正文开始
1. 移除元素
题目链接: 移除元素
题目描述:

思路历程:
题目明确要求, 不能使用额外的数组空间, 也就是说不可以创建一个新的数组. 可以使用双指针法, 一个指向源数组, 一个指向目标数组, 定义两个下标, 分别从第一个元素开始向后遍历, 当src所在位置的数组值等于val时, 跳过此元素, 当src指向的数组不等于val值时, 将src位置的元素存放到dst位置, 继续向后遍历, 当遍历到数组结尾, 跳出循环, 此时dst内存放的就是不含val值的数组.
代码描述:
int removeElement(int* nums, int numsSize, int val) {int src = 0;int dst = 0;while(src<numsSize){if(nums[src] == val)src++;else{nums[dst] = nums[src];dst++;src++;}}return dst;
}
2. 合并两个有序数组
题目链接: 合并两个有序数组
题目描述:

思路历程:
非递减序, 即递增的序列, 定义三个指针, 分别指向第一个数组有效元素的最后一个元素, 第二个数组的最后一个元素, 第一个数组最后的一个位置, 分别为src1 , src2 , dst,
不能采用从前往后遍历, 这样会覆盖掉src1中的内容, 所以从后往前遍历, 创建三个下标, 如果第一个数组元素大于第二个数组元素就方法最后一个位置, 继续向前遍历, 反之亦然, 当跳出循环后, 如果第一个数组还有元素不必理会, 第二个数组还有元素就直接同上直接放到dst里面.
画图演示:
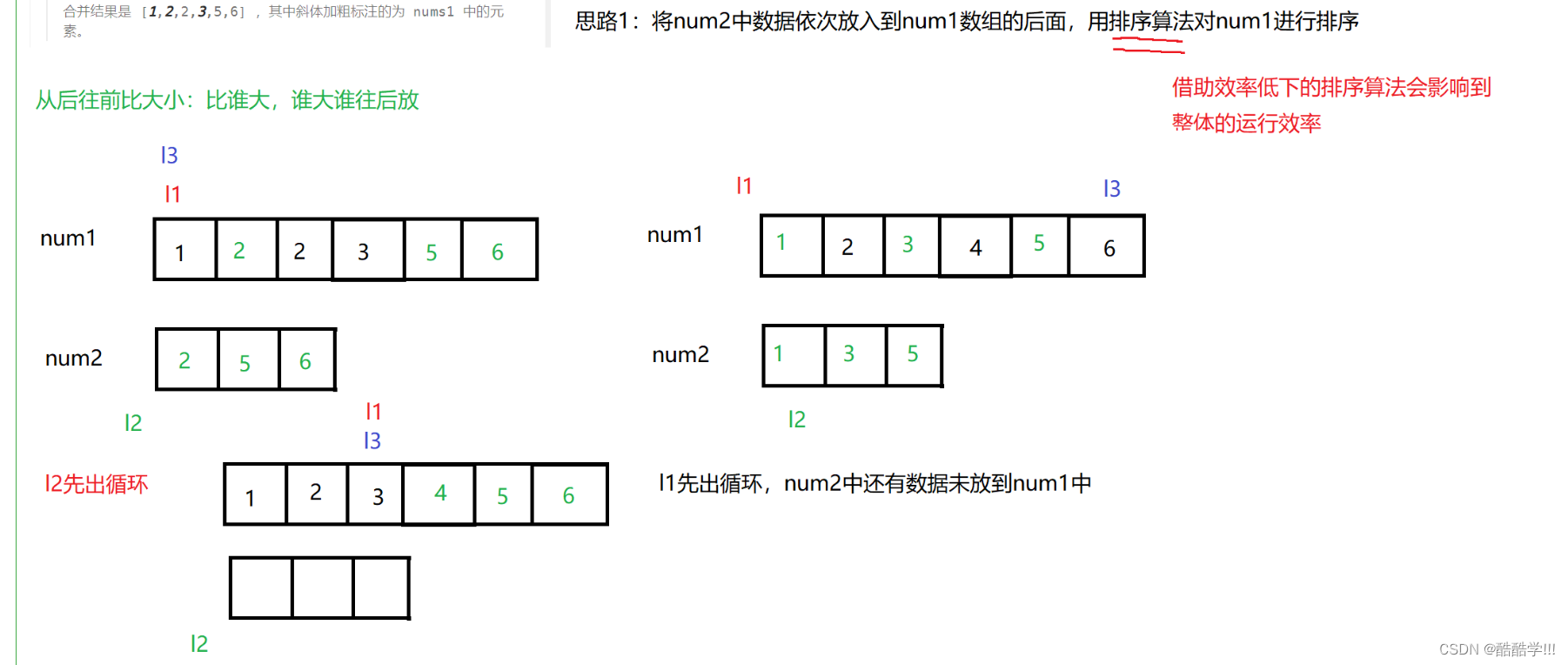
代码描述:
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n) {int src1 = m-1;int src2 = n-1;int dst = m+n-1;while(src1>=0&&src2>=0){if(nums1[src1]>nums2[src2]){nums1[dst--] = nums1[src1--];}else{nums1[dst--] = nums2[src2--];}}while(src2>=0){nums1[dst--] = nums2[src2--];}
}
3. 移除链表元素
题目链接: 移除链表元素
题目描述:
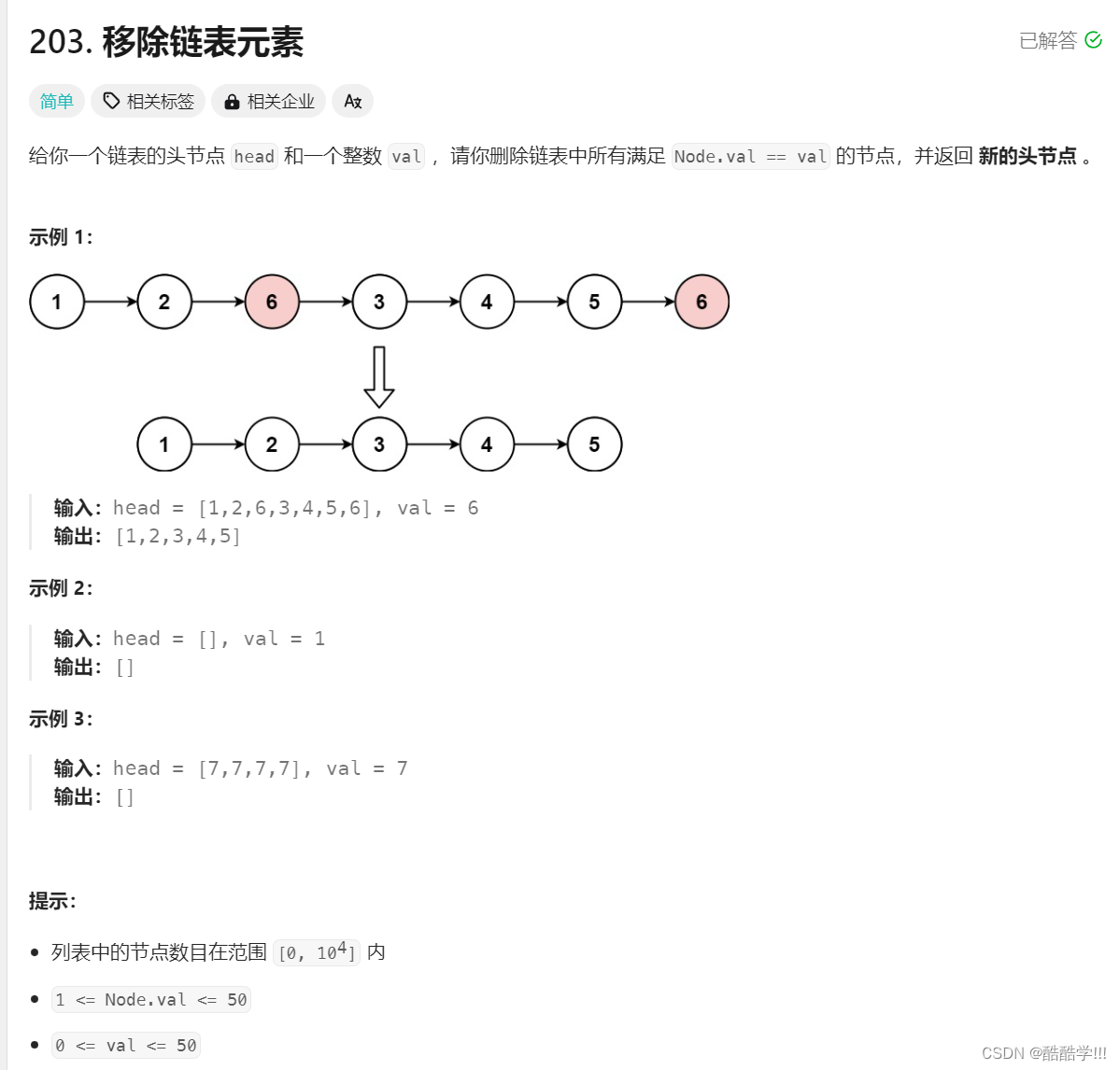
思路历程:
创建一个新的链表, 遍历原链表, 当值不为val时将此节点插入到新的链表中, 为了防止出现链表为NULL会对空指针解引用, 直接创建带头链表, 给上一个哨兵位, 初始化时直接将新链表的next指向NULL, 然后开始循环遍历原链表, 值不相等的时候插入到新的链表中.
切记: 当遍历完成后将新链表的尾指针的指向改为NULL, 不然可能会出现如下情况
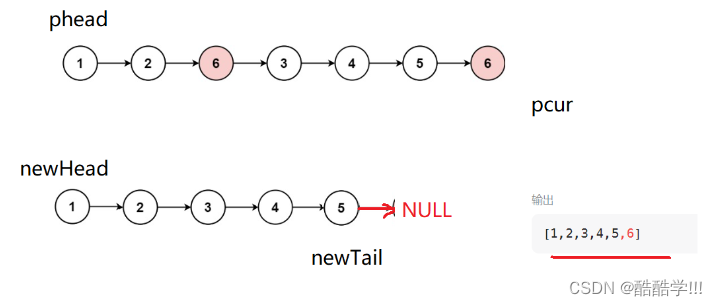
代码描述:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
#include<stdlib.h>
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val) {ListNode* newHead = (ListNode*)malloc(sizeof(ListNode));newHead->next = NULL;ListNode* newTail = newHead;ListNode* pcur = head;while(pcur){if(pcur->val!=val){newTail->next = pcur;newTail = newTail->next;}pcur = pcur->next;}newTail->next = NULL;return newHead->next;
}
4. 反转链表
题目链接: 反转链表
题目描述:

思路历程:
本题有两种思路, 第一种思路是创建一个新的链表, 将原链表头插, 不够还有另外一种更简单的思路, 直接完成原链表的翻转, 首先创建三个指针变量, 分别指向NULL, 一个元素, 和第一个元素的下一个结点, 只需要每次改变n2让他指向n1, 并且保障下一个结点地址不被丢失, 用n3来记录, 每次遍历一次之后, 继续让n2的next指向n1 , 指向完之后, 让n1 来到 n2, n2 来到n3, n3指向下一个结点.直到n2走到NULL, 此时n1即为新的链表地址.
注意: 最后一次, 当n3走到NULL, 而n2走到最后最后一个结点, 指向n1之后, n2向后走, 但是此时n3不能继续走, 会对NULL解引用,代码报错, 所以要加以判断
画图演示:
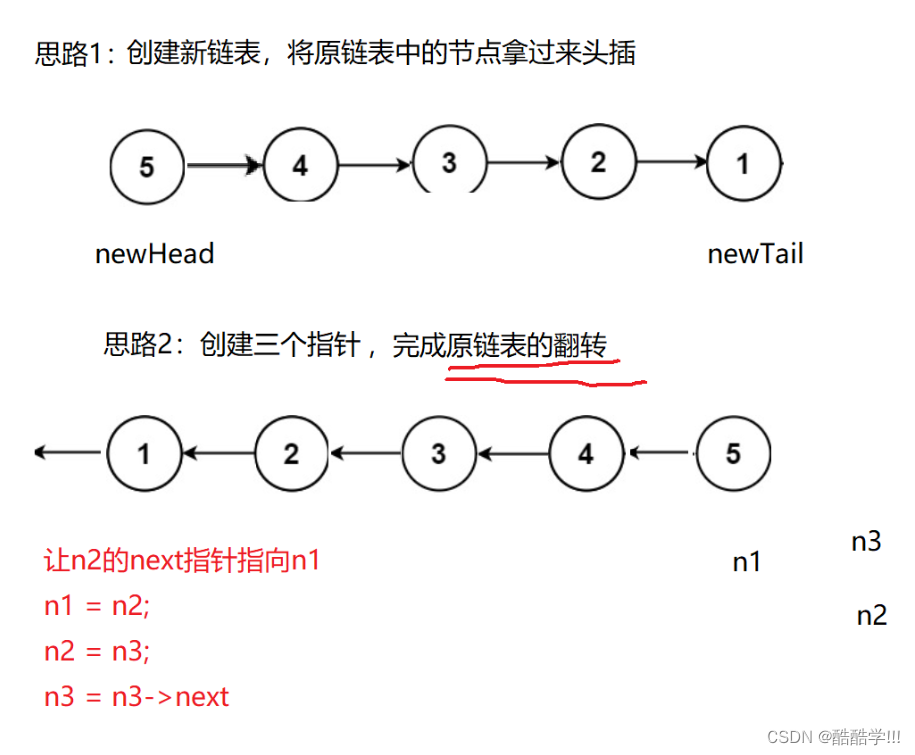
代码描述:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head) {ListNode* n1,*n2,*n3;if(head==NULL){return NULL;}n1 = NULL;n2 = head;n3 = head->next;while(n2){n2->next = n1;n1 = n2;n2 = n3;if(n3){n3 = n3->next;}}return n1;
}
5. 合并两个有序链表
题目链接:合并两个有序链表
题目描述:
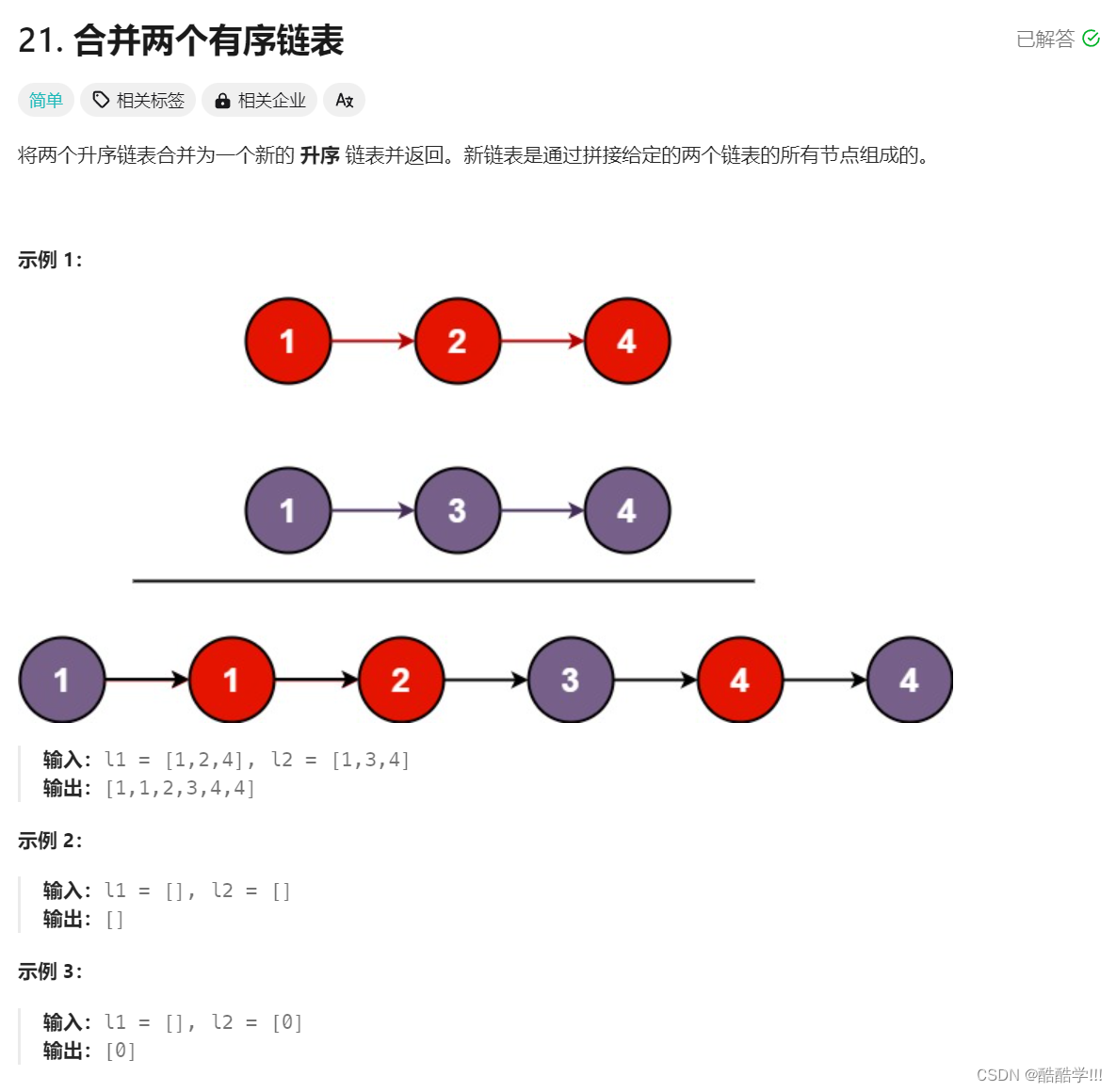
思路历程:创建一个新的链表, 带头链表防止指针为NULL,访问越界, 遍历两个链表, 比较两个链表中的val,小的结点插入到新链表中, 跳出循环后, 如果有某一个链表还有值, 直接插入到新的链表之后, 最后返回新链表的第一个有效结点, 并且释放掉自己开辟的内存.
画图演示:
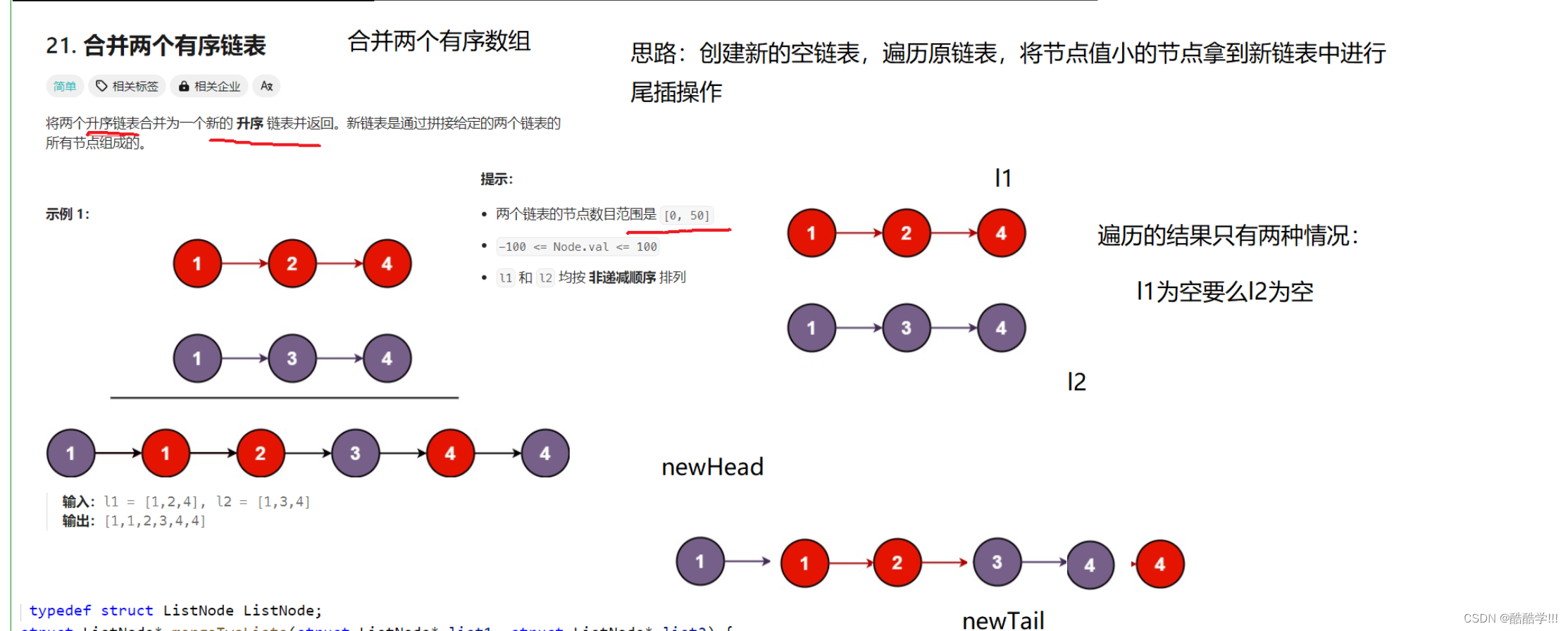
代码描述:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*///#include<stdlib.h>typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {ListNode* newHead = (ListNode*)malloc(sizeof(ListNode));newHead->next = NULL;ListNode* newTail = newHead;while(list1 && list2){if(list1->val < list2->val){newTail->next = list1;newTail = newTail->next;list1 = list1->next;}else{newTail->next = list2;newTail = newTail->next;list2 = list2->next;}}if(list1){newTail->next = list1;}if(list2){newTail->next = list2;}ListNode* ret = newHead->next;free(newHead);newHead = NULL;return ret;
}
6. 链表的中间结点
题目链接:链表的中间结点
题目描述:
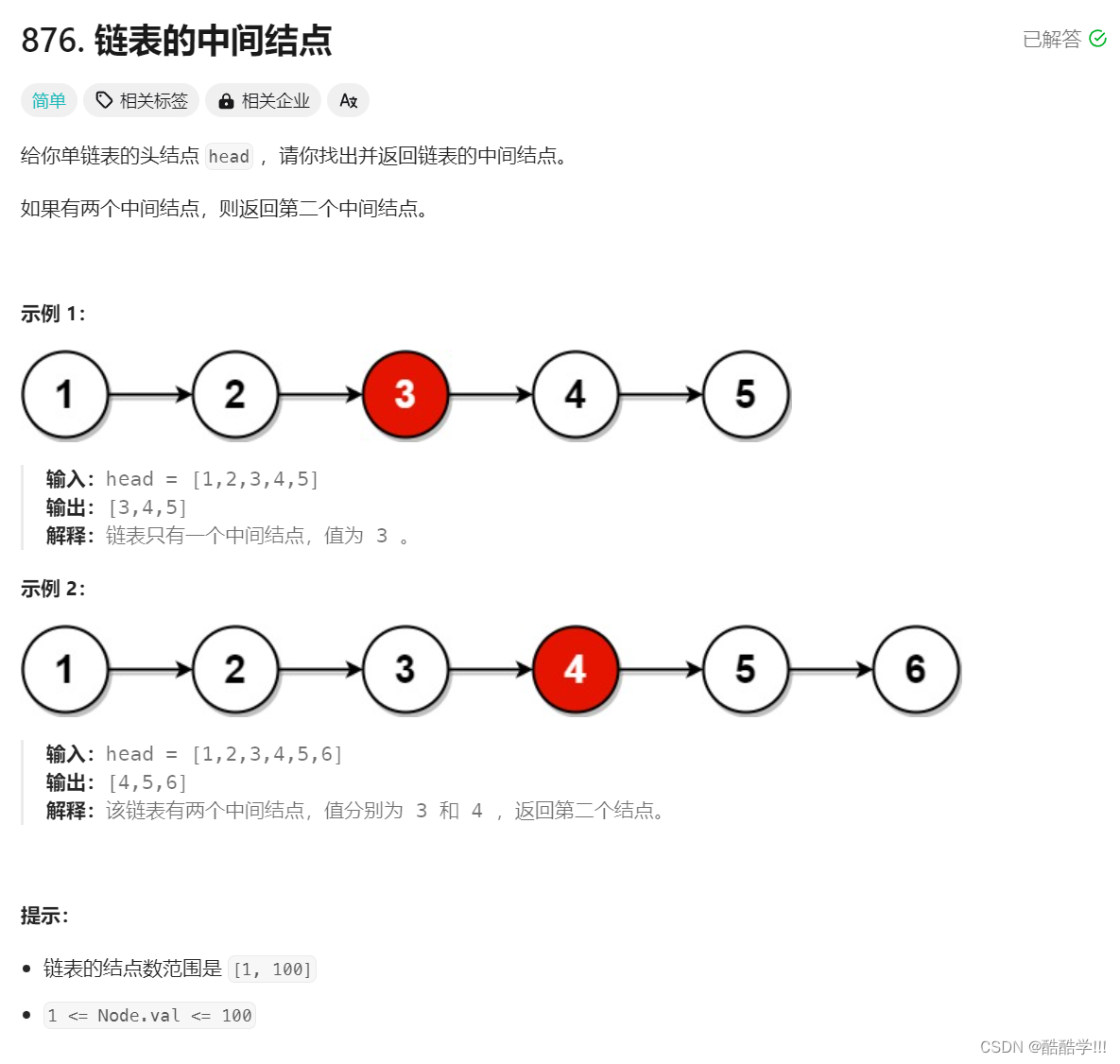
思路历程:
快慢指针, 定义两个指针, 慢指针一次走一步, 快指针一次走两步, 当快指针走到NULL,或者next指向NULL, 此时慢指针即为中间节点.
注意: 使用&&操作符需要先判断fast是否为NULL
画图演示:
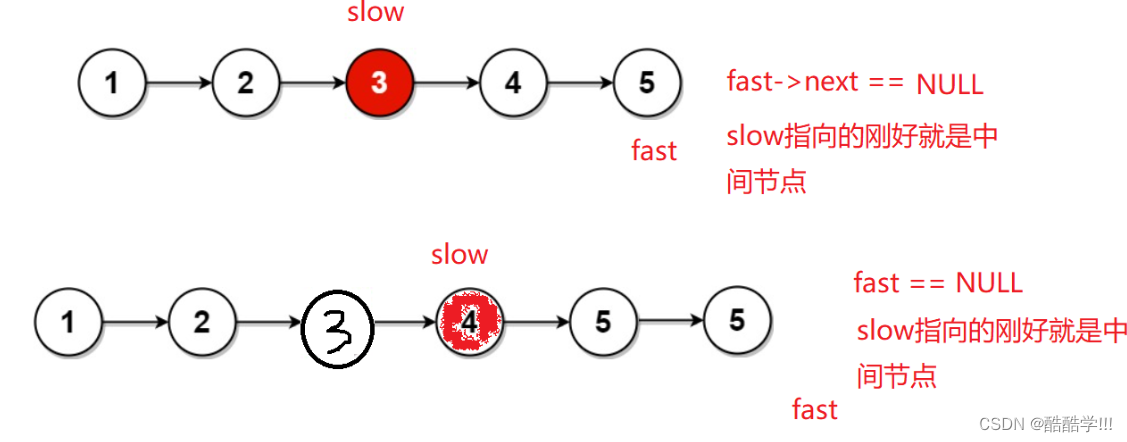
代码描述:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head) {ListNode* slow = head;ListNode* fast = head;while(fast && fast->next){slow = slow->next;fast = fast->next->next;}return slow;
}
7. 环形链表的约瑟夫问题
题目链接: 环形链表约瑟夫问题
题目描述:


思路历程:
如果说我们采用数组的话也可以解决, 不过那太麻烦了, 可以直接创建环形链表.
分为两步:
第一步创建带环链表,第二步开始计数
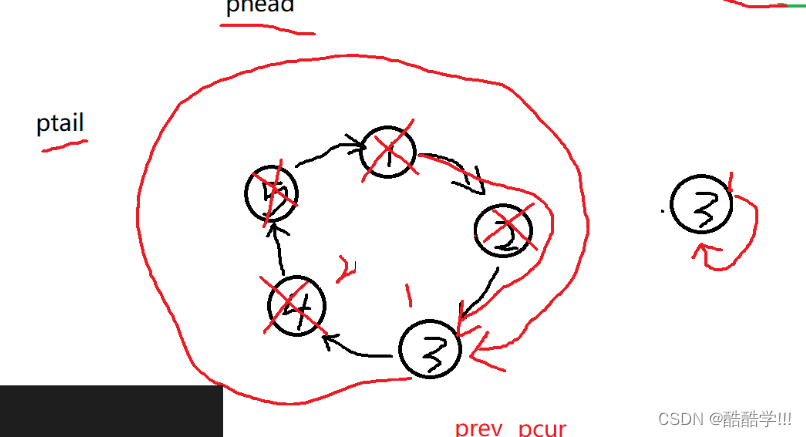
首先创建一个带环链表, 可以使用函数创建, 完成之后返回创建好的链表的尾结点, 因为需要找到前一个结点, 返回头结点的话不知道前一个结点是啥, 接着开始计数, 当值为m时移除此节点 , 先让前一个结点的下一个位置指向待删除结点的下一个结点, 之后删除此节点, 并且让pcur指向prev所指向的结点, count从新计数, 当不等于m时,继续遍历结点, 遍历之前先让prev走到pcur保存结点, 再让pcur走到下一个结点, 计数器++,当pcur的下一个节点所指向的结点是本身的话即为要返回的结点.
画图演示:
代码描述:
/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * @param n int整型 * @param m int整型 * @return int整型*/#include <stdlib.h>
typedef struct ListNode ListNode;ListNode* buyNode(int x){ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));if(newnode==NULL){perror("malloc fail");exit(1);}newnode->val = x;newnode->next = NULL;return newnode;}ListNode* creatNode(int n){ListNode* phead = buyNode(1);ListNode* ptail = phead;for(int i = 2 ; i <= n ; i++){ptail->next = buyNode(i);ptail = ptail->next;}ptail->next = phead;return ptail;}int ysf(int n, int m ) {// write code here//1.创建带环链表ListNode* prev = creatNode(n);ListNode* pcur = prev->next;int count = 1;while(pcur->next != pcur){if(count == m){prev->next = pcur->next;free(pcur);pcur = prev->next;count = 1;}else{prev = pcur;pcur = pcur->next;count++;} }return pcur->val;
}8. 分割链表
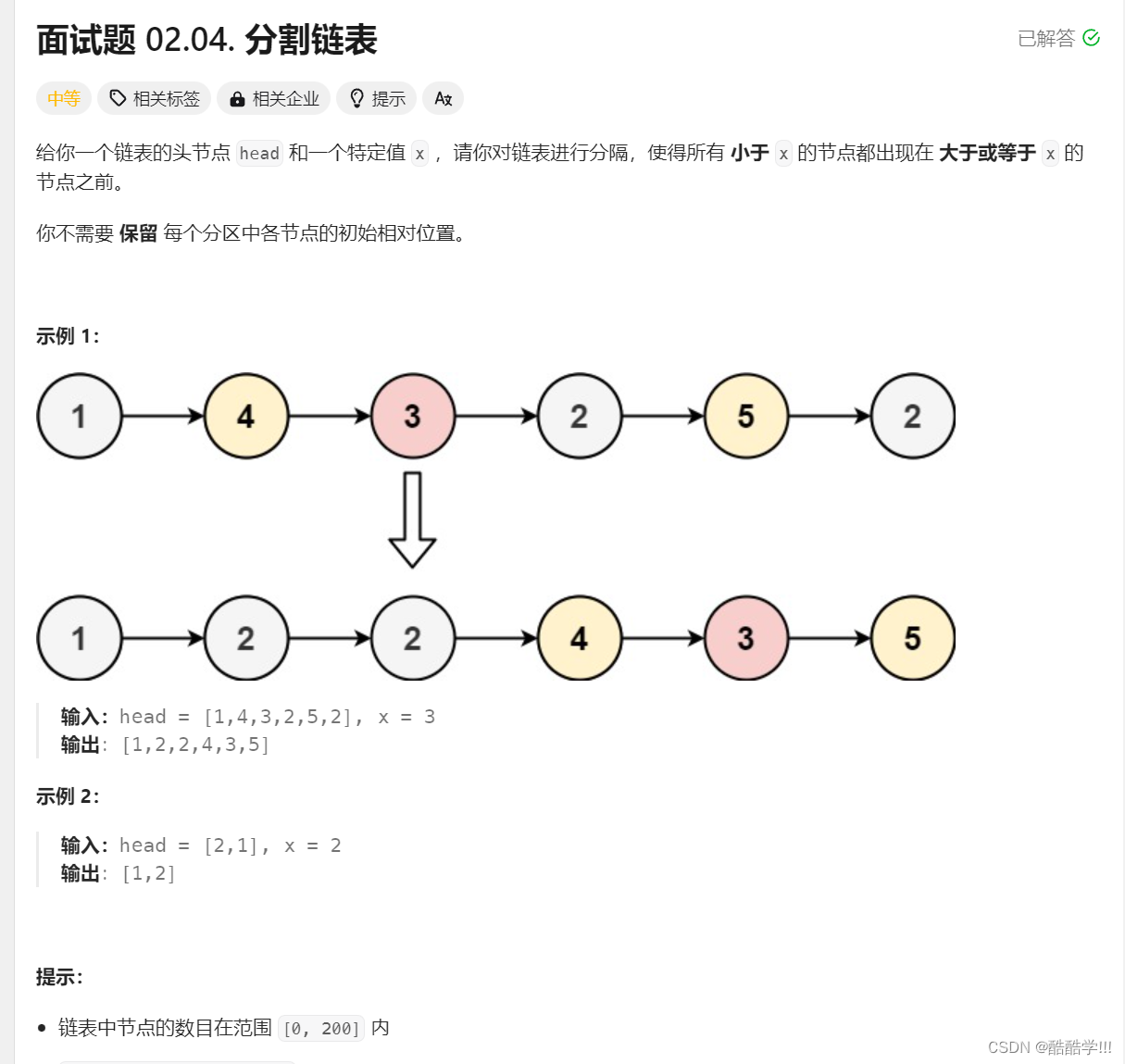
题目链接:分割链表
题目描述:
思路历程:
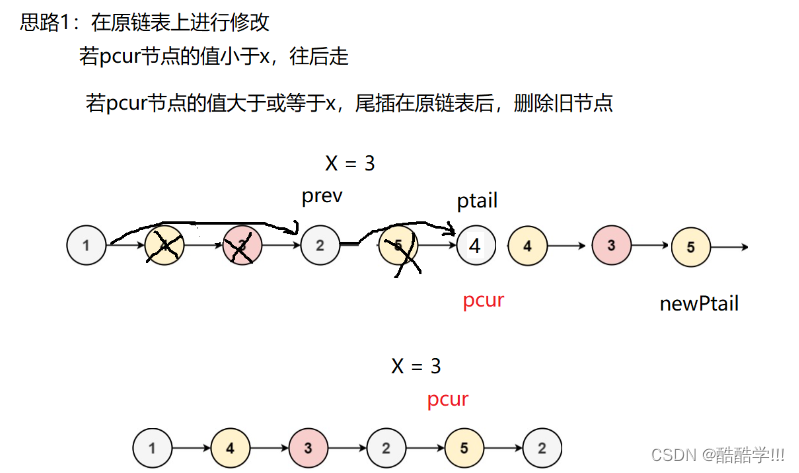
本题有三种思路, 其中第三种思路最为简单,创建两个带头结点的新链表, 一个用来存放大于x的结点,一个存放小于x的结点, 最后让小链表的为节点指向大链表的第一个有效位置, 最后将大链表的最后一个结点next置为NULL.返回小链表有效首结点地址.
画图演示:
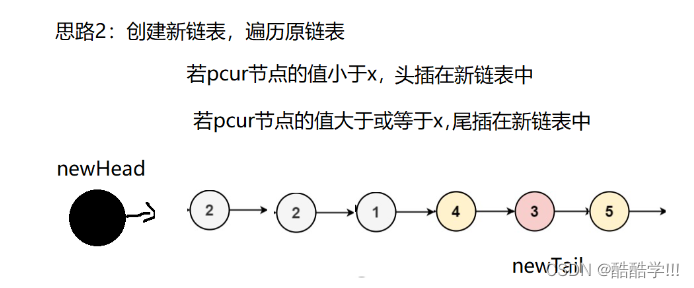
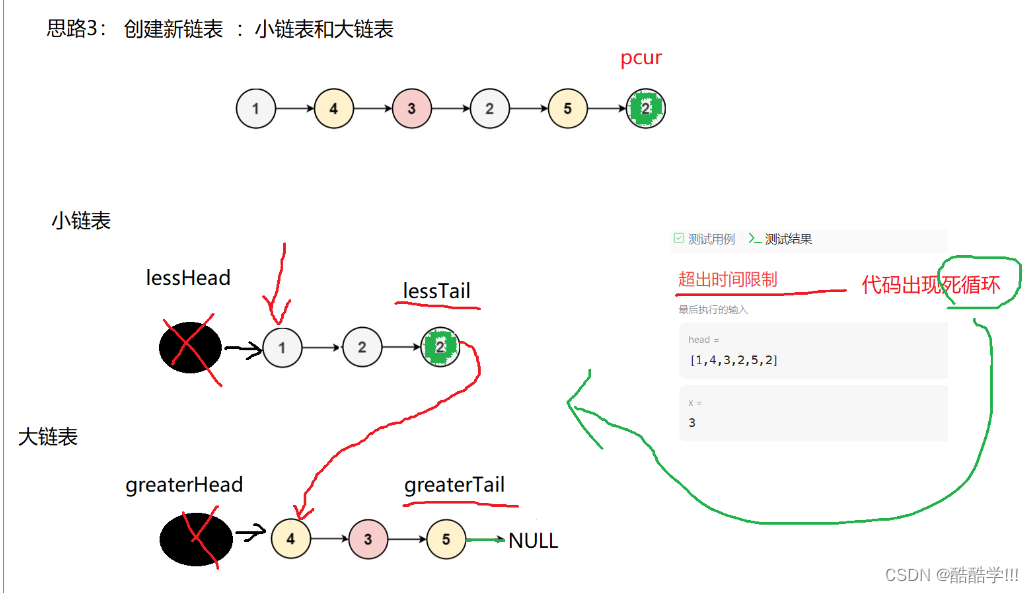
代码描述:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x){ListNode* greaterHead = (ListNode*)malloc(sizeof(ListNode));greaterHead->next = NULL;ListNode* greaterTail = greaterHead;ListNode* lessHead = (ListNode*)malloc(sizeof(ListNode));lessHead->next = NULL;ListNode* lessTail = lessHead;ListNode* pcur = head;while(pcur){if(pcur->val >= x){greaterTail->next = pcur;greaterTail = greaterTail->next;}else{lessTail->next = pcur;lessTail = lessTail->next; }pcur = pcur->next;}greaterTail->next = NULL;lessTail->next = greaterHead->next;return lessHead->next;
}完
总结
以上是对顺序链表学习中比较经典的算法题, 里面的算法思想很值得学习, 并且涵盖了一些细节和错误, 使得对顺序表和链表的理解更加深刻
如果此文有帮助, 感谢关注, 点赞 ! ! !

这篇关于刷题日记 ---- 顺序表与链表相关经典算法题(C语言版)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





