本文主要是介绍MySQL技术内幕InnoDB存储引擎 学习笔记 第三章 文件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
构成MySQL数据库和InnoDB引擎表的文件:
1.参数文件:告诉MySQL实例启动时在哪找到数据库文件,且指定某些初始化参数(定义了某种内存结构的大小等设置)。
2.日志文件:记录MySQL实例对某种条件作出响应时写入的文件,如错误日志文件、二进制日志文件、慢查询日志文件、查询日志文件等。
3.socket文件:用Unix域套接字方式连接时需要的文件。
4.pid文件:MySQL实例的进程ID文件。
5.MySQL表结构文件:存放MySQL表结构定义的文件。
6.存储引擎文件:每个MySQL引擎都有自己的文件保存各种数据,这些引擎存储了数据和索引。
查看MySQL读取参数文件的顺序,对于同一个配置参数,越往后优先级越高:
mysql --help | grep my.cnf
运行它:

MySQL参数文件作用与Oracle的参数文件类似,但Oracle实例启动时若找不到参数文件,不能进行装载(mount),而MySQL实例可以没有参数文件启动,此时所有参数值取决于编译MySQL时指定的默认值和源代码中指定的参数默认值。
如果MySQL在默认的数据库目录下找不到mysql架构,则启动会失败,此时错误日志可能如下:

mysql架构中记录了访问该实例的权限。
Oracle的参数文件分为二进制参数文件(spfile,server parameter file)和文本类型的参数文件(pfile,parameter file,也叫init.ora),而MySQL的参数文件只是文本的,可进行编辑。
可将数据库参数看成一个键值对。可通过命令show variables查看所有参数,同时可通过like过滤参数名。从MySQL 5.1开始,可通过information_schema架构下的GLOBAL_VARIABLES视图查找参数:
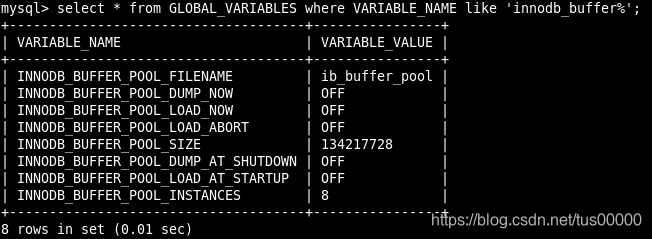
推荐使用show variables命令,它更简单且各版本MySQL都支持它。
Oracle和SQL server有隐藏参数以供内部人士使用,MySQL中没有。
MySQL参数文件中参数分为动态参数和静态参数,动态参数可在MySQL实例运行中进行更改,静态参数在实例生命周期内不能更改。可用set命令更改动态参数:

命令中的global和session关键字表明该参数的修改是基于当前会话还是整个实例的生命周期。有些动态参数只能在会话中修改,如autocommit;有些修改完后,在整个实例生命周期内都生效,如binlog_cache_size;有些既可以在会话也可以在整个实例生命周期内生效,如read_buffer_size。
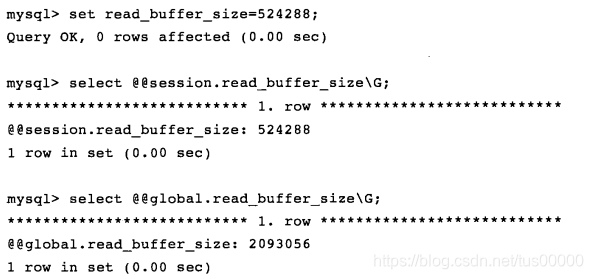
可见不加global或session时只是将本会话的参数改变了。改变参数全局值:

改变参数全局值并不会改变参数文件中的值,下次MySQL启动还会使用参数文件中的值。
修改静态变量的值会报错:

错误日志文件对MySQL的启动、运行、关闭过程进行了记录,类似于Oracle的alert文件,用来定位错误:
SHOW VARIABLES LIKE 'log_error';
错误日志文件名默认是服务器的主机名(hostname命令结果),文件名后缀为.err。
慢查询日志为SQL优化提供帮助,我们可以设一个SQL运行时间阈值,超过该阈值(不包含等于情况)的所有SQL都记录到慢查询日志中,该阈值可通过参数long_query_time设置,默认为10,表示10秒。
默认MySQL不启动慢查询日志,需要手工将此参数设为on,然后启动数据库。
从MySQL 5.1开始,long_query_time开始以微妙记录SQL运行时间,这样更精确。
如果运行的SQL没有使用索引,且参数log_queries_not_using_indexes是on,则也会将此SQL语句记录到慢查询日志文件中。
随着慢查询日志的增加,分析该文件就变得困难了,MySQL提供了mysqldumpslow命令解决此问题,如获取锁定时间最长的10条SQL语句:
mysqldumpslow -s al -n 10 david.log
MySQL 5.1开始可以将慢查询日志记录放入一张表中,慢查询表是mysql.slow_log。
参数log_output指定了慢查询输出的格式,默认为FILE,可将其设为TABLE,就可以将慢查询信息插入mysql.slow_log表中了。该参数是动态参数,且是全局的。
查询是否在使用慢查询表:
SHOW VARIABLES LIKE 'log_output';
运行它:

使用慢查询表:
set global log_output = 'TABLE';
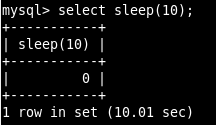
创建一个慢查询:
select sleep(10);
运行它:
查询慢查询表:
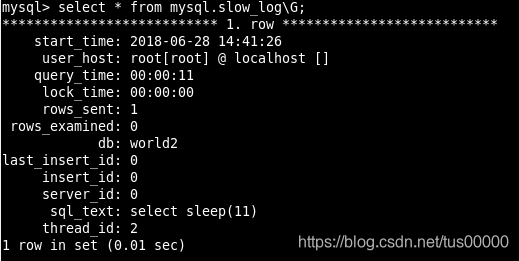
书上的sql_text字段与SQL语句相同,但我测试时却显示上图内容,睡眠时间比原SQL语句中要睡眠的时间多1秒,原因未知。
慢查询表定义语句:
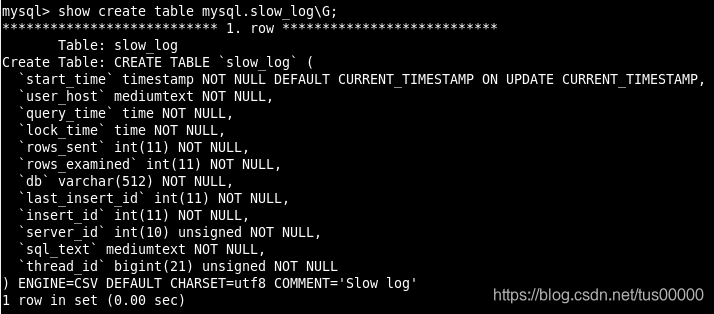
该表使用的是CSV引擎,大数据量下查询效率不高,可将该表引擎转换为MyISAM以提升查询效率,但如果转换表引擎时启动了慢查询,会报错,应先关闭慢查询日志:

但更改慢查询表引擎后会对数据库带来额外开销,但关于慢查询日志的参数很多都是动态的,在线修改很方便。
查询日志记录了所有对MySQL数据库的请求信息,无论请求是否得到了正确的执行。默认查询日志文件名为主机名.log。查看查询日志位置:
SHOW VARIABLES LIKE 'general_log_file';
查看查询日志:
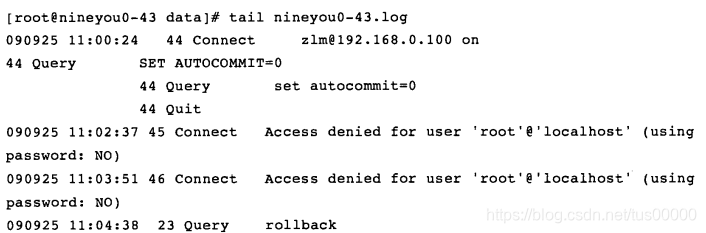
其中也记录了access denied请求。从MySQL 5.1开始,可将查询日志放入mysql.general_log表,使用方法也是将log_output参数改为TABLE。
二进制日志记录了除SELECT和SHOW这类没有对数据本身进行修改的操作外的所有操作,其中还包括数据库更改操作的时间和执行所用时间等信息。如果想记录SELECT和SHOW这类操作,只能使用查询日志。
二进制文件作用:
1.恢复:当数据全备文件恢复后,可通过二进制日志进行point-in-time恢复。
2.复制:原理与恢复类似,通过复制和执行二进制日志使得一台远程MySQL数据库(称为slave或standby)与当前数据库(称为master或primary)进行实时同步。
可配置参数log-bin为ON来启动二进制日志,也可将该参数值改为一个路径,如不指定路径,则默认二进制日志文件名为主机名.日志序列号,二进制日志在数据库所在目录(datadir)下,查看位置:
SHOW VARIABLES LIKE 'datadir';
MySQL命令行下使用system可运行shell命令:
system ls -l
二进制日志文件中有一个以.index结尾的二进制索引文件,存储过往生产的二进制日志序号,通常不应手工修改此文件。
二进制文件默认不启动,需要手动指定参数启动,开启此功能对数据库整体性能影响十分有限,却可以带来检查点恢复和同步功能,应该开启此功能。
影响二进制日志的参数:
1.max_binlog_size:指定了单个二进制文件的最大值,超过该值后,会产生新的二进制日志文件,表示日志序列号的后缀名+1,并记录到.index文件。从MySQL 5.0开始默认值为1073741824(1G),之前版本默认1.1G。
2.binlog_cache_size:使用有事务功能的存储引擎时,所有未提交的事务的二进制日志会被记录到一个缓存中,当事务提交时,会将二进制日志写入文件,此参数控制未提交的二进制日志的缓存区大小,默认为32KB。此参数是基于会话的,即当一个线程开始一个事务时,MySQL自动分配一个大小为binlog_cache_size的缓存,因此该值不能设置过大,而设置太小时,超过缓冲区的部分会写入一个临时文件,因此也不能设置太小。可通过SHOW GLOBAL STATUS LIKE 'binlog_cache%';查看binlog_cache_use(使用缓冲写二进制日志次数)和binlog_cache_disk_use(使用临时文件写二进制日志的次数)以判断参数大小是否合适。
3.sync_binlog:二进制日志并不是在写的时候就真正写入磁盘了,而是此参数规定写多少次后再一起同步到磁盘。如果将此参数设为1,表示每次写二进制文件都会调用fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘。该参数默认值为0,表示MySQL不控制binlog的刷新,即不调用fsync之类的磁盘同步指令,而是由文件系统自己控制它的缓存的刷新。即使将sync_binlog设为1,当使用InnoDB引擎时,在一个事务发出COMMIT之前,由于sync_binlog设为1,会将二进制日志立即写入磁盘,如此时发生宕机,则MySQL下次启动时此事务应该被回滚掉而非应用到数据库,但二进制日志已经记录了该事务信息,不能被回滚,这个问题可将innodb_support_xa参数设为true解决,它虽然与XA事务(涉及多个数据库的分布式事务)有关,但也确保了二进制日志和InnoDB数据文件的同步。
4.binlog-do-db和binlog-ignore-db:表示需要写入或忽略写入关于哪些库的二进制日志,默认为空,表示需要将所有库操作同步到二进制日志。
5.log-slave-update:如当前数据库是复制中的slave,则它不会将master的二进制日志写入自己的二进制日志中(只会记录本库上执行的SQL),如果需要写入,要将此参数设为true。当从库是其他从库的主库时,必须设置此参数。
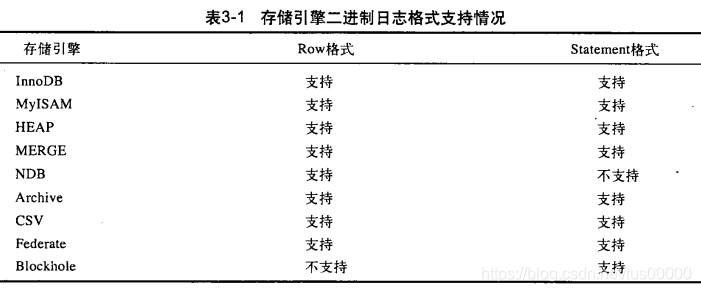
6.binlog-format:影响记录二进制日志的格式。MySQL 5.1前没有此参数,此前的二进制文件的格式是基于SQL语句的(相当于binlog-format参数取STATEMENT值),因此当复制时对于一些两次运行结果不同的函数如rand、uuid或使用触发器等情况时,会导致主从服务器上表数据不一致。InnoDB引擎的默认事务隔离级别是REPEATABLE READ,这也是因为二进制日志文件格式的关系,如果使用READ COMMITTED事务隔离级别(是大多数数据库如Oracle、SQL server的默认隔离级别),会出现丢失更新的现象。MySQL 5.1开始引入的binlog-format参数可设为以下值:
(1)STATEMENT:与MySQL 5.1版本前的相同,二进制日志记录的是日志的逻辑SQL语句。
(2)ROW:二进制日志记录表行更改情况,如果设为此值,可将事务隔离级别设为READ COMMITTED以获得更好的并发性。
(3)MIXED:采用STATEMENT格式进行二进制文件的记录,但以下情况使用ROW格式:
①表引擎为NDB时,对表的DML操作。
②使用了UUID()、USER()、CURRENT_USER()、FOUND_ROWS()、ROW_COUNT()等不确定函数时。
③使用了INSERT DELAY语句(此语句不等数据插入成功就返回)。
④用了用户定义函数(UDF)。
⑤使用了临时表。
此参数是动态参数。将其在当前会话中的值改为ROW:
SET @@SESSION.binlog_format = 'ROW';
SET SESSION binlog_format = 'ROW'; -- 与上句等价
查看当前会话中的此参数值:
select @@session.binlog_format;
select session binlog_format; -- 错误,提示session是未知字段值
将此参数设为ROW可为数据库恢复和复制带来更好的可靠性,但会带来二进制文件大小的增加(记录每行的改变而非只记录SQL),这通常也会带来复制时的网络开销。查看当前二进制文件字节数:

上图中Position字段即为二进制日志当前字节数。
二进制日志文件查看要通过MySQL提供的工具mysqlbinlog,对于STATEMENT格式的二进制日志文件,看到的就是执行的逻辑SQL语句:
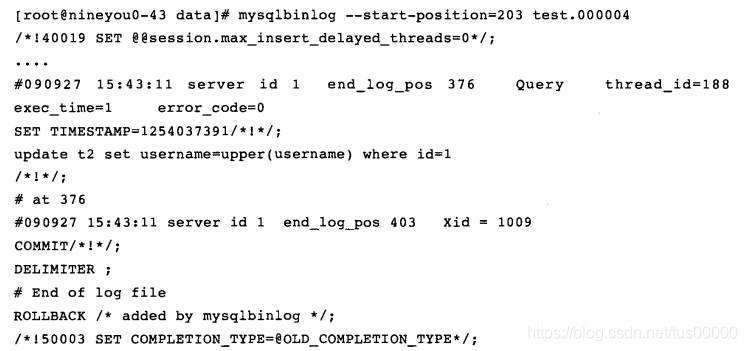
以上结果与Oracle LogMiner类似,如果二进制是以ROW格式记录,则mysqlbinlog输出的结果人不可读:
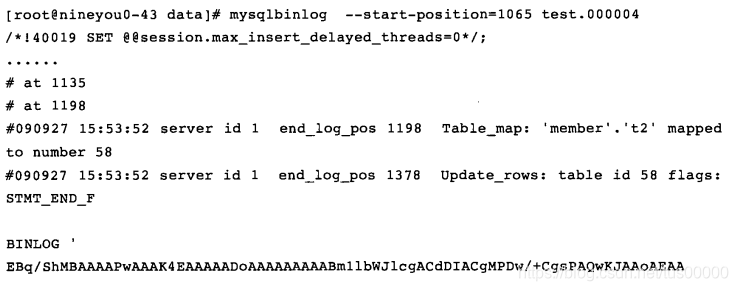
加上-v或-vv(比-v多显示出更新的列的数据类型)参数可将ROW格式的二进制日志文件中看不懂的字符转换为具体的执行信息:

套接字文件用于Unix下以Unix域套接字方式连接MySQL,查看此文件位置(一般在tmp目录下,名为mysql.sock):
SHOW VARIABLES LIKE 'socket';
运行它:

MySQL实例启动时,会将自己的进程ID写入pid文件,查看该文件位置(默认位于数据库目录下,名为主机名.pid:
SHOW VARIABLES LIKE 'pid_file';
MySQL是插件式存储引擎,因此数据存储时每个表都有与之对应的文件(而SQL server是按照每个数据库下的所有表和索引存在一个mdf文件中)。任何存储引擎的表都有一个以frm为后缀名的文件,其中记录了该表表结构定义。
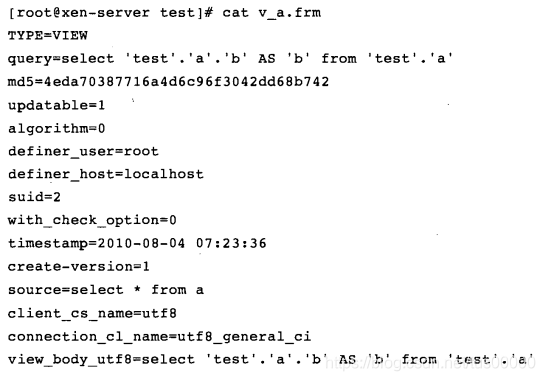
frm文件还用来存放视图定义,该文件是文本文件,可用cat直接查看(以下是自定义视图v_a的frm文件):
每个存储引擎都有自己独有的文件,如重做日志文件、表空间文件。
InnoDB引擎在存储上模仿了Oracle,将存储的数据按表空间存放,默认配置下,有一个初始化大小为10MB、名为ibdata1的文件,该文件是默认表空间文件,可通过参数innodb_data_file_path对其设置,查看此参数值:
SHOW VARIABLES LIKE 'innodb_data_file_path';
运行它:
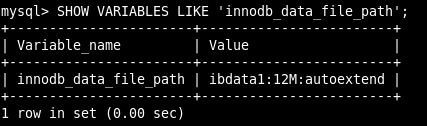
上图显示该表空间由文件ibdata1组成,该文件最大12M,用完后可自动增长。一个表空间也可以由多个文件组成,配置方式如下:
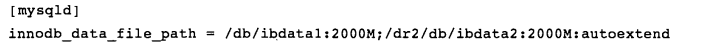
如果以上两个文件在不同磁盘上可以带来性能提升。
设置innodb_data_file_path参数后,所有基于InnoDB引擎的表的数据都会记录在此参数指定的文件内。而通过设置参数innodb_file_per_table为ON,可基于每个InnoDB存储引擎表单独产生一个表空间,文件名为表名.ibd,从而不用将所有数据都存放于默认表空间中。这些单独的表空间中仅存储该表的数据、索引、插入缓冲等信息,其余信息(如表的元数据)还是存放在默认表空间中。

默认InnoDB会有两个重做日志文件,名称分别为ib_logfile0和ib_logfile1,它们记录了InnoDB引擎的事务日志。重做日志目的是当实例或介质失败,InnoDB引擎可使用重做日志恢复到失败前的时刻,以此保证数据完整性。
每个InnoDB引擎至少有一个重做日志文件组,每个组下至少有两个重做日志文件。重做日志组中的重做日志文件以循环方式使用,如先写重做日志文件1,达到文件的最后时,会切换到重做日志文件2,重做日志2也写满时,会再切换到重做日志1中从头写。
为提高可靠性,可设置多个重做日志组(一个重做日志组和多个日志镜像组),将不同的文件组放在不同磁盘上。
与重做日志有关的参数:
1.innodb_log_file_size:指定了重做日志文件大小。
2.innodb_log_files_in_group:指定了重做日志文件组中重做日志文件的数量,默认为2。
3.innodb_mirrored_log_groups:指定了重做日志镜像文件组数量,默认为1,代表没有镜像,只有一个日志文件组。
4.innodb_log_group_home_dir:指定了日志文件组所在路径。
重做日志文件大小设置过大时,恢复时需要很长时间,过小时可能导致一个事务切换多次重做日志文件。
错误日志中可能看到以下警告:
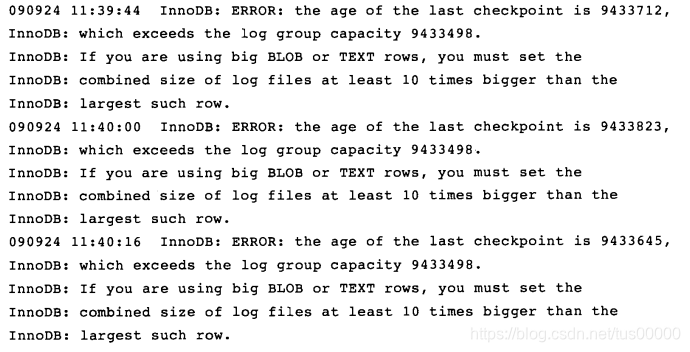
出现以上警告的原因是重做日志有一个capacity变量,该值表示最后的检查点不能超过此阈值,如果超过必须将缓冲池中刷新列表中的部分脏页写回磁盘。
二进制日志和重做日志区别在于,InnoDB重做日志只包含与InnoDB有关的事务日志,而二进制日志记录所有与MySQL有关的日志记录,包括所有存储引擎;此外二进制日志不管其格式如何,记录的都是关于一个事务的具体操作内容,而InnoDB引擎重做日志文件记录每个页更改的物理情况;此外二进制日志是在事务提交前写入的,而重做日志是在事务进行过程中不断写入的。

重做日志不是直接写入磁盘文件,而是先写入重做日志缓冲,再将其写入磁盘日志文件,写入时机为主线程每秒将重做日志缓冲写入磁盘重做日志时,不论事务是否已提交。参数innodb_flush_log_at_trx_commit控制commit时处理重做日志的方式,它的取值及作用如下:
1.0代表提交事务时不将事务的重做日志缓冲写入磁盘上的日志文件,而是等待主线程的每秒刷新。
2.1代表commit时将重做日志缓冲同步写到磁盘。
3.2代表commit时重做日志缓冲异步写到磁盘。
这篇关于MySQL技术内幕InnoDB存储引擎 学习笔记 第三章 文件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





