本文主要是介绍ARCGIS PRO3 三维模型OSGB转SLPK场景数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.前言
因项目工作,需要将三维模型发布到arcgisserver上,但arcgisserver只支持slpk格式的模型,于是我开启了漫长的三维模型格式转换之旅,在这里记录下本人踩过的坑。
2.三维模型数据情况
2.1 模型大小:在20GB以上;
2.2 格式:osgb格式;
2.3 坐标系:cgcs2000平面
3.曾试过的转换方法
3.1在网格大师转换
初始在arcgispro转slpk一直不成功、且转换效率很低,尝试利用网格大师转换,转换效率比较高,在arcgispro中也能加载显示,但是有一个致命缺点,网格大师转换出来的slpk在arcgispro转坐标时,无法识别出坐标,无法进行转换坐标,只能放弃用这个软件转换。

3.2 在arcgispro转换
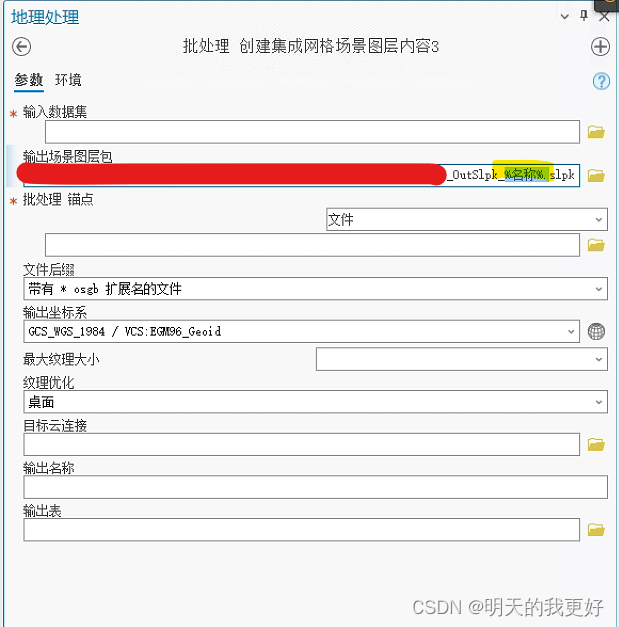
利用arcgispro里的工具“创建集成网格场景图层内容”直接转换,设置输入数据集(可以是与metadata文件同目录下的Data文件夹,或者是下一层的tile文件夹)、输出的slpk路径、选择metadata文件路径、输出坐标系等等。(在这里埋个坑,我的路径用的是中文路径…)
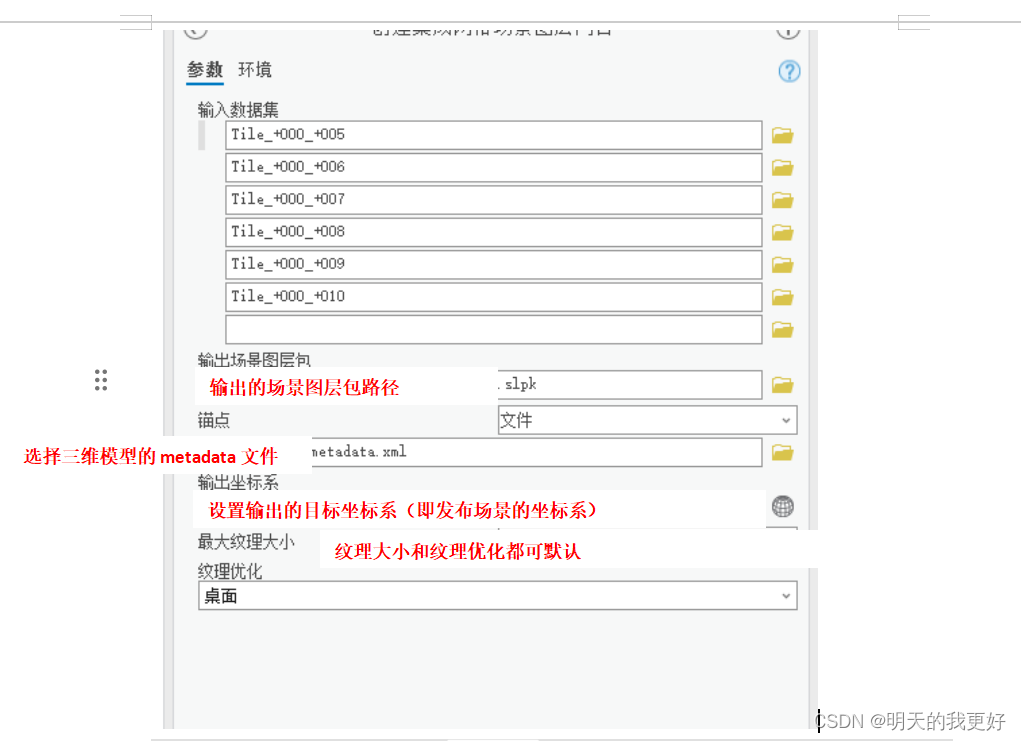
最后当然是失败告终啦,跑着跑着直接整个arcgispro崩了,啥原因崩的都记录不下来。
**记录1:**初始设置的数据路径为中文路径,目标坐标系为模型坐标系cgcs2000,整个模型直接转换,进度条很快提示为98%,但过一段时间后arcgispro自动关闭,根据转换时观察到的内存占用情况,往往随着转换时间推移,内存占用越来越大,我的内存是16gb,所以一开始我怀疑是我的内存不够大,我增加至64gb的内存再尝试转换,发现也是一段时间后自动崩溃。期间发现转换约2gb的模型需要用到差不多2小时,效率非常低。
**记录2:**其后我尝试只采用很小一部分的模型(大概几百M)做转换测试,全部设置英文路径的情况下,目标坐标系为模型坐标系cgcs2000,转换较为迅速,但发布后无法正常加载,提示底图与图层的空间参考不一致,空间坐标设置有问题。
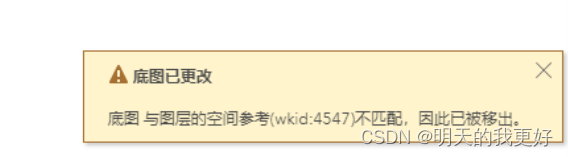
**记录3:**数据设置英文路径下,尝试设置其他坐标系(又是一个漫长之旅),尝试了很多坐标系,例如国家2000大地坐标和国家2000垂直坐标、国家2000平面坐标和默认垂直坐标,wgs84和对应的垂直坐标系等等。真的尝试了超级多,最后都以失败告终,无法运行工具、发布后加载时提示错误、直接啥也不提示只弹出一个地球但模型又加载不出来:


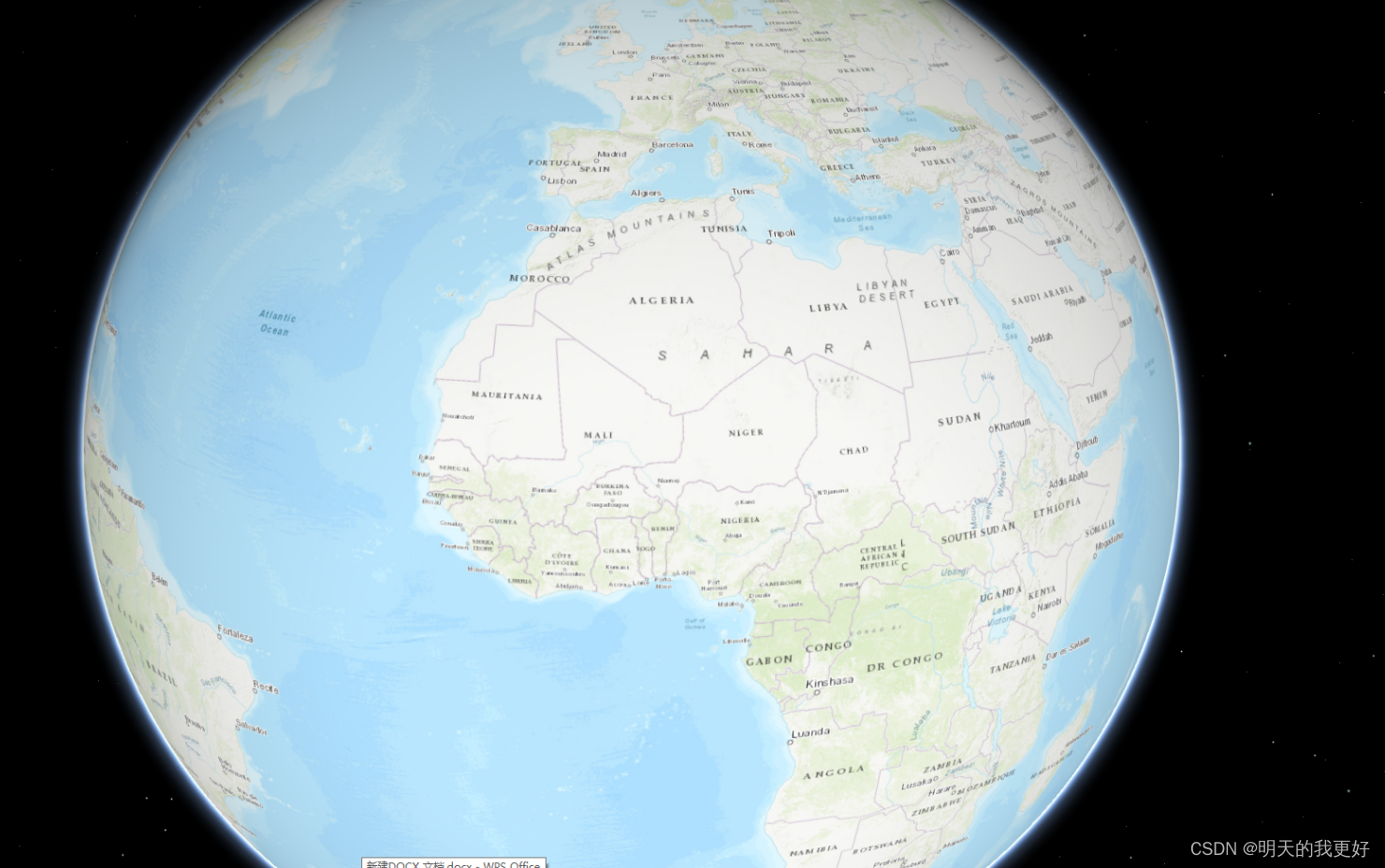
**记录4:**最后发现坐标系一定要设置XY坐标为4326、垂直坐标系为5773!!!过来人告诉你一定要是这两个代码,错一个都不行。最后发布后能成功展示!
**记录5:**设置英文路径、坐标系也设置正确的情况下,对模型进行分块转换,但过程中还是提示了警告,根据观察,应该还是模型文件太大arcgispro识别错误导致的,出现这个提示的话,转换效率超级低,一个1个多GB的模型文件转换后的slpk是原文件大小的10倍…而且转换出来的slpk加载后会出现空洞的情况…继而的想法是将模型继续分更小的块进行转换,避免出现这个情况,但考虑到要转换的模型很多,细分转换工作效率超级低,而且有时候细分后还是会出现这个提示,没有搞懂这个提示的逻辑是啥。

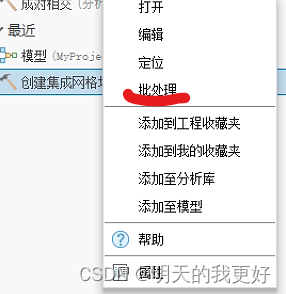
**记录6:**既然细分模型大小后转换正常,想到不如利用批处理对每个tile文件直接转换,于是就是这样成功了!!!直接右键该工具选择批处理,所有设置和之前一样,选择多个tile文件,名称那里可以自己修改,这个批处理最后转换出来之后是一个slpk但包含了所选择的tile文件模型(这个批处理就是这么奇葩),而且效率比直接运行工具高非常多!!!注意模型文件太多了也还是会出现记录5的问题,但此时模型文件可以接近10个或几十个GB同时处理,也算解决大问题了。
4 总结
要想在arcgispro中实现效率较高地完成osgb转slpk,需注意如下事项:
(1)数据路径需为英文路径;
(2)模型文件不能过大,超过10GB的模型建议分块处理;
(3)模型输出坐标系设置,XY坐标系为4326、垂直坐标系为5337,错一不可;
(4)使用“创建集成网格场景图层内容”的批处理进行转换,效率高,支持较大的模型文件转换。
这篇关于ARCGIS PRO3 三维模型OSGB转SLPK场景数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





