本文主要是介绍【年报文本分析】第二辑:python+selium实现根据股票代码和对应年份获取上市公司年报链接(巨潮资讯网),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 序言
- excel文件准备
- 函数模块介绍
- 创建模拟浏览器对象
- 只需要执行一次的部分
- 需要批量执行的重复操作部分(信息录入excel)
- 主函数
- 本地文件结构
- 全部代码
- 结果预览
本文以指定的A股公司年报为例,从巨潮资讯网上获取。
该方法建议需要特定年报数据的采用,如单独分析某一行业等,如果无差别的使用全部A股上市公司,建议直接某宝买现成的。
序言
巨潮资讯网链接:http://www.cninfo.com.cn/new/commonUrl/pageOfSearch?url=disclosure/list/search&lastPage=index
需要提前下载好三个库,都可以用pip install轻松下载,稍微麻烦点儿的是需要去下载个对应版本的chromedriver.exe驱动,放到python或者Anaconda的文件夹目录下,然后添加环境变量(这部分报错了自行百度即可,操作起来不麻烦的)
注意time.sleep()是必要的,一是为了避免频繁操作被浏览器提醒,二是在网络不好的情况下让网页加载完全,否则都会导致报错
一定不要图快,目前我是2s左右完成一次。建议在网络环境较好的情况下运行
这之中还会遇到诸多问题,在代码的注释里也都写到了,其他需求可以做参考。
excel文件准备
文件名建议直接命名为result.xlsx,读取和保存时均使用改路径,如果中断后,修改起点,可以直接覆盖
文件需要至少包括code(股票代码)和year(年份),再建立一个url空列存储链接

函数模块介绍
创建模拟浏览器对象
# 返回虚拟浏览器对象
def openUrl(url):driver = webdriver.Chrome()driver.get(url)time.sleep(2)return driver
只需要执行一次的部分
xpath如何获取百度一下即可
def oneclick(driver):driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[2]/div[6]/div/span[13]/span').click()time.sleep(1)
需要批量执行的重复操作部分(信息录入excel)
# 每一页的XPATH都是一样的,只需处理好一页即可
def geturl(driver,code,year,i): #输入股票代码if i==1:driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[2]/div[1]/div/div/div/div[1]/input').send_keys(code)time.sleep(0.5)else:driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[2]/div[1]/div/div/div/div[1]/input').send_keys(6*Keys.BACKSPACE)driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[2]/div[1]/div/div/div/div[1]/input').send_keys(code)time.sleep(0.5)#点击年报driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[2]/div[6]/div/span[1]').click()time.sleep(0.5)#输入日期driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[1]/div/div/input[1]').send_keys(8*Keys.BACKSPACE)time.sleep(0.5)driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[1]/div/div/input[1]').send_keys(str(year)[-2:]+'-01-01')time.sleep(0.5)driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[1]/div/div/input[2]').send_keys(8*Keys.BACKSPACE)time.sleep(0.5)driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[1]/div/div/input[2]').send_keys(str(year)[-2:]+'-12-31')time.sleep(0.5)#点击查询driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/div[1]/button').click()time.sleep(1.0)#判断是否为年报而非摘要,是打开新网页保存年报网址for j in range(1,3): try:element=driver.find_element_by_xpath(f'//*[@id="main"]/div[2]/div[1]/div[1]/div[2]/div/div[3]/table/tbody/tr[{j}]/td[3]/div/span/a')except:breaktext=element.text if '年度报告' in text and '摘要' not in text:reporturl=element.get_attribute('href')driverreport=openUrl(reporturl)time.sleep(2.5)urlelement = driverreport.find_element_by_xpath('//*[@id="noticeDetail"]/div/div[2]/div[1]/a')url=urlelement.get_attribute('href') df['url'][i]=urldf.to_excel('result.xlsx')driverreport.close()break driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/div[2]/div/div/button').click()time.sleep(0.5)
主函数
#主函数
if __name__ =='__main__':driver=openUrl('http://www.cninfo.com.cn/new/commonUrl/pageOfSearch?url=disclosure/list/search&lastPage=index')oneclick(driver)dtype={'code':str}df=pd.read_excel('result.xlsx',sheet_name='Sheet1',dtype=dtype)for i in range(0,len(df)):code=df['code'][i]year=int(df['year'][i])geturl(driver,code,year+1,i)print(str(i)+'完成')driver.close()
本地文件结构
只需要将excel文件和代码文件放一起即可,或者用绝对路径也可
全部代码
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import pandas as pd# 返回虚拟浏览器对象
def openUrl(url):driver = webdriver.Chrome()driver.get(url)time.sleep(2)return driverdef oneclick(driver):driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[2]/div[6]/div/span[13]/span').click()time.sleep(1)# 每一页的XPATH都是一样的,只需处理好一页即可
def geturl(driver,code,year,i): #输入股票代码if i==1:driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[2]/div[1]/div/div/div/div[1]/input').send_keys(code)time.sleep(0.5)else:driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[2]/div[1]/div/div/div/div[1]/input').send_keys(6*Keys.BACKSPACE)driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[2]/div[1]/div/div/div/div[1]/input').send_keys(code)time.sleep(0.5)#点击年报driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[2]/div[6]/div/span[1]').click()time.sleep(0.5)#输入社会责任#driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[2]/div[2]/div/div/div/input').send_keys('社会责任')#time.sleep(0.5)#输入日期driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[1]/div/div/input[1]').send_keys(8*Keys.BACKSPACE)time.sleep(0.5)driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[1]/div/div/input[1]').send_keys(str(year)[-2:]+'-01-01')time.sleep(0.5)driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[1]/div/div/input[2]').send_keys(8*Keys.BACKSPACE)time.sleep(0.5)driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/form/div[1]/div/div/input[2]').send_keys(str(year)[-2:]+'-12-31')time.sleep(0.5)#点击查询driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/div[1]/button').click()time.sleep(1.0)#判断是否为年报而非摘要,是打开新网页保存年报网址for j in range(1,3): try:element=driver.find_element_by_xpath(f'//*[@id="main"]/div[2]/div[1]/div[1]/div[2]/div/div[3]/table/tbody/tr[{j}]/td[3]/div/span/a')except:breaktext=element.text if '年度报告' in text and '摘要' not in text:reporturl=element.get_attribute('href')driverreport=openUrl(reporturl)time.sleep(2.5)urlelement = driverreport.find_element_by_xpath('//*[@id="noticeDetail"]/div/div[2]/div[1]/a')url=urlelement.get_attribute('href') df['url'][i]=urldf.to_excel('result.xlsx')driverreport.close()break driver.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div/div[2]/div[2]/div/div/button').click()time.sleep(0.5)#主函数
if __name__ =='__main__':driver=openUrl('http://www.cninfo.com.cn/new/commonUrl/pageOfSearch?url=disclosure/list/search&lastPage=index')oneclick(driver)dtype={'code':str}df=pd.read_excel('result.xlsx',sheet_name='Sheet1',dtype=dtype)for i in range(0,len(df)):code=df['code'][i]year=int(df['year'][i])geturl(driver,code,year+1,i)print(str(i)+'完成')driver.close()
结果预览
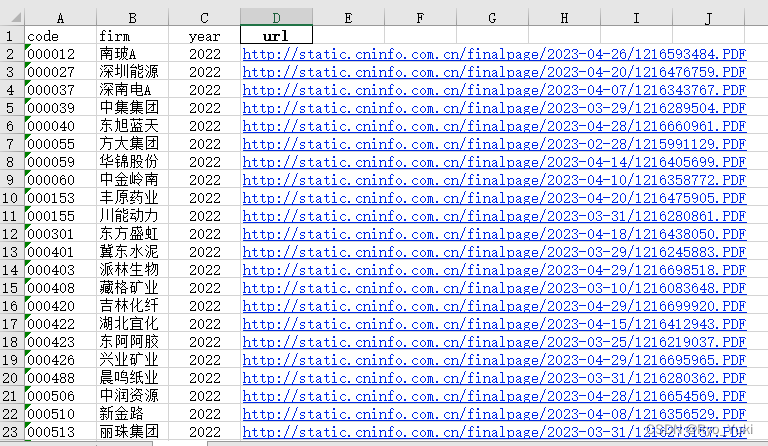
从excel文件中下载年报详见:https://blog.csdn.net/weixin_43956523/article/details/136265883?spm=1001.2014.3001.5501
这篇关于【年报文本分析】第二辑:python+selium实现根据股票代码和对应年份获取上市公司年报链接(巨潮资讯网)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



