本文主要是介绍ECG-Emotion Recognition(情绪识别)-- 数据集介绍WESADDREAMER,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、WESAD数据集
下载链接:WESAD: Multimodal Dataset for Wearable Stress and Affect Detection | Ubiquitous Computing
(1)基本介绍
WESAD是一个用于可穿戴压力和影响检测的新的公开数据集。该多模式数据集以实验室研究期间15名受试者的生理和运动数据为特征,这些数据来自手腕和胸部佩戴的设备。包括以下传感器模式:血容量脉冲、心电图、皮肤电活动、肌电图、呼吸、体温和三轴加速度。此外,该数据集通过包含三种不同的情感状态(中性、压力和娱乐),弥合了之前关于压力和情绪的实验室研究之间的差距。
数据格式:
- “subject”:SX,受试者ID
-“signal”:包括两个领域的所有原始数据:
-- “chest”:RespiBAN数据(所有模式:ACC、ECG、EDA、EMG、RESP、TEMP);
-- “wrist”:Empatica E4数据(所有模式:ACC、BVP、EDA、TEMP)
-“label”:各自研究方案条件的ID,采样频率为700 Hz。提供以下id: 0=未定义/短暂,1=基线(baseline),2=压力(stress),3=娱乐(amusement),4 =冥想(mediation),5/6/7 =在此数据集中应忽略
-
ACC:加速度计(Accelerometer),用于测量物体的加速度,常用于活动监测和姿势识别等应用。
-
ECG:心电图(Electrocardiogram),用于记录心脏电活动的图形表示,常用于诊断心脏疾病和监测心脏健康。
-
EDA:皮肤电活动(Electrodermal Activity),又称为皮电反应(Electrodermal Response),用于测量皮肤的电导率变化,反映交感神经系统的活动水平,常用于情感识别和压力监测等。
-
EMG:肌电图(Electromyogram),用于记录肌肉电活动的图形表示,常用于研究肌肉功能和运动控制等。
-
RESP:呼吸信号(Respiration),用于记录呼吸活动的信号,通常通过胸部或腹部运动来测量呼吸频率和呼吸深度等。
-
TEMP:体温(Temperature),用于记录身体表面或环境温度的信号,常用于监测体温变化和环境温度。
-
BVP:血容量脉动(Blood Volume Pulse),用于记录血液容量变化引起的皮肤血流量变化的信号,通常用于心率和心血管活动的监测。
(2)数据读取
- 引入相关包
import os
import pickle
import numpy as np
import matplotlib.pyplot as plt
# import neurokit as nk
import seaborn as sns
import pandas as pd- 数据读取类
class read_data_of_one_subject:"""Read data from WESAD dataset"""def __init__(self, path, subject):self.keys = ['label', 'subject', 'signal']self.signal_keys = ['wrist', 'chest']self.chest_sensor_keys = ['ACC', 'ECG', 'EDA', 'EMG', 'Resp', 'Temp']self.wrist_sensor_keys = ['ACC', 'BVP', 'EDA', 'TEMP']os.chdir(path)os.chdir(subject)with open(subject + '.pkl', 'rb') as file:data = pickle.load(file, encoding='latin1')self.data = datadef get_labels(self):return self.data[self.keys[0]]def get_wrist_data(self):""""""#label = self.data[self.keys[0]]assert subject == self.data[self.keys[1]]signal = self.data[self.keys[2]]wrist_data = signal[self.signal_keys[0]]#wrist_ACC = wrist_data[self.wrist_sensor_keys[0]]#wrist_ECG = wrist_data[self.wrist_sensor_keys[1]]return wrist_datadef get_chest_data(self):""""""signal = self.data[self.keys[2]]chest_data = signal[self.signal_keys[1]]return chest_data- 添加路径并进行读取
data_set_path = "your_path/data/WESAD/"
subject = 'S3'
obj_data = {}
obj_data[subject] = read_data_of_one_subject(data_set_path, subject)
chest_data_dict = obj_data[subject].get_chest_data()
chest_dict_length = {key: len(value) for key, value in chest_data_dict.items()}
print(chest_dict_length)这里用胸部数据进行测试,得到的数据长度为:

接下来进行一个ECG数据的可视化
plt.plot(chest_data_dict['ECG'][0:5000])
plt.show()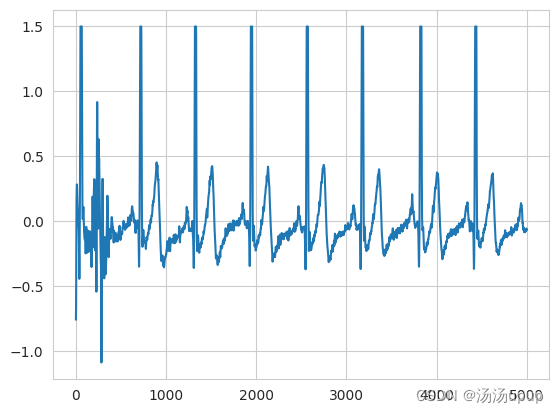
- 读取标签,并提取出baseline的片段
# Get labels
labels = obj_data[subject].get_labels()
baseline = np.asarray([idx for idx,val in enumerate(labels) if val == 1])
print(baseline)print("Baseline:", chest_data_dict['ECG'][baseline].shape)同理要读取压力片段只需要替换val==2即可
2、DREAMER数据集
下载地址:ASCERTAIN dataset
注意这个数据集需要申请才能下载
(1)基本介绍
包含ECG数据和EEG数据,其中ECG数据为2导联,EEG数据为14导联。
记录了23名参与者的信号,以及参与者在每次刺激后对其情感状态的自我评估,包括效价(valence)、唤醒(arousal)和支配(dominance)。
在一个实验中,23名志愿者观看了由Gabert-Quillen等人[1]挑选和评估的18个电影片段,在这个实验中,dream数据库包含了参与者的评分和生理记录。脑电图和心电信号被记录下来,每个参与者用五分制报告他们的感觉唤醒、效价和支配性来评估他们的情绪。
数据格式:
储存在DREAMER.mat文件中
DREAMER =
struct with fields:
Data: {1×23 cell}
EEG_SamplingRate: 128
ECG_SamplingRate: 256
EEG_Electrodes: {'AF3' 'F7' 'F3' 'FC5' 'T7' 'P7' 'O1' 'O2' 'P8' 'T8' 'FC6' 'F4' 'F8' 'AF4'}
noOfSubjects: 23
noOfVideoSequences: 18
Disclaimer: 'While every care has been taken…'
Provider: 'University of the West of Scotland'
Version: '1.0.2'
Acknowledgement: 'The authors would like to thank…'
具体数据结构:
Age: 'X' --年龄
Gender: 'X' ('male' or 'female') --性别
EEG: [1×1 struct] --脑电图数据
ECG: [1×1 struct] --心电图数据
ScoreValence: [18×1 double] -- 效价评分
ScoreArousal: [18×1 double] -- 唤醒评分
ScoreDominance: [18×1 double] -- 支配评分
(2)数据读取
- ECG的stimuli数据
i =1
data_stimuli_ecg = data['DREAMER']['Data'][0][0][0][i-1][0]["ECG"][0][0]["stimuli"][0]
data_stimuli_ecg其中i代表受试者,总共23个。得到的数据格式如下:
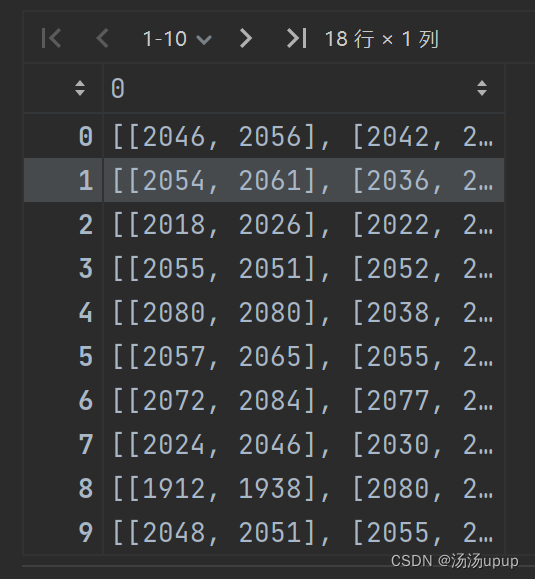
是18*1的数据,包含18个电影片段的刺激。ECG可视化效果
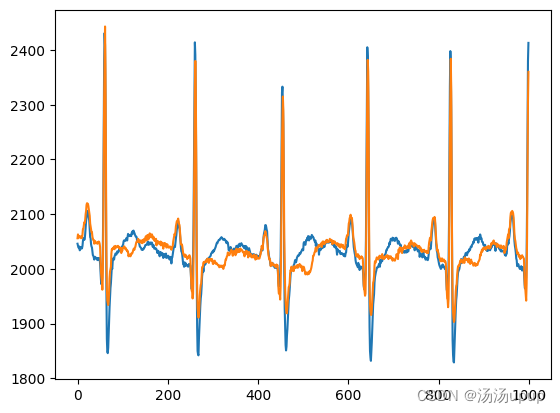
- EEG的stimuli数据
i =1
data_stimuli_ecg = data['DREAMER']['Data'][0][0][0][i-1][0]["ECG"][0][0]["stimuli"][0]
data_stimuli_ecg得到的18个片段的刺激EEG可视化效果:
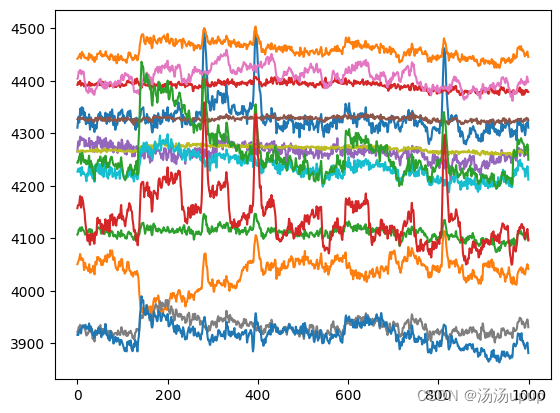
- 整体数据读取并保存
import numpy as np
import scipy.io as siodata_loader = sio.loadmat('your_path/data/DREAMER.mat')data_stimuli_ecg = []
for i in range(1, 24):saldir1 = './save/stimuli/'data_stimuli = data_loader['DREAMER']['Data'][0][0][0][i - 1][0]["ECG"][0][0]["stimuli"][0]for j in range(1, 19):data = data_stimuli[j - 1][0]data_stimuli_ecg.append(data)
np.array(data_stimuli_ecg)
np.save(saldir1 + 'data_stimuli_ecg.npy', data_stimuli_ecg)data_baseline_ecg = []
for i in range(1, 24):saldir2 = './save/baseline/'data_baseline = data_loader['DREAMER']['Data'][0][0][0][i - 1][0]["ECG"][0][0]["baseline"][0]for j in range(1, 19):data = data_baseline[j - 1][0]data_baseline_ecg.append(data)
np.array(data_baseline_ecg)
np.save(saldir2 + 'data_baseline_ecg.npy', data_baseline_ecg)label = []
for i in range(1, 24):saldir3 = './save/label/'data_label = data_loader['DREAMER']['Data'][0][0][0][i - 1][0]["ScoreArousal"][0]label.append(data_label)
np.save(saldir3 + 'label.npy', label)
都看到了这里了,给个小心心❤呗~
这篇关于ECG-Emotion Recognition(情绪识别)-- 数据集介绍WESADDREAMER的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






