本文主要是介绍前端项目中使用插件prettier/jscodeshift/json-stringify-pretty-compact格式化代码或json数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
同学们可以私信我加入学习群!
正文开始
- 前言
- 一、json代码格式化-选型
- 二、json-stringify-pretty-compact简单试用
- 三、prettier在前端使用
- 四、查看prettier支持的语言和插件
- 五、使用prettier格式化vue代码
- 最终效果如图: 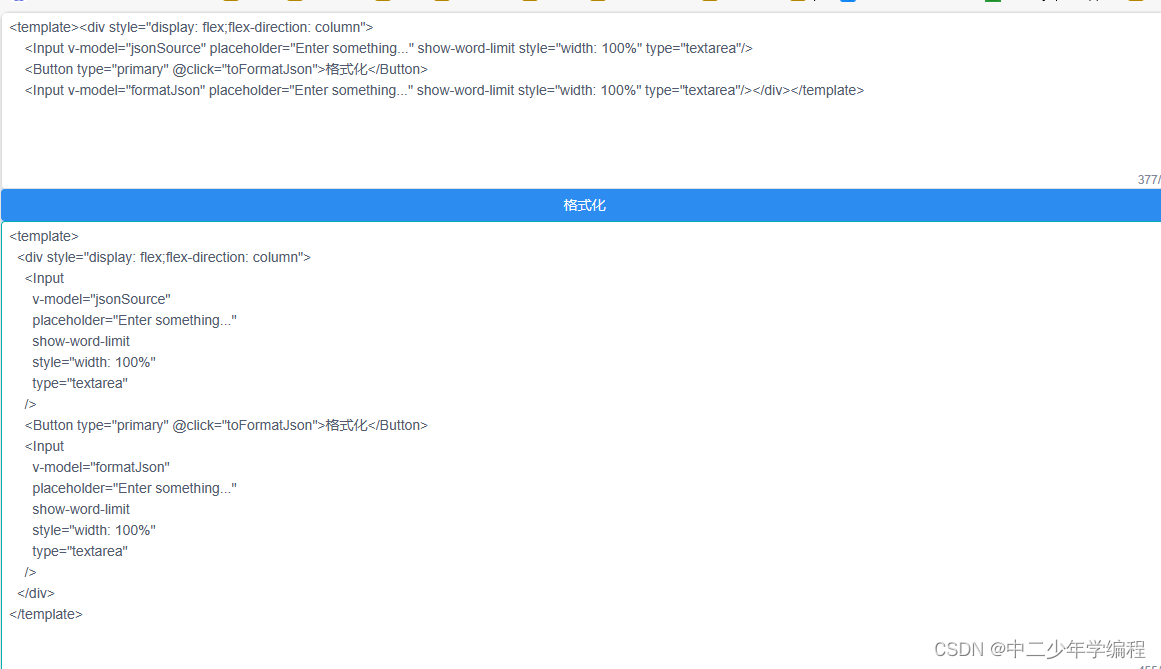
- 总结
前言
平时遇到json、vue、css代码格式化,图片与base64互转、图片格式转换等操作时,都是找在线工具,有些工具做的还挺好,有些做的那一坨,一坨的排名还靠前……
找几个在线工具都不好,终于忍不了,准备做一个自己的chrome/edge插件,方便以后开发时便捷操作。
先从代码格式化开始。
一、json代码格式化-选型
json代码格式化使用频率相对较高,前后端交互,前端需要查看分析后端返回数据时,可能会遇到需要先把某些json数据保存下来,或者需要发送给同事。
在f12控制台中复制得到的json数据,写到文本文档,写到博客,都会样式错乱。这时候就需要使用json数据美化工具。
在代码美化方面,比较有名的是prettier,但是这个插件主要是面向编辑器、后端、cli等场景的,所以官网大篇幅在介绍它如何集成到编辑器中,如何在后端、cli等场景使用。
尤其最新版的prettier,语言插件不再默认内置,都需要加载,找不到对应插件,demo都运行不起来。
prettier官网推荐了另一款插件——jscodeshift,试用了一下插件,倒是很方便,但是它的能力和prettier相比,确实有差距。
搜索解决方案的过程中发现了另一个插件——json-stringify-pretty-compact,使用更简单,但是只能美化json
估计网上那些在线工具,大部分都是用的这类功能单一但易于使用的插件。
二、json-stringify-pretty-compact简单试用
因为最终选型还是prettier,所以这里只是简单记录下,踩坑过程中试用过的json-stringify-pretty-compact。
下载:
npm i json-stringify-pretty-compact
引用:
import jsonStringifyPrettyCompact from 'json-stringify-pretty-compact'
使用:
const jsonSource = ref('{"count":[7,2,5],"format":true,"id":3852,"object":{"t":"json在线格式化","r":"e"},"host":"json-online.com"}')
const formatJson = ref({})
function toFormatJson() {
formatJson.value = jsonStringifyPrettyCompact(parsedJson);
}在页面中效果如图:
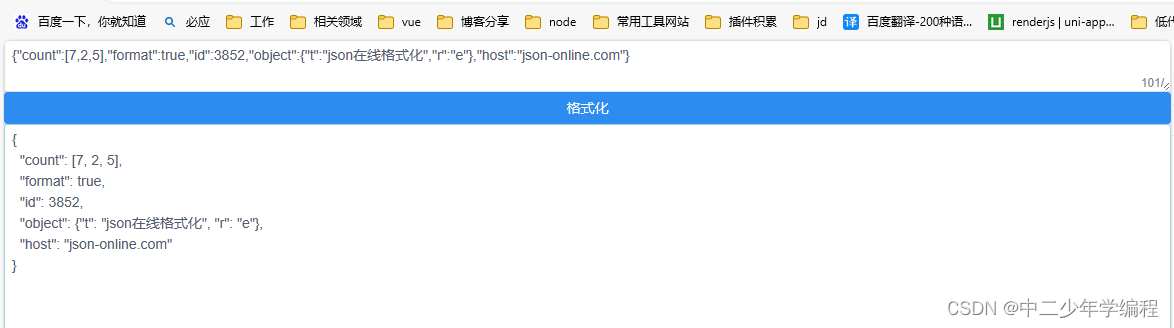
三、prettier在前端使用
prettier官网基本都是在介绍如何在IDE、后端等场景使用,里面对插件的操作逻辑,解析器的使用等也都是适配这些场景,所以如果对prettier并不熟悉的同学,第一次按照官网demo试用,大概率会踩坑。
我这里就不贴官网地址了,免得入坑。就写一些关键代码和官网关键页面,大家就能顺利使用prettier格式化代码。
首先,我们要了解,prettier在web端使用,不存在默认解析器!不存在默认解析器!不存在默认解析器!
必须要手动设置解析器。
因为没有默认解析器,自然也就不存在什么默认解析器插件。我们要用的所有配置,都要手动设置。
下载:
npm i prettier
以json为例,引入:
import prettier from "prettier/standalone";
import prettierPluginBabel from 'prettier/plugins/babel';
import prettierPluginEstree from 'prettier/plugins/estree';
使用:
async function toFormatJson() {try {const formatted = await prettier.format(jsonSource.value, {parser: 'json',plugins: [prettierPluginBabel, prettierPluginEstree],// 根据需要添加semi: true,trailingComma: 'all',singleQuote: true,printWidth: 80,tabWidth: 2,})console.log(formatted)} catch (error) {console.error('Error formatting code:', error)}
}
其他设置都是浮云,在网上搜索,会有很多答案,但是我们一定要注意的是:parser、plugins这两个属性,这是决定我们能不能使用prettier的关键。
- 如果你发现报错:Error formatting code: ConfigError: Couldn’t find plugin for AST format “estree”. Plugins must be explicitly added to the standalone bundle.
很有可能是缺少插件estree,上面说到过,前端使用插件,没有默认解析器,所以必须手动引入需要的插件。
- 如果你发现报错:Error formatting code: ConfigError: Couldn’t resolve parser “json”. Plugins must be explicitly added to the standalone bundle.
很有可能是缺少插件babel,按上面的引入方式引入babel即可
四、查看prettier支持的语言和插件
1.parser解析器
parser属性代表解析器,也就是插件支持格式化哪些类型的代码。值有哪些,可以自行查看源码,这里给不会查看源码的同学贴一个2024年4月23日的版本:
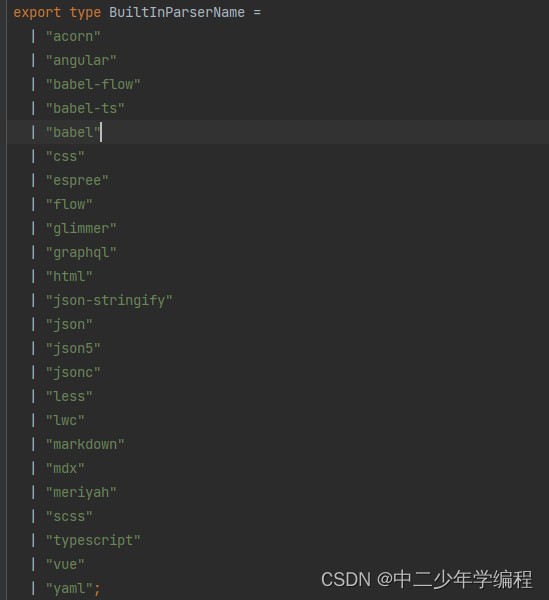
prettier相比较其他插件,支持的代码类型实在是太多了。
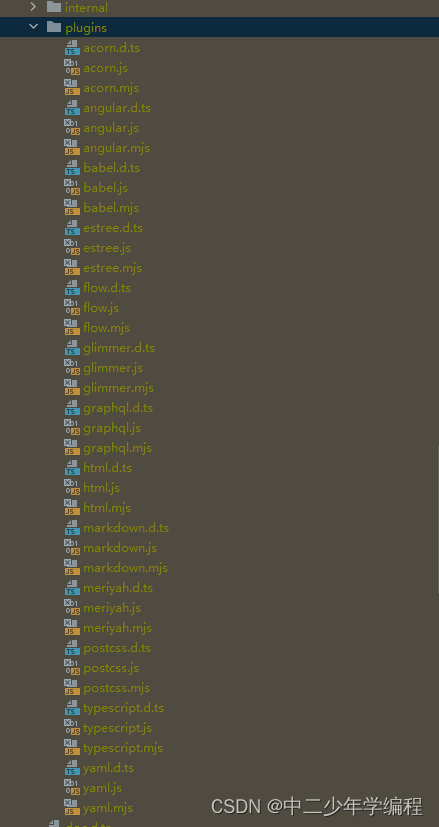
2.plugins插件
不同的解析器要对应着不同的插件,目前官网提供的插件列表地址:https://unpkg.com/browse/prettier@3.2.5/plugins/
这里就只写地址,不放链接了,免得链接多了被某些平台屏蔽。
我们可以通过自己下载的prettier资源目录,找到对应的插件列表:
五、使用prettier格式化vue代码
既然都用prettier实现了json代码的格式化,那么没有理由不多做一点其他代码的格式化。
在上面的基础上,增加html插件:
<script setup>
import {ref} from 'vue'
import prettier from "prettier/standalone";
import prettierPluginBabel from 'prettier/plugins/babel';
import prettierPluginEstree from 'prettier/plugins/estree';
import prettierPluginVue from 'prettier/plugins/html';const jsonSource = ref('{"count":[7,2,5],"format":true,"id":3852,"object":{"t":"json在线格式化","r":"e"},"host":"json-online.com"}')
const formatJson = ref({})async function toFormatJson() {try {formatJson.value = await prettier.format(jsonSource.value, {parser: 'vue',plugins: [prettierPluginBabel, prettierPluginEstree,prettierPluginVue],// 根据需要添加其他解析器插件semi: true,trailingComma: 'all',singleQuote: true,printWidth: 80,tabWidth: 2,})} catch (error) {console.error('Error formatting code:', error)}
}
</script>
最终效果如图:

总结
后续再把monaco集成进来,完成代码显示部分,demo先用输入框将就一下。
获取资源,查看代码示例,或者联系我:
https://lizetoolbox.top:8080/#/qrCode_contact
这篇关于前端项目中使用插件prettier/jscodeshift/json-stringify-pretty-compact格式化代码或json数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





