本文主要是介绍【第3节】“茴香豆“:搭建你的 RAG 智能助理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 1 基础知识
- 1.1.RAG技术的概述
- 1.2 RAG的基本结构有哪些呢?
- 1.3 RAG 工作原理:
- 1.4 向量数据库(Vector-DB ):
- 1.5 RAG常见优化方法
- 1.6RAG技术vs微调技术
- 2、茴香豆介绍
- 2.1应用场景
- 2.2 场景难点
- 2.3 茴香豆的构建:
- 3 论文快读
1 基础知识
【资源汇总】文档 | 视频 | 论文:Retrieval-Augmented Generation for Large Language Models: A Survey
1.1.RAG技术的概述
RAG(Retrieval Augmented Generation)技术,通过检索与用户输入相关的信息片段,并结合外部知识库来生成更准确、更丰富的回答。解决 LLMs 在处理知识密集型任务时可能遇到的挑战, 如幻觉、知识过时和缺乏透明、可追溯的推理过程等。提供更准确的回答、降低推理成本、实现外部记忆。
LLM会产生误导性的 “幻觉”,依赖的信息可能过时,处理特定知识时效率不高,缺乏专业领域的深度洞察,同时在推理能力上也有所欠缺。
RAG 通过在语言模型生成答案之前,先从广泛的文档数据库中检索相关信息,然后利用这些信息来引导生成过程,极大地提升了内容的准确性和相关性。RAG 有效地缓解了幻觉问题,提高了知识更新的速度,并增强了内容生成的可追溯性,使得大型语言模型在实际应用中变得更加实用和可信
1.2 RAG的基本结构有哪些呢?
要有一个向量化模块,用来将文档片段向量化。
要有一个文档加载和切分的模块,用来加载文档并切分成文档片段。
要有一个数据库来存放文档片段和对应的向量表示。
要有一个检索模块,用来根据 Query (问题)检索相关的文档片段。
要有一个大模型模块,用来根据检索出来的文档回答用户的问题。
功能:解决LLMs在处理知识密集型任务时可能遇到的挑战。提供更准确的回答、降低成本、实现外部记忆。
解决问题:生成幻觉(hallucination),过时知识,缺乏透明和可追溯的推理过程
应用:问答系统,文本生成,信息检索,图片描述
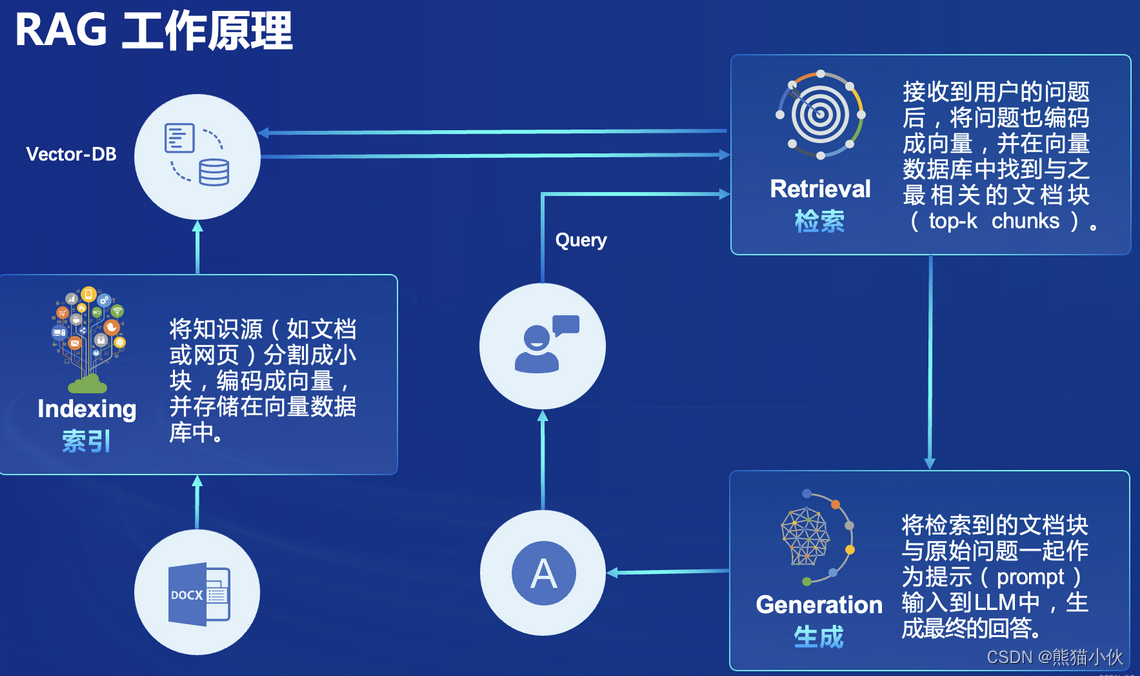
1.3 RAG 工作原理:
索引:将知识源(如文档或网页)分割成chunk,编码成向量,并存储在向量数据库中。
检索:接收到用户的问题后,将问题也编码成向量,并在向量数据库中找到与之最相关的文档块(top-k chunks ).
生成:将检索到的文档块与原始问题一起作为提示(prompt )输入到LLM中,生Generation成最终的回答。
1.4 向量数据库(Vector-DB ):
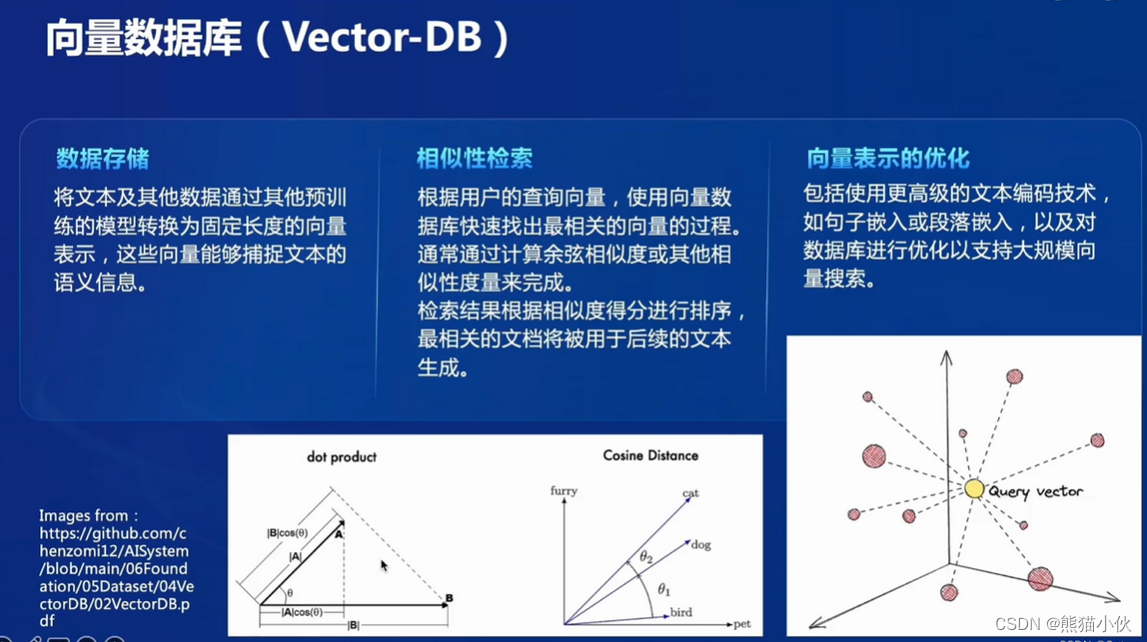
数据存储:将文本及其他数据通过其他预训练的模型转换为固定长度的向量表示,这些向量能够捕捉文体的语义信息。
相似性检索:根据用户的查询向量,使用向量数据库快速找出最相关的向量的过程通常通过计算余弦相似度或其他相似性度量来完成。检索结果根据相似度得分进行排序最相关的文档将被用于后续的文本生成。
向量表示的优化:包括使用更高级的文本编码技术如句子嵌入或段落嵌入,以及对数据库进行优化以支持大规模向量搜索。
1.5 RAG常见优化方法
嵌入优化,索引优化,查询优化,上下文管理,迭代、递归、自适应检索,LLM微调。

1.6RAG技术vs微调技术
 a.方法论:
a.方法论:
RAG技术:RAG技术是一种结合了强化学习、注意力机制和生成模型的综合性方法。它不仅仅是一个单一的模型或技术,而是将多个领域的研究成果相互整合而成的。
微调技术:微调技术通常指的是在预训练模型的基础上,使用少量标注数据对模型进行微小调整,以适应特定任务或领域的需求。
b.数据需求:
RAG技术:RAG技术通常需要大量的未标注数据用于预训练模型,然后可以通过有监督或强化学习的方式进行进一步的调优。
微调技术:微调技术通常需要少量的标注数据用于模型微调,这使得微调技术在数据稀缺的情况下也能取得不错的效果。
c.模型结构:
RAG技术:RAG技术通常由多个组件组成,包括生成器、注意力机制、强化学习部分等,模型结构较为复杂。
微调技术:微调技术通常是在预训练模型的基础上进行微小的参数调整,模型结构相对简单。
d.性能表现:
RAG技术:RAG技术在一些自然语言处理任务中表现出色,如生成式问答、摘要生成等,尤其在处理开放域的文本理解和生成任务中表现优异。
微调技术:微调技术在特定任务上可以取得很好的性能,特别是在有限标注数据的情况下,微调技术往往能够更好地利用数据,实现任务定制化的效果。
2、茴香豆介绍
茴香豆简介:
茴香豆是一个基于LLMs的领域知识助手,由书生浦语团队开发的开源大模型应用。
专为时事通讯(IM)工具中群聊场景优化的工作流,提供及时而又准确的技术支持和自动问答程序。
通过应用检索增强生成(RAG)技术,茴香豆能够理解和高效准确的回应与特定知识领域相关的复杂查询。
茴香豆应用于信息量巨大的用户群组,可以进行讨论与解答相关问题,也可以充当智能客服。传统的NLP解决方案无法准确解析用户意图,且无法给用户提供满意的答案,而茴香豆这种领域知识助手可以准确识别并回答有意义的相关领域的问题,剔除与不回复无用问题或信息。
2.1应用场景
- 智能客服:技术支持、领域知识对话
- IM工具中创建用户群组,讨论、解答相关的问题。
- 随着用户数量的增加,答复内容高度重复,充斥大量无意义和闲聊,人工回复,成本高,影响工作效率。
- 茴香豆通过提供自动化的问答支持,帮助维护者减轻负担,同时确保用户问题得到有效解答。
2.2 场景难点
- 群聊中的信息量巨大,且内容多样,从技术讨论到闲聊应有尽有。
- 用户问题通常与个人紧密相关,需要准确的实时的专业知识解答。
- 传统的NLP解决方案无法准确解析用户意图且往往无法提供满意的答案。
- 需要一个能够在群聊中准确识别与回答相关问题的智能助手,同时避免造成消息过载。
2.3 茴香豆的构建:
茴香豆的知识库构建通常是个人与企业的相关技术知识文档,目前支持Markdown文件、word文档、ppt文件等常用的文件类型,可以设置积极和消极的标签控制助手的回答范围。
茴香豆读取用户问题以及相关文档的平台,在国内一般是微信群和飞书群,国外是discord和slack等技术交流应用软件。
茴香豆目前支持调用本地或远端大模型的API,如书生浦语、通义千问、ChatGPT。Kimi等
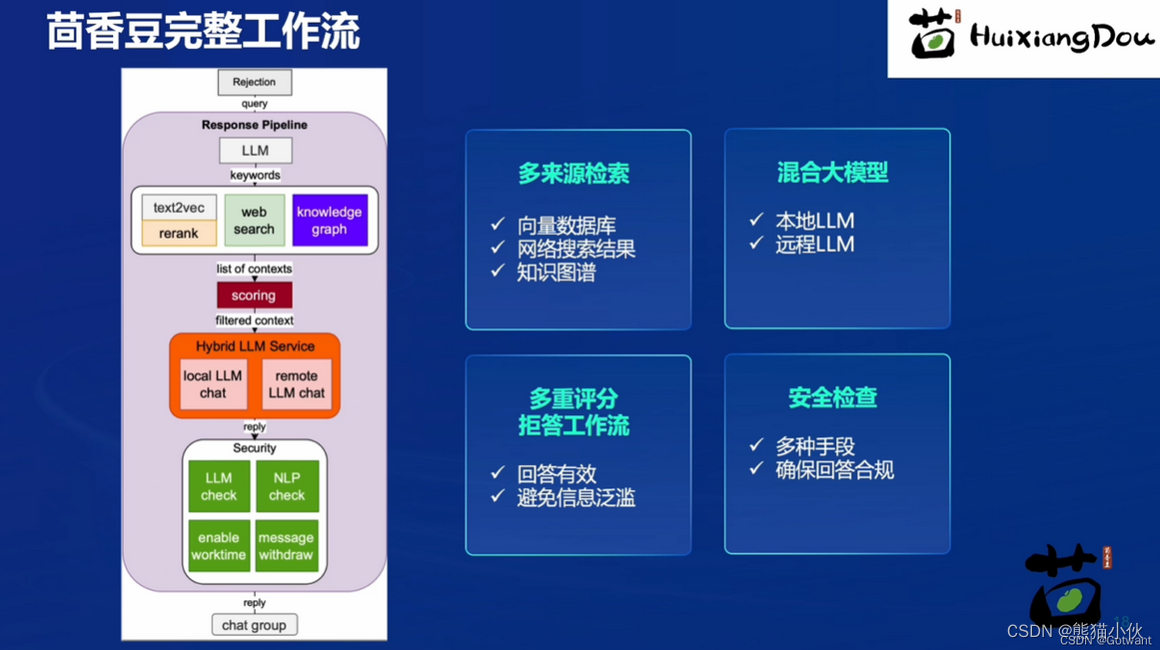
茴香豆的工作流:预处理部分会将用户的输入筛选,转换为合适的问询,然后模型对于问询进行相应的分析,对问询给出评分,根据得分判断该问题是否进入问答环节,如果确定要回答,则由大模型根据问询和检索到的知识内容进行回答。以下是茴香豆的工作流程图:
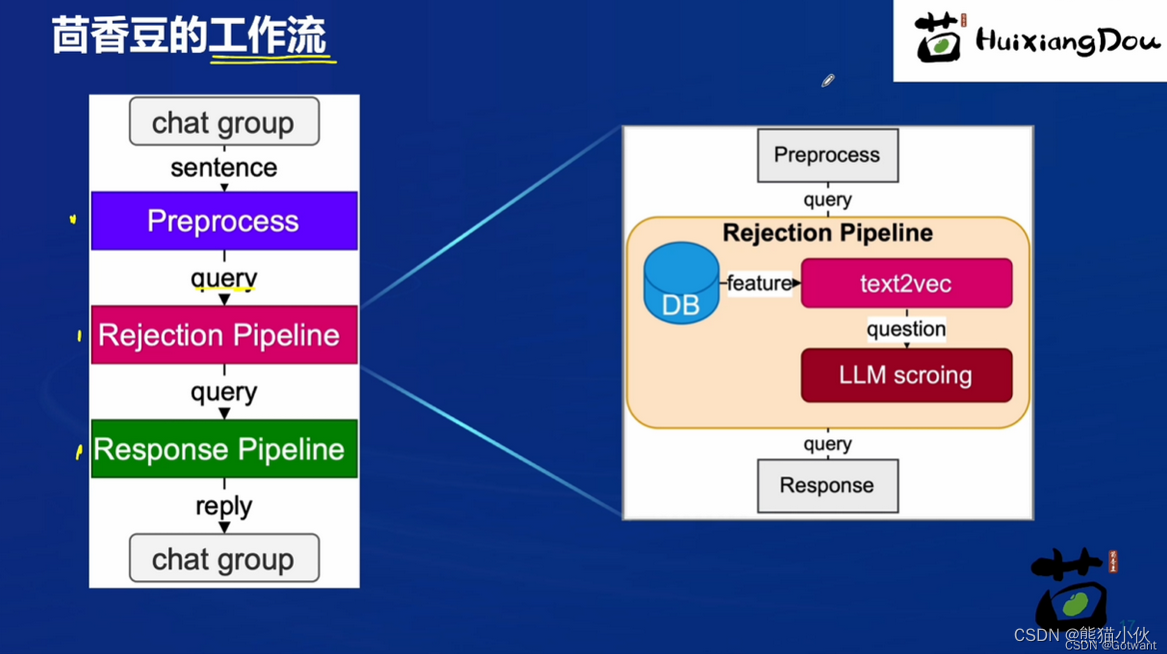
LLM scroing是一个很重要的角色,通过更改它的阈值可以使茴香豆是一个话痨形象还是一个专业技术大师的形象
3 论文快读
《Retrieval-Augmented Generation for Large Language Models: A Survey》
使用通义千问做论文快读,概述如下:
摘要翻译: 大型语言模型(LLMs)虽然展示了令人印象深刻的能力,但在处理特定任务时仍面临一些显著局限,例如编造信息、信息过时、推理过程不透明且不可追溯等问题。为了克服这些挑战,检索增强生成(Retrieval-Augmented Generation, RAG)作为一种有前景的方法出现,它将外部数据库的知识融入LLMs中,从而提高了生成内容的准确性和可信度,特别是在需要大量知识的任务中,还允许持续更新知识并整合领域特定信息。这篇综述论文系统地探讨了RAG范式的演变历程,涵盖了朴素RAG、高级RAG和模块化RAG三个主要发展阶段,并深入剖析了RAG框架的三大核心组成部分——检索、生成和增强技术的最新进展。此外,本文还介绍了最新的评估框架和基准,最后详细阐述了当前面临的问题和未来的研究方向。
论文内容概括(Markdown格式):
摘要
本篇论文重点介绍了大型语言模型(LLMs)在应对如幻觉性生成、过时知识引用和缺乏透明可追溯推理等方面的不足,提出了检索增强生成(RAG)这一解决方案。RAG通过集成外部数据库的知识来提高LLMs的回答质量和可靠性,特别适合于知识密集型任务,并支持实时知识更新和特定领域的知识整合。
第一部分:简介
简述了LLMs的成功及其局限性,指出RAG技术如何通过结合外部知识资源改善LLMs在推理阶段回答复杂知识驱动问题的能力,进而促进了RAG研究领域的迅速发展。作者不仅关注RAG在推理阶段的改进,还强调了与LLMs微调技术的融合。
第二部分:Naive RAG
这部分详细描述了Naive RAG的研究范式,它是最早且最基础的RAG方法,随着ChatGPT普及而受到关注。Naive RAG遵循传统的索引-检索-生成流程,分为以下步骤:
索引阶段:从不同格式的原始数据中提取文本内容,将其转换成统一的纯文本格式,然后分割成易于处理的小块,并使用嵌入模型将其编码为向量形式存储在矢量数据库中。
检索阶段:用户提出查询后,系统利用索引阶段相同的编码模型将查询转化为向量表示,计算查询向量与索引语料库中各个片段向量之间的相似度,选取最相关的前K个片段。
生成阶段:将原始问题和检索到的文档片段组合成一个连贯的提示输入给LLM,促使模型生成最终答案。根据任务需求,LLM可能依据内在参数知识或仅依据提供的文档信息来生成答案,尤其在对话交互场景中可以考虑之前对话的历史上下文。
第三部分:RAG进展与核心技术
该部分系统梳理了超过100项RAG研究,总结了三种主要研究范式(包括朴素RAG、高级RAG和模块化RAG)的发展脉络,深入分析了RAG框架核心阶段“检索”、“生成”和“增强”所使用的先进技术。同时,论文还填补了现有研究在RAG评估方法方面的空白,全面回顾了适用于RAG的各种下游任务、数据集、基准和评估方法。
结论与贡献
本文旨在提供一个详细的、结构化的大型语言模型与RAG方法的理解框架,通过对RAG技术演化过程的梳理,评估不同方法在各自背景下的优缺点,并展望未来的趋势和创新点。主要贡献如下:
对RAG方法进行了全面且系统的回顾,追踪其从朴素RAG到高级阶段的发展路径。
完整总结了RAG应用于各种任务时所使用的数据集和方法,并对用于评估RAG的不同指标进行了汇总。
总体而言,这篇论文既是一个对RAG技术发展历程和技术手段的综合梳理,也是一个对未来RAG研究方向具有指导意义的文献综述。
这篇关于【第3节】“茴香豆“:搭建你的 RAG 智能助理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









