本文主要是介绍只占 1.8G 内存,iPhone上就可以部署的模型,水平相当于GPT-3.5,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
微软的phi-3-mini 模型太强了。4 位量化之后可以部署在 iPhone 14 上,只占用 1.8G 内存,每秒输出 12 个 Token 。
关键他们说这个模型能力上跟 Mixtral 8x7B 和 GPT-3.5 差不多。

详细介绍
一个新型语言模型 phi-3-mini,该模型拥有38亿参数,训练数据高达3.3万亿 Token。
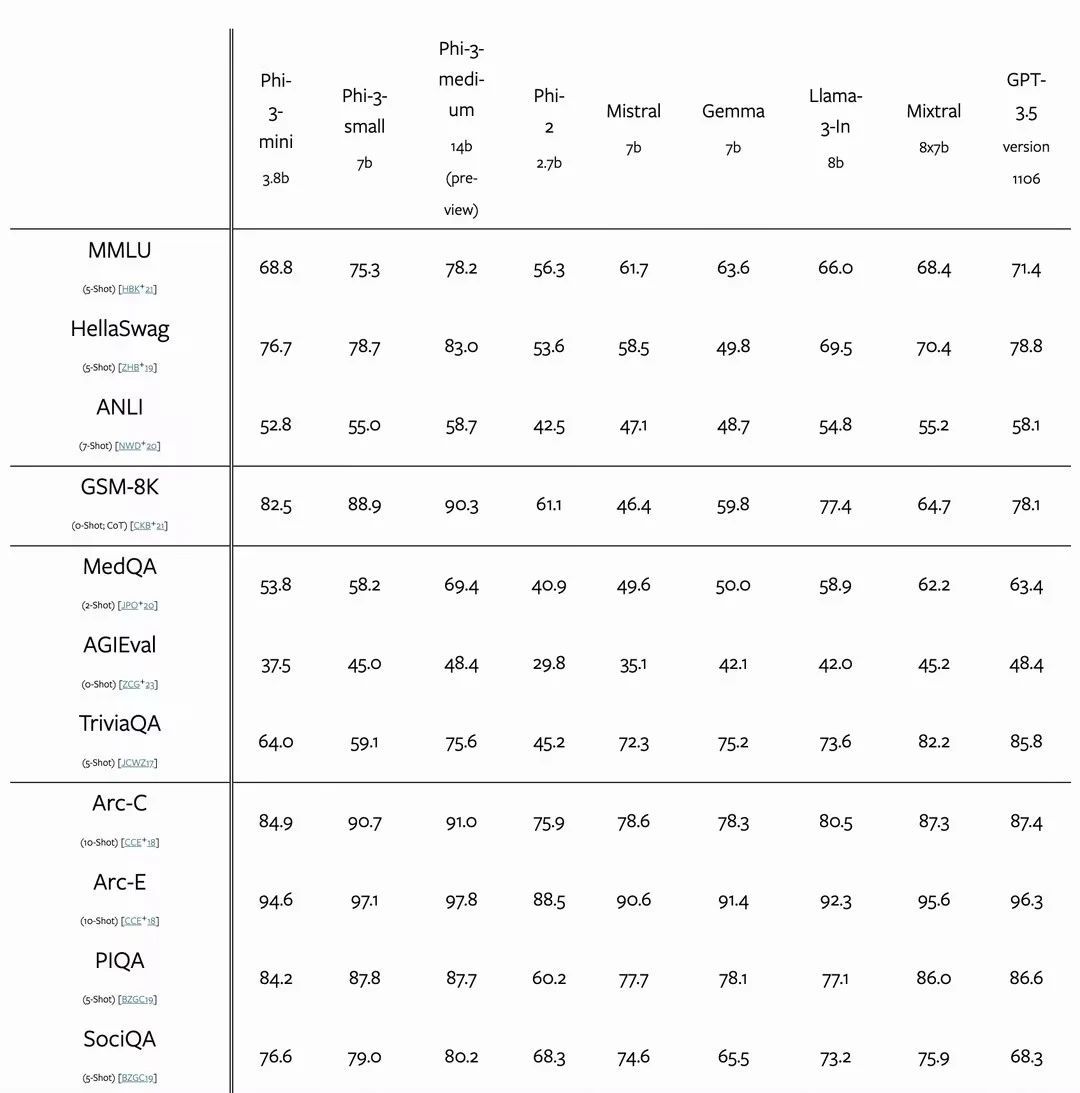
根据学术基准和内部测试,phi-3-mini 的整体性能与 Mixtral 8x7B 和 GPT-3.5 等大型模型相当(例如,在 MMLU 测试中达到69%,在 MT-bench 测试中得分为8.38),但其体积小到足以部署在手机上。
这种创新归功于phi-3-mini的训练数据集,它是 phi-2 所用数据集的扩大版本,包括了经过严格筛选的网络数据和合成数据。此外,这个模型还进一步优化了其鲁棒性、安全性和适应聊天的格式。
微软还初步展示了在训练达4.8万亿 Token 的情况下,使用7B和14B参数的模型(名为 phi-3-small 和 phi-3-medium)所取得的成效,这两个模型的性能均显著优于 phi-3-mini(例如,在 MMLU 测试中分别达到75%和78%,在 MT-bench 测试中分别得分为8.7和8.9)。
技术报告地址:https://arxiv.org/html/2404.14219v1
模型下载:https://huggingface.co/microsoft/Phi-3-mini-128k-instruct-onnx
高性价比GPU资源:https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_tongyong_shemei
这篇关于只占 1.8G 内存,iPhone上就可以部署的模型,水平相当于GPT-3.5的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







