本文主要是介绍Unet网络架构讲解(从零到一,逐行编写并重点讲解数据维度变化),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
📚博客主页:knighthood2001
✨公众号:认知up吧 (目前正在带领大家一起提升认知,感兴趣可以来围观一下)
🎃知识星球:【认知up吧|成长|副业】介绍
❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️
🙏笔者水平有限,欢迎各位大佬指点,相互学习进步!
今天开始讲解一下Unet网络架构以及Pytorch代码构建。
整体架构图
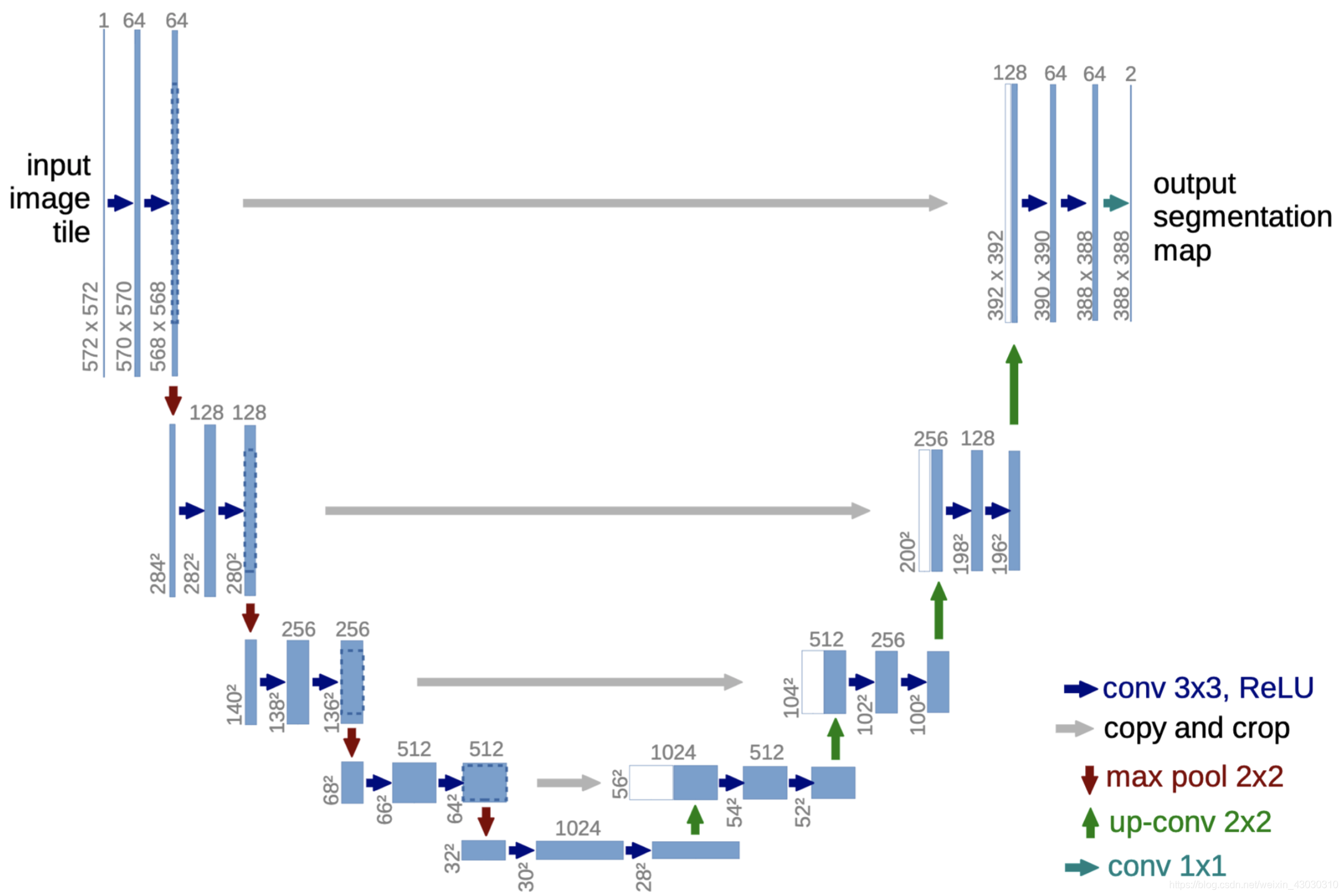
这张图片应该是Unet网络最出名的图片,网络形状像“U”,故被称为U-net。
网络讲解
我觉得很多人对这个网络架构可能还是一知半解的,包括我最初也是这样的。
首先就是这几个箭头表示的是什么,这几个箭头相比于VGG16网络架构,难了不少。
因为VGG16网络架构中只有卷积层、全连接层,不涉及到特别复杂的操作。
conv 3x3,ReLu就是卷积层,其中卷积核大小是3x3,然后经过ReLu激活。copy and crop的意思是复制和裁剪。这块内容我觉得很多人最初和我一样,不明白是什么意思,这里的意思就是对于你输出的尺寸,你需要进行复制并进行中心剪裁。方便和后面上采样生成的尺寸进行拼接。max pool 2x2,就是最大池化层,卷积核为2x2。up-conv 2x2:这里对于初学者来说,是最难领悟的地方,因为看不懂这个符号是啥意思。我最初以为是upsample+conv2d,试了一下,好像生成不了符合要求的尺寸,后来想了一下,这个是不是就是反卷积,用来上采样的,然后试了一下,可以实现,并且卷积核也是2x2。本文中使用的就是ConvTranspose2d()函数进行该操作。conv 1x1这里就是卷积层,卷积核大小是1x1。
网络架构图,大家需要好好理解一下。
以上内容,我会在接下来的文章进行讲解。
左边部分代码讲解
导入包
import torch
import torch.nn as nn
Unet网络的左边部分和VGG16网络结构类似,都是卷积+最大池化,因此这部分讲解,可以看我之前写的这篇文章,里面着重讲了参数如何设置,也希望基础不好的,先去这篇文章补一补。
深度学习VGG16网络构建(Pytorch代码从零到一精讲,帮助理解网络的参数定义)
第一块内容
# 由572*572*1变成了570*570*64self.conv1_1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0)self.relu1_1 = nn.ReLU(inplace=True)# 由570*570*64变成了568*568*64self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) self.relu1_2 = nn.ReLU(inplace=True)
由Unet网络架构图,可以看出输入图像是1x572x572大小,其中的1代表的是通道数(后续可以自己更改成自己想要的,比如3通道),输出通道是64,并且通过conv3x3,得知卷积核为3x3尺寸,并且由图片中的尺寸变成570x570,因此可以得出相关的参数值in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0,整个图片的蓝色箭头的卷积操作都是这样,因此kernel_size=3, stride=1, padding=0可以固定了。只需要更改输入和输出通道数的大小即可。
数据维度变化:1x572x572->64x570x570->64x568x568
最大池化层1
# 采用最大池化进行下采样,图片大小减半,通道数不变,由568*568*64变成284*284*64
self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2)
最大池化的卷积核和步长都设置为2,使得输出尺寸减半,通道数不变。
数据维度变化:64x568x568->64x284x284
第二块内容
self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0) # 284*284*64->282*282*128self.relu2_1 = nn.ReLU(inplace=True)self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 282*282*128->280*280*128self.relu2_2 = nn.ReLU(inplace=True)
数据维度变化:64x284x284->128x282x282->128x280x280
最大池化层2
# 采用最大池化进行下采样 280*280*128->140*140*128
self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2)
最大池化的卷积核和步长都设置为2,使得输出尺寸减半,通道数不变。
数据维度变化:128x280x280->128x140x140
Unet左边部分剩下内容,等等等等(有空补)
Unet左边部分汇总
由Unet网络架构图,可以看出,每经过一次卷积+relu操作,图像尺寸-2,可以得出padding=0(VGG16中padding=1,因此使得图像尺寸不变);每经过一次最大池化,图像尺寸减半。
左边部分代码如下:
class Unet(nn.Module):def __init__(self):super(Unet, self).__init__()self.conv1_1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0) # 由572*572*1变成了570*570*64self.relu1_1 = nn.ReLU(inplace=True)self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) # 由570*570*64变成了568*568*64self.relu1_2 = nn.ReLU(inplace=True)self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样,图片大小减半,通道数不变,由568*568*64变成284*284*64self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0) # 284*284*64->282*282*128self.relu2_1 = nn.ReLU(inplace=True)self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 282*282*128->280*280*128self.relu2_2 = nn.ReLU(inplace=True)self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 280*280*128->140*140*128self.conv3_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=0) # 140*140*128->138*138*256self.relu3_1 = nn.ReLU(inplace=True)self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0) # 138*138*256->136*136*256self.relu3_2 = nn.ReLU(inplace=True)self.maxpool_3 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 136*136*256->68*68*256self.conv4_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=0) # 68*68*256->66*66*512self.relu4_1 = nn.ReLU(inplace=True)self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0) # 66*66*512->64*64*512self.relu4_2 = nn.ReLU(inplace=True)self.maxpool_4 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 64*64*512->32*32*512self.conv5_1 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=0) # 32*32*512->30*30*1024self.relu5_1 = nn.ReLU(inplace=True)self.conv5_2 = nn.Conv2d(1024, 1024, kernel_size=3, stride=1, padding=0) # 30*30*1024->28*28*1024self.relu5_2 = nn.ReLU(inplace=True)
前向传播函数中,你不能将所有对象都写成x,因为这个网络涉及到copy and crop,如果你全部都当作x,那么就无法复制和裁剪了,因为每次都是对最终结果进行复制,而不是中间步骤进行复制。
注意一下,下面的写法是错误的。
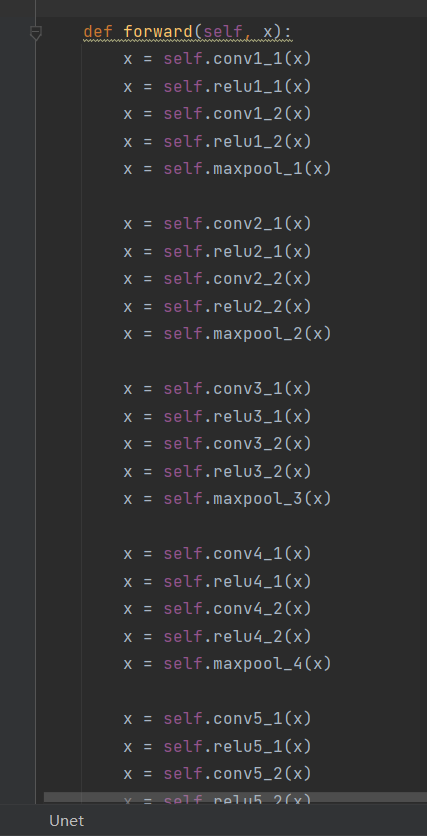
原因是因为Unet网络需要copy,因此你不能将所有层的输出都定义为x。
**正确做法应该是,在最大池化(下采样)之前,你需要有个新变量保存输出的内容,方便后续进行复制和裁剪。**这里不知道你能否听懂。代码如下:
def forward(self, x):x1 = self.conv1_1(x)x1 = self.relu1_1(x1)x2 = self.conv1_2(x1)x2 = self.relu1_2(x2) # 这个后续需要使用down1 = self.maxpool_1(x2)x3 = self.conv2_1(down1)x3 = self.relu2_1(x3)x4 = self.conv2_2(x3)x4 = self.relu2_2(x4) # 这个后续需要使用down2 = self.maxpool_2(x4)x5 = self.conv3_1(down2)x5 = self.relu3_1(x5)x6 = self.conv3_2(x5)x6 = self.relu3_2(x6) # 这个后续需要使用down3 = self.maxpool_3(x6)x7 = self.conv4_1(down3)x7 = self.relu4_1(x7)x8 = self.conv4_2(x7)x8 = self.relu4_2(x8) # 这个后续需要使用down4 = self.maxpool_4(x8)x9 = self.conv5_1(down4)x9 = self.relu5_1(x9)x10 = self.conv5_2(x9)x10 = self.relu5_2(x10)
右边部分代码讲解
右边部分的架构如下,当然,由于Unet网络的特殊性,不能只看右半边。
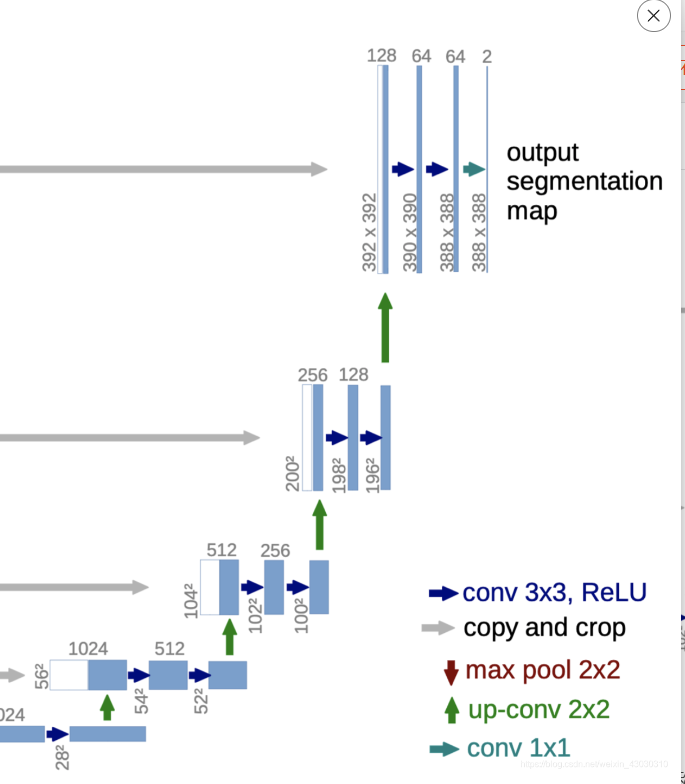
右半部分每一层最开始的数据,由两部分组成,一部分由up-conv 2x2的上采样组成,另外一部风是由左边部分进行复制并进行中心裁剪后得到的,然后对这两部分进行拼接。
以最下面的绿色箭头这部分,举个例子。
最下面的是1024x28x28的图像,经过上采样(绿色箭头),得到512x56x56的图像,尺寸扩大一倍,通道数减半。
然后看最下面的灰色的横向箭头。灰色箭头左边的图像是512x64x64,然后对其进行复制并中心裁剪(中心裁剪是看图得出的),最后得到512x56x56,然后和刚刚说的上采样得到的图像进行拼接,最后得出1024x56x56,我这应该讲的很清楚了。我最开始的时候,这地方没有仔细看图,一直在想到底是如何得出的。
有了上面这个例子,大家应该就能理解右半部分了。
接下来就实现这个上面说的。
注意:我在init中只是定义了上采样的函数,没有涉及到copy and crop,这个我放到forward函数中实现。
下面这四个上采样,就是图片中绿色箭头部分,大家可以关注一下数据维度的变化。
上采样部分代码
# 接下来实现上采样中的up-conv2*2
self.up_conv_1 = nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=2, stride=2, padding=0) # 28*28*1024->56*56*512
数据维度变化:1024x28x28->512x56x56
self.up_conv_2 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=2, stride=2, padding=0) # 52*52*512->104*104*256数据维度变化:512x52x52->256x104x104
self.up_conv_3 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=2, stride=2, padding=0) # 100*100*256->200*200*128
数据维度变化:256x100x100->128x200x200
self.up_conv_4 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=2, stride=2, padding=0) # 196*196*128->392*392*64
数据维度变化:128x196x196->64x392x392
右半部分的卷积
右边部分的卷积层也有四个大层,每个大层经过两个卷积层。
self.conv6_1 = nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=3, stride=1, padding=0) # 56*56*1024->54*54*512self.relu6_1 = nn.ReLU(inplace=True)self.conv6_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0) # 54*54*512->52*52*512self.relu6_2 = nn.ReLU(inplace=True)
数据维度变化:1024x56x56->512x54x54->512x52x52
self.conv7_1 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=3, stride=1, padding=0) # 104*104*512->102*102*256self.relu7_1 = nn.ReLU(inplace=True)self.conv7_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0) # 102*102*256->100*100*256self.relu7_2 = nn.ReLU(inplace=True)
数据维度变化:512x104x104->256x102x102->256x100x100
self.conv8_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=3, stride=1, padding=0) # 200*200*256->198*198*128self.relu8_1 = nn.ReLU(inplace=True)self.conv8_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 198*198*128->196*196*128self.relu8_2 = nn.ReLU(inplace=True)
数据维度变化:256x200x200->128x198x198->128x196x196
self.conv9_1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, stride=1, padding=0) # 392*392*128->390*390*64self.relu9_1 = nn.ReLU(inplace=True)self.conv9_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) # 390*390*64->388*388*64self.relu9_2 = nn.ReLU(inplace=True)
数据维度变化:128x392x392->64x390x390->64x388x388
最后的conv 1x1
# 最后的conv1*1self.conv_10 = nn.Conv2d(in_channels=64, out_channels=2, kernel_size=1, stride=1, padding=0)
这个代码就是最后的conv1x1操作,输入通道数为64,输出通道数为2,卷积核大小为1,步长为1,padding=0,使得
数据维度变化:64x388x388->2x388x388
其中的输出通道数可以根据自己的需要进行更改。
copy and crop的实现,并且实现拼接操作
上面的代码是init中定义好的层,copy and crop操作没有能够直接实现的函数,因此我放到forward函数中。
# 中心裁剪,def crop_tensor(self, tensor, target_tensor):target_size = target_tensor.size()[2]tensor_size = tensor.size()[2]delta = tensor_size - target_sizedelta = delta // 2# 如果原始张量的尺寸为10,而delta为2,那么"delta:tensor_size - delta"将截取从索引2到索引8的部分,长度为6,以使得截取后的张量尺寸变为6。return tensor[:, :, delta:tensor_size - delta, delta:tensor_size - delta]首先我实现了一个这样的函数。这个函数可以帮助我将tensor中心裁剪成target_tensor的尺寸,符合Unet网络的需求。
# 第一次上采样,需要"Copy and crop"(复制并裁剪)up1 = self.up_conv_1(x10) # 得到56*56*512# 需要对x8进行裁剪,从中心往外裁剪crop1 = self.crop_tensor(x8, up1)# 拼接操作up_1 = torch.cat([crop1, up1], dim=1)
这是第一次实现上采样并且进行拼接。
首先up1 = self.up_conv_1(x10)这段代码实现上采样,得到512x56x56的数据,x8就是经过conv4_2和relu操作后,处在左下角灰色箭头左边的数据,其维度是512x64x64,我们需要将其裁剪成up1的形状,因此可以调用self.crop_tensor函数,得到crop1,其维度和up1一样,都是512x56x56。
然后就可以进行拼接,使用torch.cat()函数对张量列表在指定维度上进行拼接,这里就是将crop1和up1进行在通道数维度上的拼接,最后拼接成1024x56x56大小的数据(由unet架构图中可以看出,crop1在前面,up1在后面)。
然后经过两次卷积后,继续上采样,copy and crop,然后进行拼接。
这是第二次的这个过程:上采样+裁剪+拼接
# 第二次上采样,需要"Copy and crop"(复制并裁剪)up2 = self.up_conv_2(y2)# 需要对x6进行裁剪,从中心往外裁剪crop2 = self.crop_tensor(x6, up2)# 拼接up_2 = torch.cat([crop2, up2], dim=1)
同理:经过两次卷积后,继续上采样,copy and crop,然后进行拼接。
这是第三次的这个过程:上采样+裁剪+拼接
# 第三次上采样,需要"Copy and crop"(复制并裁剪)up3 = self.up_conv_3(y4)# 需要对x4进行裁剪,从中心往外裁剪crop3 = self.crop_tensor(x4, up3)up_3 = torch.cat([crop3, up3], dim=1)
同理:经过两次卷积后,继续上采样,copy and crop,然后进行拼接。
这是第四次的这个过程:上采样+裁剪+拼接
# 第四次上采样,需要"Copy and crop"(复制并裁剪)up4 = self.up_conv_4(y6)# 需要对x2进行裁剪,从中心往外裁剪crop4 = self.crop_tensor(x2, up4)up_4 = torch.cat([crop4, up4], dim=1)
最终代码展示
这个代码我敢肯定,这是全网最基础、最简单的代码,但是是最适合小白的代码。
并且我配上了本代码的具体名称对应的层,比如x1就是第一个conv 3x3,大家可以自己对应着看。

import torch
import torch.nn as nnclass Unet(nn.Module):def __init__(self):super(Unet, self).__init__()self.conv1_1 = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=0) # 由572*572*1变成了570*570*64self.relu1_1 = nn.ReLU(inplace=True)self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) # 由570*570*64变成了568*568*64self.relu1_2 = nn.ReLU(inplace=True)self.maxpool_1 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样,图片大小减半,通道数不变,由568*568*64变成284*284*64self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0) # 284*284*64->282*282*128self.relu2_1 = nn.ReLU(inplace=True)self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 282*282*128->280*280*128self.relu2_2 = nn.ReLU(inplace=True)self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 280*280*128->140*140*128self.conv3_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=0) # 140*140*128->138*138*256self.relu3_1 = nn.ReLU(inplace=True)self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0) # 138*138*256->136*136*256self.relu3_2 = nn.ReLU(inplace=True)self.maxpool_3 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 136*136*256->68*68*256self.conv4_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=0) # 68*68*256->66*66*512self.relu4_1 = nn.ReLU(inplace=True)self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0) # 66*66*512->64*64*512self.relu4_2 = nn.ReLU(inplace=True)self.maxpool_4 = nn.MaxPool2d(kernel_size=2, stride=2) # 采用最大池化进行下采样 64*64*512->32*32*512self.conv5_1 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=0) # 32*32*512->30*30*1024self.relu5_1 = nn.ReLU(inplace=True)self.conv5_2 = nn.Conv2d(1024, 1024, kernel_size=3, stride=1, padding=0) # 30*30*1024->28*28*1024self.relu5_2 = nn.ReLU(inplace=True)# 接下来实现上采样中的up-conv2*2self.up_conv_1 = nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=2, stride=2, padding=0) # 28*28*1024->56*56*512self.conv6_1 = nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=3, stride=1, padding=0) # 56*56*1024->54*54*512self.relu6_1 = nn.ReLU(inplace=True)self.conv6_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=0) # 54*54*512->52*52*512self.relu6_2 = nn.ReLU(inplace=True)self.up_conv_2 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=2, stride=2, padding=0) # 52*52*512->104*104*256self.conv7_1 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=3, stride=1, padding=0) # 104*104*512->102*102*256self.relu7_1 = nn.ReLU(inplace=True)self.conv7_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=0) # 102*102*256->100*100*256self.relu7_2 = nn.ReLU(inplace=True)self.up_conv_3 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=2, stride=2, padding=0) # 100*100*256->200*200*128self.conv8_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=3, stride=1, padding=0) # 200*200*256->198*198*128self.relu8_1 = nn.ReLU(inplace=True)self.conv8_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=0) # 198*198*128->196*196*128self.relu8_2 = nn.ReLU(inplace=True)self.up_conv_4 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=2, stride=2, padding=0) # 196*196*128->392*392*64self.conv9_1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, stride=1, padding=0) # 392*392*128->390*390*64self.relu9_1 = nn.ReLU(inplace=True)self.conv9_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0) # 390*390*64->388*388*64self.relu9_2 = nn.ReLU(inplace=True)# 最后的conv1*1self.conv_10 = nn.Conv2d(in_channels=64, out_channels=2, kernel_size=1, stride=1, padding=0)# 中心裁剪,def crop_tensor(self, tensor, target_tensor):target_size = target_tensor.size()[2]tensor_size = tensor.size()[2]delta = tensor_size - target_sizedelta = delta // 2# 如果原始张量的尺寸为10,而delta为2,那么"delta:tensor_size - delta"将截取从索引2到索引8的部分,长度为6,以使得截取后的张量尺寸变为6。return tensor[:, :, delta:tensor_size - delta, delta:tensor_size - delta]def forward(self, x):x1 = self.conv1_1(x)x1 = self.relu1_1(x1)x2 = self.conv1_2(x1)x2 = self.relu1_2(x2) # 这个后续需要使用down1 = self.maxpool_1(x2)x3 = self.conv2_1(down1)x3 = self.relu2_1(x3)x4 = self.conv2_2(x3)x4 = self.relu2_2(x4) # 这个后续需要使用down2 = self.maxpool_2(x4)x5 = self.conv3_1(down2)x5 = self.relu3_1(x5)x6 = self.conv3_2(x5)x6 = self.relu3_2(x6) # 这个后续需要使用down3 = self.maxpool_3(x6)x7 = self.conv4_1(down3)x7 = self.relu4_1(x7)x8 = self.conv4_2(x7)x8 = self.relu4_2(x8) # 这个后续需要使用down4 = self.maxpool_4(x8)x9 = self.conv5_1(down4)x9 = self.relu5_1(x9)x10 = self.conv5_2(x9)x10 = self.relu5_2(x10)# 第一次上采样,需要"Copy and crop"(复制并裁剪)up1 = self.up_conv_1(x10) # 得到56*56*512# 需要对x8进行裁剪,从中心往外裁剪crop1 = self.crop_tensor(x8, up1)up_1 = torch.cat([crop1, up1], dim=1)y1 = self.conv6_1(up_1)y1 = self.relu6_1(y1)y2 = self.conv6_2(y1)y2 = self.relu6_2(y2)# 第二次上采样,需要"Copy and crop"(复制并裁剪)up2 = self.up_conv_2(y2)# 需要对x6进行裁剪,从中心往外裁剪crop2 = self.crop_tensor(x6, up2)up_2 = torch.cat([crop2, up2], dim=1)y3 = self.conv7_1(up_2)y3 = self.relu7_1(y3)y4 = self.conv7_2(y3)y4 = self.relu7_2(y4)# 第三次上采样,需要"Copy and crop"(复制并裁剪)up3 = self.up_conv_3(y4)# 需要对x4进行裁剪,从中心往外裁剪crop3 = self.crop_tensor(x4, up3)up_3 = torch.cat([crop3, up3], dim=1)y5 = self.conv8_1(up_3)y5 = self.relu8_1(y5)y6 = self.conv8_2(y5)y6 = self.relu8_2(y6)# 第四次上采样,需要"Copy and crop"(复制并裁剪)up4 = self.up_conv_4(y6)# 需要对x2进行裁剪,从中心往外裁剪crop4 = self.crop_tensor(x2, up4)up_4 = torch.cat([crop4, up4], dim=1)y7 = self.conv9_1(up_4)y7 = self.relu9_1(y7)y8 = self.conv9_2(y7)y8 = self.relu9_2(y8)# 最后的conv1*1out = self.conv_10(y8)return out
if __name__ == '__main__':input_data = torch.randn([1, 1, 572, 572])unet = Unet()output = unet(input_data)print(output.shape)# torch.Size([1, 2, 388, 388])
这段代码包括空行在内,一共写了160行++,因为我是初学者,我懂初学者的痛。
网上的代码是经过封装的,因为Unet网络中涉及到很多重复的操作,大家为了简便代码,都通过定义相同操作的类,通过调用,从而减少代码量,使得代码看起来简短一些。但是这就不利于初学者去学习了,因为一般,大家都不喜欢嵌套,跳来跳去会容易晕(除非你一步一步debug)。
正是由于这一点,我才花了很多时间,来写这个博客,想着从初学者的角度,如何逐行编写网络结构。
后续也会打算从这篇文章开始,把重复操作的步骤,通过定义成类,进行调用,从而使得代码简短一些,也更加符合大佬们的写法。
我相信,经过这两天,VGG16+Unet网络架构从零到一的编写,大家的能力会得到很大的提升。
本文如有错误或者不合理的地方,请指出(笔者没有去看过原作者的paper,是根据Unet网络架构图和网上的资料进行编写的),谢谢!!
这篇关于Unet网络架构讲解(从零到一,逐行编写并重点讲解数据维度变化)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








