本文主要是介绍【InternLM】XTuner微调LLM,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 大模型微调基本理论
1.1 概述
LLM大模型的参数量以B(10亿)为单位,动辄迁百亿、千亿。如何在已经训练好的、性能优异的底座模型基础上,通过微调的方式,来实现对模型的性能优化、知识注入、领域迁移和风格对齐等调整,是一件非常有使用场景的工作。
1.2 增量微调&指令微调
按照微调阶段来分,微调可分为增量微调和指令微调。
增量微调可理解为BERT时代的post-training,即通过灌入大量的垂直领域语料,通过自回归的方式来进行模型的继续训练,其一般用于增强大模型的领域知识,补充底座模型在专业领域的不足。
经过增量微调后的大模型并没有对话能力。而指令微调的目的就是让模型具备对话能力。指令微调通过收集大量的<指令,回复>数据对,得到一个指令跟随数据集。然后用指令数据集通过有监督的方式对前面训练得到的LLM进行指令调优,得到SFT模型。到这一步得到的SFT模型已经能实现和人类很好的对齐。
1.3 全参数微调 VS 高效微调(PEFT)
从模型权重更新的比例来分,微调可分为全参数微调和高效微调。
全参数微调即在微调过程中更新全部的权重参数。但大型预训练模型的训练成本非常高昂,需要庞大的计算资源和大量的数据,一般人难以承受。
为了解决这个问题,研究人员开始研究 Parameter-Efficient Fine-Tuning (PEFT) 技术,即通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。这样一来,即使计算资源受限,也可以利用预训练模型的知识来迅速适应新任务,实现高效的迁移学习。因此,PEFT 技术可以在提高模型效果的同时,大大缩短模型训练时间和计算成本,让更多人能够参与到深度学习研究中来。
常用的PEFT方法,包括 Adapter Tuning、Prompt Tuning、Prefix Tuning、P-Tuning、P-Tuning v2 、LoRA、QLoRA和 [AdaLoRA](Adaptive budget allocation for parameter-efficient fine-tuning)等。
参考使用的PEFT库推荐HF的peft。
下面本文着重介绍Xtuner目前支持的两种peft方法:LoRA和QLoRA。
1.3.1 LoRA
LoRA是目前被使用最广泛的peft方法,不光在LLM,在CV领域也被广泛采用。相较于其他算法的一些固有缺陷,LoRA的实测效果更佳稳定和优异。
Adapter Tuning 增加了模型层数,引入了额外的推理延迟
Prefix-Tuning 难于训练,且预留给 Prompt 的序列挤占了下游任务的输入序列空间,影响模型性能
P-tuning v2 很容易导致旧知识遗忘,微调之后的模型,在之前的问题上表现明显变差
LoRA的全称为LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS。故名思意,是一种低秩的adpater技术。其原理来源于前人对内在维度(intrinsic dimension)的发现:
模型是过参数化的,它们有更小的内在维度,模型主要依赖于这个低的内在维度(low intrinsic dimension)去做任务适配。
LoRA 允许我们通过优化适应过程中密集层变化的秩分解矩阵,来间接训练神经网络中的一些密集层,同时保持预先训练的权重不变。
其具体做法是在模型的某些层(一般是多头注意力层)中添加旁路(类似于残差网络)来模拟模型的intrinsic rank。这个旁路由两部分组成:先是一个降维矩阵A,再是一个升维矩阵B(类似于AutoEncoder进行参数的降维),A初始化为高斯分布的矩阵,而B初始化为全零矩阵,从而既保证了合并模型的无损,又保证了训练的可进行。
在微调过程中,固定原模型权重,只微调矩阵A和B的权重。而在训练完毕后,通过两部分权重的叠加即可以得到最终的模型权重。
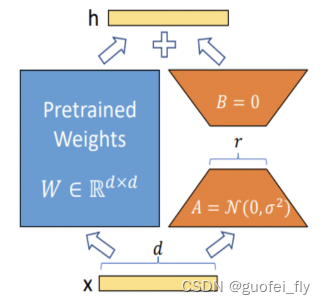
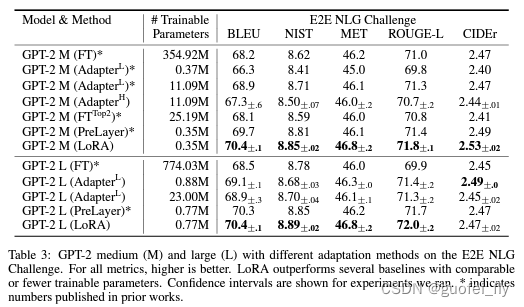
LoRA的结构设计几乎没有影响推理速度,且论文的对比结果表明相较于其他的peft方法有明显优势:
1.3.2 QLoRA
QLoRA是在LoRA基础上的量化。模型本身用4bit加载,训练时把数值反量化到bf16后进行训练,利用LoRA
可以锁定原模型参数不参与训练,只训练少量LoRA参数的特性使得训练所需的显存大大减少。其采用了双重量化、Page Optimizer等工程技术,使得在尽量保证精度的同时,支持优化器状态在GPU和内存间的传输,进一步减小了显存消耗。
2. XTuner介绍
Xtuner是上海人工智能实验室推出的用于LLM微调的一站式工具,其:
1)模型方面:支持InternLM、Qwen、Baichuan、ChatGLM等国内主流开源大模型,以及Llama、Mixtral和Gemma等国外优秀开源大模型;
2)数据方面:提供了MOSS、Alpca等微调数据集的快速获取和格式归一化脚本,让开发者能够快速解决繁杂的数据预处理环节;
3)微调pipeline方面:支持增量预训练和指令微调(包括单轮对话sft和多轮对话sft);
4)微调策略:目前支持LoRA、QLoRA等轻量级微调策略,同时也支持全参数的微调。

3. 利用XTuner微调InterLM2-Chat-1.8B
3.1 对话数据集构建
采用人工构造+角色数据集+开源对话数据集的方式构造数据集,整个数据集采用OpenAI格式的数据结构。
1)人工构造数据集
人工构造数据集主要为了解决Bot的自我识别问题,能够顺利回答自我介绍、你好等问候语句,构造的数据类似于:
{"messages": [{"role": "user","content": "请做一下自我介绍"},{"role": "assistant","content": "你好,我是大侠乔峰,内在是上海AI实验室书生·浦语的1.8B大模型哦"}]}
为了加强模型的自我认知,对这批数据进行了100倍的复制。
2)角色数据集
角色数据集的目的是使得机器人能够进行个性化的对话,赋予机器人角色属性。参照角色对话数据开源项目中的乔峰角色进行数据集的清洗。原始的数据类似于:
阿朱:「乔大爷,我……我在这里已等了你五日五夜,我只怕你不能来。你……你果然来了,谢谢老天爷保●,你终于安好无恙。」
乔峰:「你怎地在这里等了我五日五夜?我……你怎知我会到这里来?」
清洗构造后的数据类似于:
{"messages": [{"role": "user","content": "乔大爷,我……我在这里已等了你五日五夜,我只怕你不能来。你……你果然来了,谢谢老天爷保●,你终于安好无恙。"},{"role": "assistant","content": "你怎地在这里等了我五日五夜?我……你怎知我会到这里来?"}]}
共清晰整理出88条单轮对话,考虑到数据量较小,复制30倍进行数据增强。
3)开源对话数据集
为了在预训练中减小过拟合和模型的遗忘灾难,又选用了一定比例的通用数据集alpaca-gpt4-data-zh
进行数据混合。其原格式为:
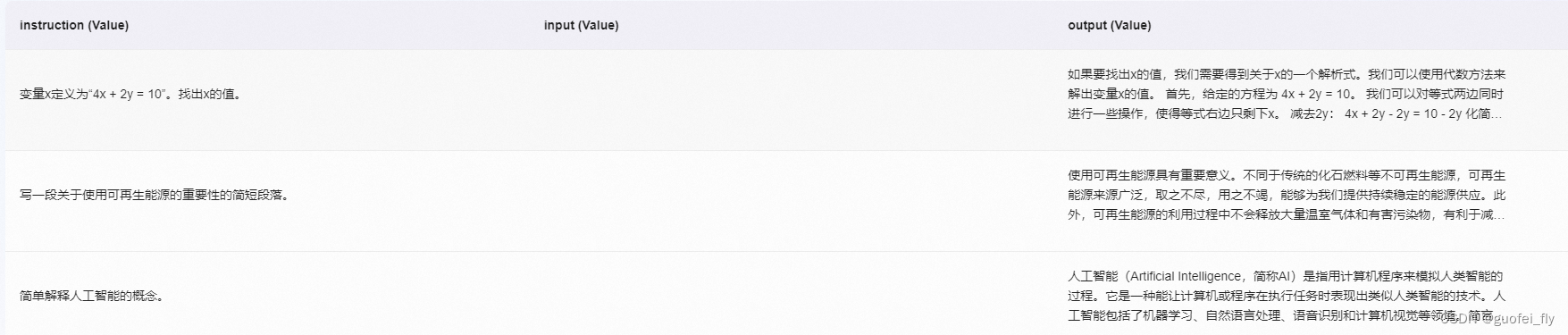
该数据集共有48818,考虑到上述人工构造数据集和角色数据集数据量均较小,因此降采样4000条作为最终的微调数据集。样例为:
{"messages": [{"role": "user","content": "设计一个适用于大约500人的公司的员工认可计划。"},{"role": "assistant","content": '一个有效的员工认可计划对于提升员工士气和期望度是至关重要的。这里有一个适用于大约500人公司的计划设计建议:\n\n1. 设立奖项:“优秀员工奖”和“团队合作奖”是两个可以建立的奖项。"优秀员工奖"旨在表彰那些在工作中表现出色、可靠且贡献突出的员工。而“团队合作奖”则表彰那些成功完成项目并与团队成员保持良好合作的团队。\n\n2. 设定提名和评选机制: 确保员工认可计划公平公正,应该由同事、上级管理人员或客户提名候选人。其次,应设立独立的评审委员会,由管理团队和员工代表组成。\n\n3. 提供丰厚奖励:所获奖项不应只是一张证书或荣誉称号。为了真正激励员工,公司应提供实质性的奖励。如:现金奖、旅行券、额外的休假时间或者升职机会。\n\n4. 组织颁奖典礼:每年或每季度举办一次颁奖典礼, 公开赞扬和表彰那些表现优秀的员工和团队。 颁奖典礼是一个重要的仪式,可以在全公司范围内传递积极的信息并提升公司文化。\n\n5. 保持持续性:员工认可计划不应仅仅作为一次性活动,而应持续进行并并入公司文化之中。'}]}
4) 合并数据集
最终得到人工构造数据集、角色数据集和开源对话数据集的条数分别为500、2640和4000,合并上述数据集合随机打乱,构造出最后用于微调的训练数据集。
3.2 模型微调
3.2.1 基本配置
选用internlm2-chat-1_8b作为基座模型,可通过如下命令行查看适合该模型微调的配置文件:
xtuner list-cfg -p internlm2_1_8b
得到两个支持internlm2-chat-1_8b的模型配置文件:
==========================CONFIGS===========================
PATTERN: internlm2_1_8b
-------------------------------
internlm2_1_8b_full_alpaca_e3
internlm2_1_8b_qlora_alpaca_e3
根据名字,不难猜出,两者分别为采用全参数和qlora算法的高效微调,建议数据集为alpaca(因此在前文选用开源语料时也采用了该数据集),建议的epoch为3。
采用Xtuner工具箱中提供的copy-cfg即可将该配置文件复制到指定目录下。
xtuner copy-cfg internlm2_1_8b_qlora_alpaca_e3 /root/ft/config
然后便可以根据自己的需求进行配置调整,这里直接采用https://github.com/InternLM/Tutorial/tree/camp2/xtuner中建议的配置。
3.2.2 常规训练
直接调用xtuner train命令即可开始微调训练:
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train
训练过程中的日志如下截图:
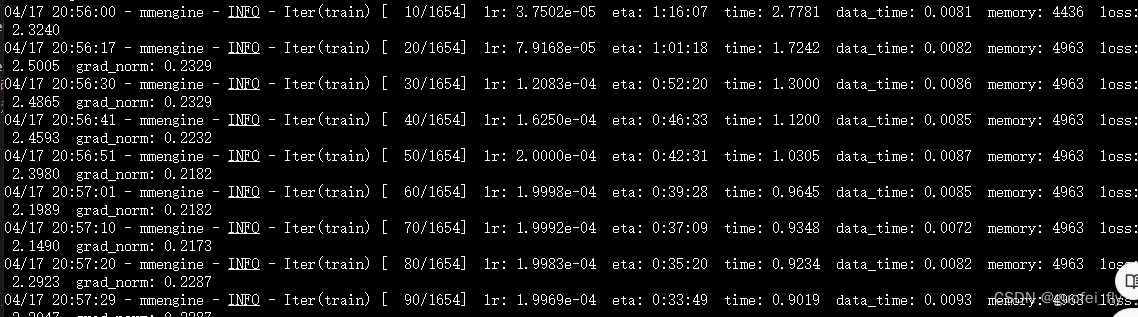
显存占用情况只有6G左右,可见1.8B的模型非常适合入门学习和链路跑通:

整个模型加载、数据加载和训练耗时1小时15分钟左右,还是比较耗时的。因此下面采用Xtuner支持的deepspeed来进行加速。
3.2.3 使用 deepspeed 来加速训练
DeepSpeed是由微软开发的深度学习优化库,旨在提高大规模模型训练的效率和速度。它通过几种关键技术来优化训练过程,包括模型分割、梯度累积、以及内存和带宽优化等。DeepSpeed特别适用于需要巨大计算资源的大型模型和数据集。
在DeepSpeed中,zero 代表“ZeRO”(Zero Redundancy Optimizer),是一种旨在降低训练大型模型所需内存占用的优化器。ZeRO 通过优化数据并行训练过程中的内存使用,允许更大的模型和更快的训练速度。ZeRO 分为几个不同的级别,主要包括:
deepspeed_zero1:这是ZeRO的基本版本,它优化了模型参数的存储,使得每个GPU只存储一部分参数,从而减少内存的使用。
deepspeed_zero2:在deepspeed_zero1的基础上,deepspeed_zero2进一步优化了梯度和优化器状态的存储。它将这些信息也分散到不同的GPU上,进一步降低了单个GPU的内存需求。
deepspeed_zero3:这是目前最高级的优化等级,它不仅包括了deepspeed_zero1和deepspeed_zero2的优化,还进一步减少了激活函数的内存占用。这通过在需要时重新计算激活(而不是存储它们)来实现,从而实现了对大型模型极其内存效率的训练。
选择哪种deepspeed类型主要取决于你的具体需求,包括模型的大小、可用的硬件资源(特别是GPU内存)以及训练的效率需求。一般来说:
如果你的模型较小,或者内存资源充足,可能不需要使用最高级别的优化。
如果你正在尝试训练非常大的模型,或者你的硬件资源有限,使用deepspeed_zero2或deepspeed_zero3可能更合适,因为它们可以显著降低内存占用,允许更大模型的训练。
选择时也要考虑到实现的复杂性和运行时的开销,更高级的优化可能需要更复杂的设置,并可能增加一些计算开销。
在Xtuner中通过配置deepspeed 既可以使用指定类型的加速方案:
# 使用 deepspeed 来加速训练
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train_deepspeed --deepspeed deepspeed_zero2
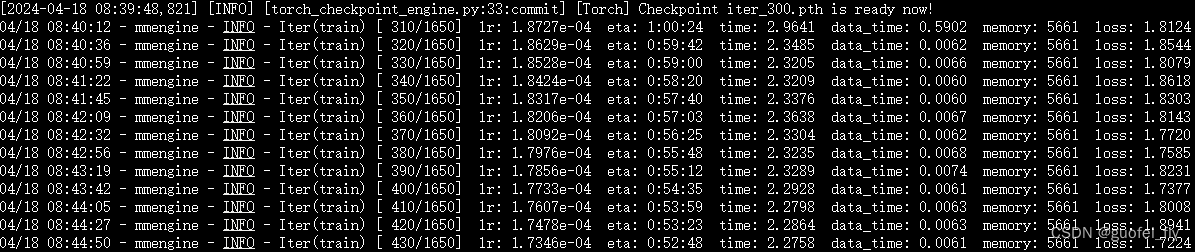
整个模型加载、数据加载和训练耗时降低到1小时左右,有所下降。而显存相较会多一些,达到7.7G。

3.2.4 训练结果简单评估
在配置文件中设置了如下三个问题,用于在模型训练过程中对checkpoint进行简单的评测:
evaluation_inputs = ['请你介绍一下你自己', '你是谁', '你是我的小助手吗']
选取300轮和600轮的结果进行比较,发现模型已经学会了自我识别。但不难发现300轮的回答更加妥帖,而第600轮已经有过拟合的趋势了:
# 300轮
Eval output 1:
<s><|User|>:请你介绍一下你自己
<|Bot|>:你好,我是大侠乔峰,是上海AI实验室书生·浦语的1.8B大模型哦</s>Eval output 2:
<s><|User|>:你是谁
<|Bot|>:你好,我是大侠乔峰,你有什么事吗?</s>Eval output 3:
<s><|User|>:你是我的小助手吗
<|Bot|>:是的,我是大侠乔峰,你好。</s># 600轮
Eval output 1:
<s><|User|>:请你介绍一下你自己
<|Bot|>:你好,我是大侠乔峰,内在是上海AI实验室书生·浦语的1.8B大模型哦</s>Eval output 2:
<s><|User|>:你是谁
<|Bot|>:你好,我是大侠乔峰,内在是上海AI实验室书生·浦语的1.8B大模型哦</s>Eval output 3:
<s><|User|>:你是我的小助手吗
<|Bot|>:你好,我是大侠乔峰,内在是上海AI实验室书生·浦语的1.8B大模型哦</s>
3.3 模型转换、整合、测试及部署
3.3.1 模型转换
将Xtune训练出来的Pytorch权重文件(.pth)转换为目前通用的HF格式(.bin):
xtuner convert pth_to_hf /root/ft/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train/iter_1200.pth /root/ft/huggingface
此时,huggingface 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”,文件夹中共包含4份文件:
3.3.2 模型整合
训练完的模型只是额外的adapter层,需要与原模型进行组合才能被正常使用推理。
利用Xtuner提供的整合指令,传入原模型的地址、训练好的 adapter 层的地址(转为 Huggingface 格式后保存的部分)以及最终保存的地址,即可以得到最终整合好后的模型:
# 解决一下线程冲突的 Bug
export MKL_SERVICE_FORCE_INTEL=1# 进行模型整合
xtuner convert merge ${NAME_OR_PATH_TO_LLM} ${NAME_OR_PATH_TO_ADAPTER} ${SAVE_PATH}
3.3.3 对话测试
在 XTuner 中提供了一套基于 transformers 的对话代码,可以直接在终端与 Huggingface 格式的模型进行对话操作。只需要准备转换好的模型路径并选择对应的提示词模版(prompt-template)即可进行对话。假如 prompt-template 选择有误,很有可能导致模型无法正确的进行回复(想要了解具体模型的 prompt-template 或者 XTuner 里支持的 prompt-tempolate,可以到 XTuner 源码中的 xtuner/utils/templates.py 这个文件中进行查找。)。
1)直接训练的模型
采用三类问题来对直接训练(未用deepspeed加速)的模型进行测试:
- 自我认知类问题。可见模型已经能够认识到自己为大侠乔峰;
- 领域类问题(天龙八部)。模型能够回答一些相关的问题,不过回答质量不高。当问即与阿朱的关系时候,模型仍然保持了原始模型无感情的特点,估计是因为语料中并没有此类对话。
- 通用知识。模型仍保持了对通用知识的回答能力。

2)deepspeed的模型
类似的对经过deepspeed加速后得到的模型进行测试:
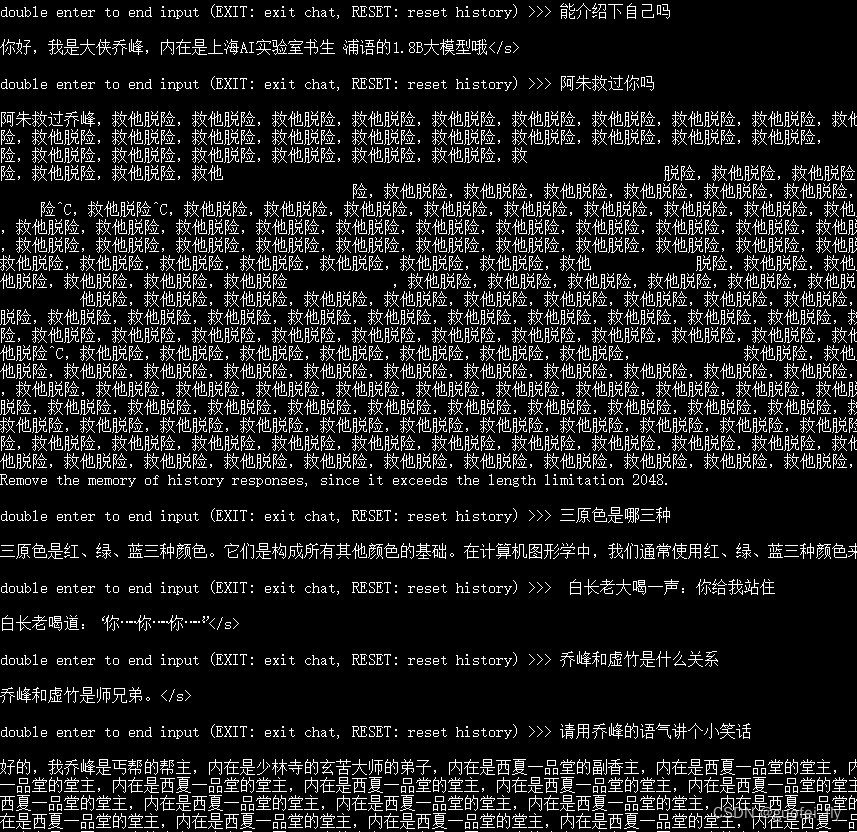
回答中有明显的循环输出问题。
3.3.4 web部署和测试
参照Web demo 部署进行模型的部署。

可见,模型会有一些尝试性错误,对于天龙八部风格的问题回答的也比较奇怪。
3.3.5 OpenXLab 部署
OpenXLab 浦源平台以开源为核心,旨在构建开源开放的人工智能生态,促进学术成果的开放共享。OpenXLab面向 AI 研究员和开发者提供 AI 领域的一站式服务平台,包含数据集中心、模型中心和应用中心,致力于推动人工智能对产学研各领域全面赋能,为构建人工智能开放生态,推动人工智能科研与技术突破、交叉创新和产业落地提供全方位的平台支撑。
参照文档在OpenXLab 部署上述模型。
1)模型上传
在OpenXLab上建立git仓库,通过git lfs管理模型大文件。将上面训练和整合完的最终模型加入仓库,push到平台上。
2)web-ui 开发
创建一个新的 GitHub 仓库来存放基于 gradio的前端 应用代码。入口函数app.py代码为:
import gradio as gr
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoModel# download qiaofeng_chatbot to the base_path directory using git tool
base_path = './qiaofeng_chatbot'
os.system(f'git clone https://code.openxlab.org.cn/Godfrey/qiaofeng_chatbot.git {base_path}')
os.system(f'cd {base_path} && git lfs pull')tokenizer = AutoTokenizer.from_pretrained(base_path,trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(base_path,trust_remote_code=True, torch_dtype=torch.float16).cuda()def chat(message,history):for response,history in model.stream_chat(tokenizer,message,history,max_length=2048,top_p=0.7,temperature=1):yield responsegr.ChatInterface(chat,title="qiaofeng_chatbot",description="""
qiaofeng_chatbot is developed by Godfrey based on internlm2-chat-1_8b. """,).queue(1).launch()
3) 部署应用
最终部署的应用见:乔峰机器人
4. 利用XTuner微调llava多模态模型
参照xtuner_llava.md进行学习和微调。
4.1 模型简介
微调的目的是为了创建一个文+图——>文的大模型,在LLM的基础上有两种典型思路:
1)文本编码器+图片编码器 联合训练;
2)将文本编码器作为单纯的Encoder,只训练图片测的编码器,将两者的向量空间进行对齐。
本项目采用的是思路2):
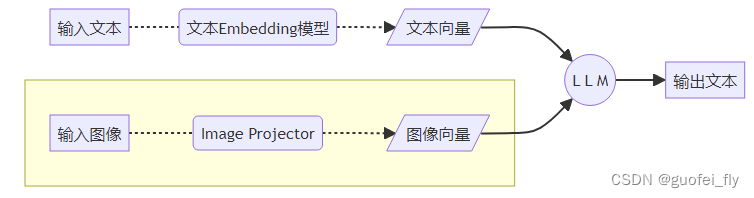
Haotian Liu等使用GPT-4V对图像数据生成描述,以此构建出大量<question text><image> – <answer text>的数据对。利用这些数据对,配合文本单模态LLM,训练出一个Image Projector。其整体模型结构如下图:
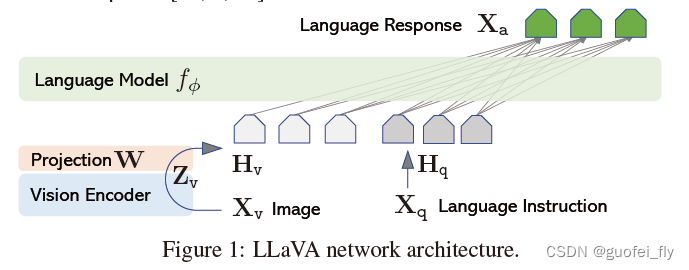
在训练阶段,将原始图片经过Vision Encoder提取特征后,通过现象投影层W映射到文本特征向量空间;然后利用LLM+自回归的训练思路来微调投影层W(固定住LLM权重)。在测试阶段,将图片经过Image Projector进行编码,和文本编码一起喂入LLM生成文本结果。上述过程非常类似于上一节中的LoRA微调方案。
4.2 微调整体思路
训练Image Projector文件的过程包括两个阶段:Pretrain和Finetune。

Pretrain阶段利用图片+标题(短文本)的数据进行,因为这部分数据较容易获取、数据量也大,可以在一定程度让LLM理解图片的图片特征。但是由于训练数据中都是图片+图片标题,所以此时的模型虽然有视觉能力,但无论用户问它什么,它都只会回答输入图片的标题。
而Finetune阶段则利用图片+复杂对话文本,采用这种高质量的数据集可以让模型具备图片问答的能力。
xtuner_llava.md中已经给出了Pretrain阶段的产物,因此下面仅需要进行第二阶段的fineune。
4.3 Finetune
4.3.1 训练数据集构建
用于finetune的数据集格式如下:
[{"id": "随便什么字符串","image": "图片文件的相对位置。相对谁?相对你后面config文件里指定的image_folder参数的路径。","conversation": [{"from": "human","value": "<image>\n第1个问题。"},{"from": "gpt","value": "第1个回答"},{"from": "human","value": "第2个问题。"},{"from": "gpt","value": "第2个回答"},# ......{"from": "human","value": "第n个问题。"},{"from": "gpt","value": "第n个回答"},]},# 下面是第2组训练数据了。{"id": "随便什么字符串","image": "图片文件的相对位置。相对谁?相对你后面config文件里指定的image_folder参数的路径。","conversation": [{"from": "human","value": "<image>\n第1个问题。"},# ......{"from": "gpt","value": "第n个回答"}]}
]
4.3.2 模型微调
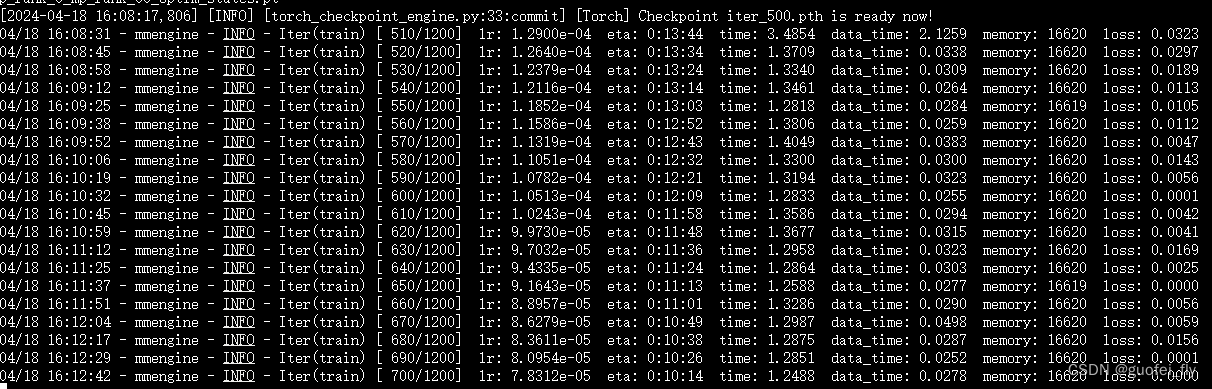
训练过程截图如下,可见到700轮左右loss已经降至0左右,有一定过拟合的可能。
训练玩模型在问题上的回答如下:
04/18 16:24:36 - mmengine - INFO - Sample output:
<|im_start|>user
<image>
What is the equipment in the image?<|im_end|>
<|im_start|>assistant
The equipment in the image is a phoropter, a common optometric device. It's used to measure the patient's vision and to determine an appropriate prescription for eyeglasses or contact lenses.<|im_end|>04/18 16:24:41 - mmengine - INFO - Sample output:
<|im_start|>user
<image>
How many person are in this image?<|im_end|>
<|im_start|>assistant
The image shows two individuals. One is a man in a white lab coat who appears to be an optometrist. He is focused on the equipment, likely adjusting it for the examination. The other is a woman with her chin resting on the machine's support, presumably the patient, undergoing an eye examination.<|im_end|>
可见回答还是相当准确的。下面用中文来提问,回答的也是英文(囧):

及时在prompt中强制用中文回答,也仍是英文:

改用pretrain阶段的中间产物来进行回答,可见无论问什么其只能回答标题。这充分说明了训练语料格式和质量的重要性:
5. 参考资料
- https://github.com/InternLM/Tutorial/tree/camp2/xtuner
- https://github.com/InternLM/xtuner
- https://github.com/microsoft/DeepSpeed
- https://github.com/huggingface/peft
- 大模型微调总结
- LORA:大模型轻量级微调
- QLoRA: 4bit量化+LoRA训练=瞬间起飞
- 从零训练一个多模态LLM:预训练+指令微调+对齐+融合多模态+链接外部系统
这篇关于【InternLM】XTuner微调LLM的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)