本文主要是介绍第6章 数据结构化与数据存储(6.1数据结构化神器——pandas库,读取网页中的表格数据),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 通过pandas库可以方便地爬取网页中的表格数据,对数据进行结构化处理,并导出为Excel工作簿等文件。
6.1.1用read_html()函数快速爬取网页表格数据
- 使用pandas库中的read_html()函数可以快速爬取网页中的表格数据。用搜索引擎搜索并打开“新浪财经数据中心”,然后选择“投资参考”中的“大宗交易”,如下图所示。下面就以爬取该页面(http://vip.stock.finance.sina.com.cn/q/go.php/vInvestConsult/kind/dzjy/index.phtml)中的表格为例,讲解read_html()函数的用法。

- 如果用传统方法解析每一个表格数据,会非常繁琐,而用read_html()函数来完成则会非常方便快捷,代码如下:
import pandas as pd
url = 'http://vip.stock.finance.sina.com.cn/q/go.php/vInvestConsult/kind/dzjy/index.phtml'
table = pd.read_html(url)[0] #核心代码
table #这是Jup中打印输出变量的方法
- 第3行代码用read_html()函数通过访问网址来爬取网页,它会自动提取网页上所有表格,并以列表的形式返回,网页中有几个表格,列表中就有几个元素。这里虽然只有一个表格,但是仍需要通过[0]的方式提取列表中的第1个元素。
- 最终的爬取结果如下图所示,可以看到成功爬取到表格。

- 上面这个例子中的网页没有反爬措施,相对容易爬取。实战中还有很多网页是动态渲染的,通过read_html()函数访问网址的方式无法爬取,需要先用Selenium库获取网页源代码,再用read_html()函数从源代码中提取表格数据。将read_html()函数的这两种用法总结于下表,6.2节会讲解具体案例。

6.1.2 pandas库在爬虫领域的核心代码知识
- read_html()函数只是pandas库强大功能的冰山一角,本节将讲解pandas库在爬虫领域更多核心代码知识。
1.创建DataFrame
- DataFrame是pandas库用于组织和管理数据的一种二维表格数据结构,可以将其看成一个Excel表。创建DataFrame常用的方法有两种:通过列表创建和通过字典创建。
(1)通过列表创建DataFrame
- 通过列表创建DataFrame有两种方法。第1中方法的代码如下:
import pandas as pd
a = pd.DataFrame([[1,2],[3,4],[5,6]])
a
- 在jup中打印输出a,结果如下,该二维表格会自动创建数字序号形式(从0开始)的行索引和列索引。
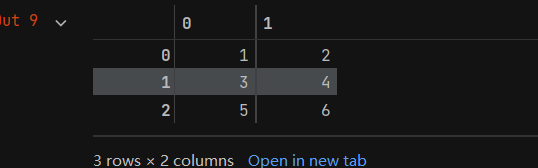
- 我们还可以在创建DataFrame时自定义列索引和行索引,代码如下:
import pandas as pd
a = pd.DataFrame([[1,2],[3,4],[5,6]],columns=['date','score'],index=['A','B','C'])
a
- 通过DataFrame代表列索引,index代码行索引,此时a的打印输出结果如下:
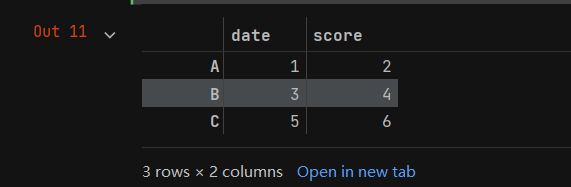
- 通过DataFrame的columns属性可以查看和修改列索引,代码如下:
print(a.columns) #查看列索引
a.columns = ['日期','分数'] #修改列索引,在6.2节会用到
- 第二种方法较为灵活,无须知道数据的具体数量,直接将列表拼接成列即可。该方法在实战中很常用(在6.3节会用到),演示代码如下:
a = pd.DataFrame() #创建一个空DataFrame,用于存储之后要拼接的列数据
date = [1,3,5]
score = [2,4,6]
a['日期'] = date
a['分数'] = score
a
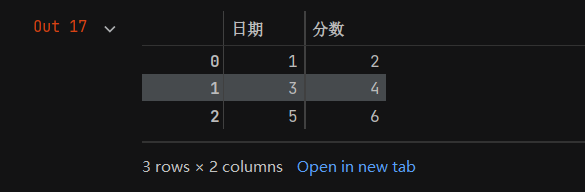
(2)通过字典创建DataFrame
- 通过字典创建DataFrame的代码如下:
# 通过字典创建DataFrame
b = pd.DataFrame({'date':[1,2,3],'score':[2,4,6]})
b
- b的打印输出结果如下,可以看到以字典的键名作为列索引。
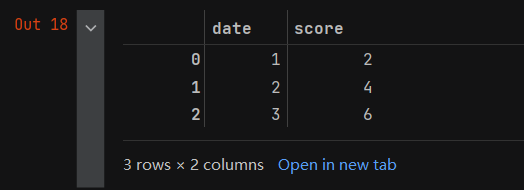
2.数据文件的读取和写入
- pandas库可以从多种类型的数据文件中读取数据,并且可以将数据写入这些文件中。本节以Excel工作簿和CSV文件为例进行讲解。
(1)文件读取
- 用read_excel()函数可以读取Excel工作簿中的数据,代码如下:
import pandas as pd
data = pd.read_excel('data.xlsx') #data为DataFrame结构
- 这里读取的Excel工作簿扩展名为“.xlsx”,如果是2003版或更早版本的Excel工作簿,其扩展名为“.xls”。这里使用的文件路径为相对路径,也可以使用绝对路径,相关知识点点见3.3.2节的“补充知识点1”。通过打印输出data便可查看读取的表格内容。如果只想查看查看表格的前5行数据,可以使用如下代码:
data.head() #这里协程head(10)则可查看前10行数据,一次类推
- read_excel()函数还可以设定参数,演示代码如下:
data = pd.read_excel('data.xlsx',sheet_name=0)
- 这里的参数sheet_name用于指定要读取的工作表,其值可以工作表名称,也可以是数字(默认为0,即第1个工作表)。此外,还可用参数index_col来指定某一列作为行索引。
- CSV文件也是一种常见的数据格式文件格式,它在本质上是一个文本文件,可以用Excel或文本编辑器(如“记事本”)打开。CSV文件中存储的是用逗号分隔的数据,但不包含格式、公式、宏等,因而占用的存储空间通常较小。用read_csv()函数可以读取CSV文件中的数据,代码如下:
data = pd.read_csv('data.csv')
- read_csv()函数也可以指定参数,代码如下:
data = pd.read_csv('data.csv',delimiter=',',encoding='utf-8')
- 其中参数delimiter用于指定数据的分隔符,默认为逗号;参数encoding用于设置编码格式,如果出现中文乱码,则需要设置为’utf-8’或’gbk’。此外,还可以通过参数index_col设置索引列。
(2)文件写入
- 用to_excel()函数可以将DataFrame中的数据写入Excel工作簿,代码如下:
data = pd.DataFrame([[1,2],[3,4],[5,6]],columns=['A列','B列'])
data.to_excel('data_new.xlsx') #这里使用相对路径,也可使用绝对路径
- 运行之后,将在代码文件所在的文件夹下生成一个Excel工作簿“data_new.xlsx”,其内容如下图所示。
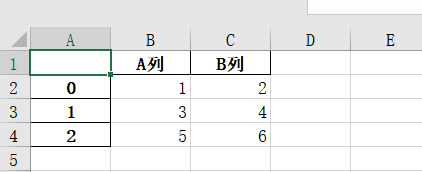
- 从上图可以看出,工作表的第1列还保留了行索引信息,如果想在写入数据时不保留行索引信息,可以将to_excel()函数的参数index设置为False(设置为True则表示保留行索引信息),代码如下:
data.to_excel('data_new.xlsx',index=False)
- to_excel()函数还有一些常用的参数:sheet_name用于指定工作表名称;columns用于指定要写入的列。
- 用to_csv()函数可以将DataFrame中的数据写入CSV文件,代码如下:
data.to_csv('data_new.csv')
- 与to_excel()函数类似,to_csv()函数也可以设置index、columns、encoding等参数。如果导出的CSV文件出现了中文乱码现象,可尝试encoding设置为’utf-8’,如果还是无效,则需要设置成’utf_8_sig’,代码如下:
data.to_csv('演示.csv',index=False,encoding='utf_8_sig')
3.DataFrame 中数据的常用操作
- 创建了DataFrame之后,就可以根据需要操作其中的数据。首先创建一个3行3列的DataFrame用于演示,行索引设定为r1、r2、r3,列索引设定为c1、c2、c3,代码如下:
import pandas as pd
data = pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],index=['r1','r2','r3'],columns=['c1','c2','c3'])
data
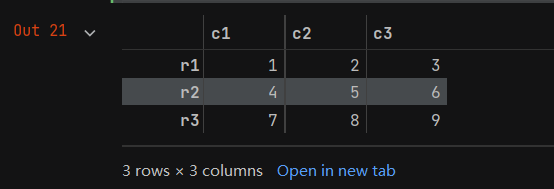
- 下面讲解数据的选取、筛选、整体情况查看等常用操作。
(1)按列选取数据
- 先从简单的选取单列数据入手,代码如下:
a = data['c1']
a
- a的打印输出结果如下:

- 可以看到返回的结果不包含列索引信息,这是因为通过data[‘c1’]选取单列时返回的是一个一维的Series格式的数据。如果要返回二维的DataFrame格式的数据,可以使用如下代码:
b = data[['c1']]
b
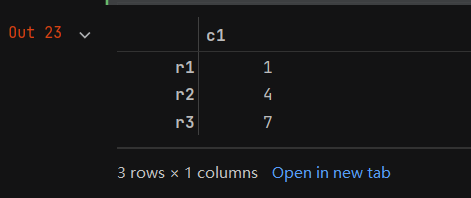
- 如果要选取多列,则需要在中括号[]中以列表的形式给出列索引值。例如,选取c1和c3列的代码如下:
c = data[['c1','c3']] #不能写成data['c1','c3']
c
- c的打印输出结果如下:

(2)按行选取数据
- 可以根据行序号选取数据,代码如下:
#%%
# 选取第2行和第3行的数据,注意序号从0开始,左闭右开
a = data[1:3]
a
- a的打印结果如下:
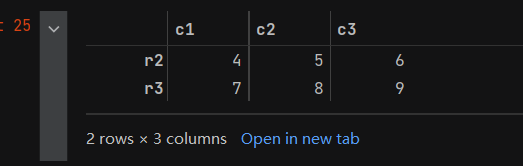
- 而pandas库的官方文档推荐使用iloc方法来根据行序号选取数据,这样更直观,而且不像data[1:3]可能会引起混淆报错。代码如下:
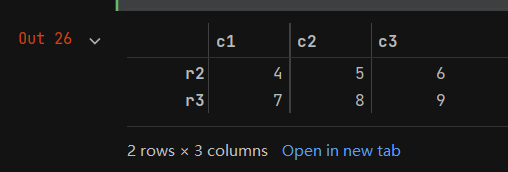
b = data.iloc[1:3]
b
- 而且如果要选取单行,就必须使用iloc方法。例如,选取倒数第1行,代码如下:
c = data.iloc[-1]
c
- 如果使用data[-1],那么pandas库可能会认为-1是列索引,导致混淆报错。
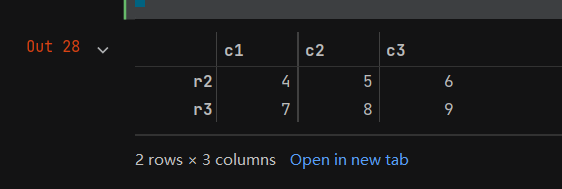
- 除了根据行序号选取数据外,还可以根据loc方法根据行索引选取数据,代码如下:
d = data.loc[['r2','r3']]
d
- 如果行数很多,可以用head()函数选取前5行数据,代码如下:
e = data.head()
- 这里因为data中只有3行数据,所以data.head()会选取所有数据。如果只想选取前两行数据,可以写成data.head(2)。
(3)按区块选取数据
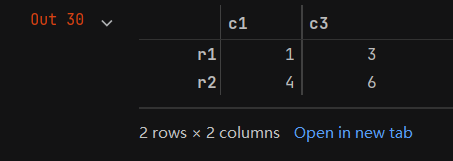
- 按区块选取是指选取某几行的某几列数据。例如,选取c1和c3列的前两列的前两行数据,代码如下:
a = data[['c1','c3']][0:2] #也可以写成data[0:2][['c1','c3']]
a
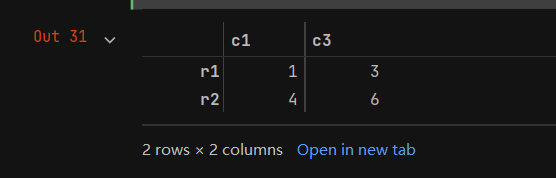
- 在实战中选取区块链数据时,通常先用iloc方法选取行,再选取列,代码如下:
b = data.iloc[0:2][['c1','c3']]
b
- 两种方法的选取效果是一样的,但第二种方法逻辑更清晰,不容易出现混淆报错,它也是pandas库的官方文档推荐的方法。
- 如果要选取单个值,该方法就更有优势。例如,选取c3列第1行数据,就不能写成
data['c3'][0]或data[0]['c3'],而要先用iloc[0]选取第1行,在选取c3列,代码如下:
c = data.iloc[0]['c3']
c
- 也可以使用iloc和loc方法同时选取行和列,代码如下:
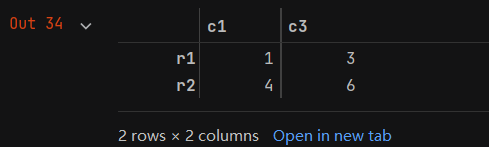
d = data.loc[['r1','r2'],['c1','c3']]
d
e = data.iloc[0:2,[0,2]]
e
loc方法使用字符串作为索引,iloc方法使用数字作为索引。这里介绍一个简单的记忆方法:loc是location(定位、位置)的缩写,所以是用字符串作为索引;iloc中多了一个字母i,而i有经常代表数字,所以用数字作为索引。
- d和e的打印结果如下:
(4)数据筛选
- 通过在中括号里设置条件可以对行数进行筛选。例如,选取c1列中数字大于1的行,代码如下:
a = data[data['c1'] > 1]
a

- 如果有多个筛选条件,可用“&”(表示“且”)或“|”(表示“或”)连接。例如,筛选c1列中数字大于1且c2列中数字等于5的行,代码如下(在筛选条件两侧要加上小括号):
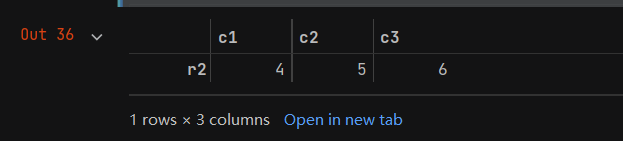
b = data[(data['c1'] > 1) & (data['c2'] == 5)] # 用 “==” 而不是"="来判断是否相等
b
- b的打印输出结果如下:
(5)数据整体情况查看
- 通过DataFrame的shape属性可以获取表格的行数和列数,从而快速了解表格的数据量大小,代码如下:
data.shape
- 运行结果如下,其中第1个数字为行数,第2个数字为列数。因此,通过data.shape[0]和data.shape[1]可分别获取行数和列数。此外,通过len(data)也可以获取行数。
(3, 3)
(6)数据运算
- 通过数据运算可利用已有的列创建新的一列,代码如下:
data['c4'] = data['c3'] - data['c1']
data.head()

(7)数据排序
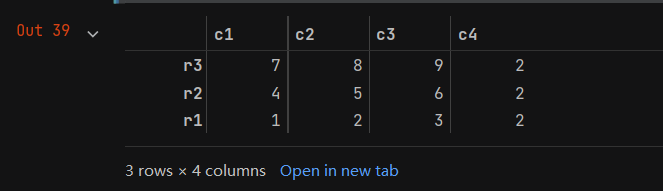
- 用sort_values()函数可以将数据按列排序。例如,按c2列进行降序排序的代码如下:
a = data.sort_values(by='c2',ascending=False)
a
- 参数by用于指定哪一列来排序;参数ascending默认为True,表示升序排序,若设置为False则表示降序排序。a的打印结果如下。
(8)数据删除
- 用drop()函数可以删除指定的列和行,其常用语法格式如下:
DataFrame.drop(index=None,columns=None,inplace=False) - 这里列出的几个常用参数的含义:index用于指定要删除的行;columns用于指定要删除的列;inplace默认为False,表示该删除操作不改变原DataFrame,而是返回一个执行删除操作后的新DataFrame,如果为True,则会直接在原DataFrame中执行删除操作。
- 删除单列,如c1列,代码如下:
a = data.drop(columns='c1')
- 删除多列,如c1和c3列,可以通过列表的方式声明,代码如下:
b = data.drop(columns=['c1','c3'])
b
注意:删除行时要输入行索引而不是行序号,除非行索引本来就是数字,才可以输入对应的数字。
- 用drop_duplicates()函数删除内容重复的行,代码如下:
d = data.drop_duplicates() #默认保留首次出现的行,删除之后的重复的行
d
- dropna()函数可以删除空行(含有空值的行),代码如下:
e = data.dropna()
- 这种删除方法是只要含有空值的行都会被删除。如果只想删除全为空值的行,可以写成:
data.dropna(how='all')
- 还可以用参数thresh来限定非空值的个数,代码如下:
data.dropna(thresh=2) #表示行内至少要有两个非空值,否则删除该行
- 上面的代码都是删除数据后又赋给新的变量,不会改变data的内容。如果想改变data的内容,可以删除数据后重新赋值给data,或者将参数inplace设置为True,代码如下:
#%%
data = data.dropna()
data.drop(inplace=True)
4. DataFrame 拼接
- pandas 库提供的数据合并与重塑功能极大方便了两个DataFrame的拼接,主要涉及merge()、concat()、append()等函数。这里主要介绍append()函数,它可以方便地将结构相同的DataFrame拼接起来,在爬虫任务中经常会用到。
- 先创建两个DataFrame用于演示,代码如下:
import pandas as pd
df1 = pd.DataFrame({'公司':['万科','阿里'],'分数':[90,95]})
df2 = pd.DataFrame({'公司':['百度','京东'],'分数':[80,90]})
- 现在需要对df1和df2进行上下合并,核心代码如下:
df3 = df1.append(df2)
df3

- 可以看到行索引还是原DataFrame的行索引,如果想忽略原DataFrame的行索引,可以将参数ignore_index设置为True,代码如下:
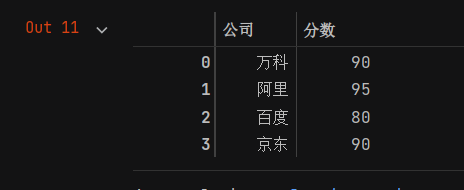
df3 = df1.append(df2,ignore_index=True)
df3
- 也可以不设置ignore_index,在用to_excel()函数导出Excel工作簿设置index=False来忽略行索引。爬虫实战中,通常是创建一个空的DataFrame,然后用append()函数一次添加每个表格的数据(参见6.3.2节的具体应用)。
- 实际上,排序、删除、拼接等操作都不会改变元DataFrame的内容,笔者推荐重新赋值的方式来获取修改后的DataFrame。
这篇关于第6章 数据结构化与数据存储(6.1数据结构化神器——pandas库,读取网页中的表格数据)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






