本文主要是介绍GEE数据集——美国大陆网格气候数据集PRISM 日数据集和月数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
PRISM 日数据集和月数据集是由俄勒冈州立大学 PRISM 气候小组制作的美国大陆网格气候数据集。
网格是利用 PRISM(独立斜坡模型参数-海拔回归)开发的。PRISM 插值程序模拟了天气和气候随海拔高度的变化,并考虑了海岸效应、温度反常和可能造成雨影的地形障碍。站点数据来自全国各地的许多网络。更多信息,请参阅 PRISM 空间气候数据集说明。
PRISM气候小组开展了一系列项目,其中一些项目支持空间气候数据集的开发。由此产生的一系列数据集反映了项目目标的范围,需要不同的站点网络、建模技术和时空分辨率。 在可能的情况下,我们向公众提供这些数据集,有的是免费的,有的是收费的,这取决于提供数据集的规模和难度以及活动的资金情况。为了让用户做出明智的决定,选择最适合他们需要的数据集,本文件提供了目前可用的PRISM空间气候数据集的信息。我们还提供了汇总表供快速参考。我们首先概述了 PRISM 数据集,然后依次讨论每个数据集。
注释
警告:由于台站设备和位置变化、开放和关闭、观测时间不同以及使用相对较短的网络等非气候因素的影响,该数据集不应用于计算长达一个世纪的气候趋势。详情请参见数据集文档。
观测网络进行质量控制和发布站点数据需要时间。因此,PRISM 数据集要经过多次重新建模,直到六个月后才被视为永久数据集。可提供发布时间表。
如需使用该数据集的 30 弧秒(约 800 米)版本,请通过 prism-questions@nacse.org 与数据集提供者联系。
数据简介
Dataset Availability
1895-01-01T00:00:00Z–2024-02-01T00:00:00Z
Dataset Provider
PRISM / OREGONSTATE
Earth Engine Snippet
ee.ImageCollection("OREGONSTATE/PRISM/AN81m")
波段属性
Resolution
4638.3 meters
Bands
| Name | Units | Min | Max | Description |
|---|---|---|---|---|
ppt | mm | 0* | 2639.82* | Monthly total precipitation (including rain and melted snow) |
tmean | °C | -30.8* | 41.49* | Monthly average of daily mean temperature (calculated as (tmin+tmax)/2) |
tmin | °C | -35.11* | 34.72* | Monthly minimum temperature |
tmax | °C | -29.8* | 49.74* | Monthly average of daily maximum temperature |
tdmean | °C | -30.7* | 26.76* | Monthly average of daily mean dew point temperature |
vpdmin | hPa | 0* | 44.79* | Monthly average of daily minimum vapor pressure deficit |
vpdmax | hPa | 0.009* | 110.06* | Monthly average of daily maximum vapor pressure deficit |
* estimated min or max value
影像属性
| Name | Type | Description |
|---|---|---|
| PRISM_CODE_VERSION | STRING_LIST | List of code versions per-band, e.g: the first element is for the first band "ppt", the second element is for the second band "tmean" |
| PRISM_DATASET_CREATE_DATE | STRING_LIST | List of original creation dates per-band |
| PRISM_DATASET_FILENAME | STRING_LIST | List of original filenames for each band |
| PRISM_DATASET_TYPE | STRING_LIST | List of dataset types per-band |
| PRISM_DATASET_VERSION | STRING_LIST | List of dataset versions per-band e.g: D1 or D2 for daily products; M1, M2 or M3 for monthly products. |
| status | STRING | Data generated within 30 days of observation have the status "early". Data generated within 1-6 months of observation may have the status "provisional" and data older than 6 months are marked as "permanent". |
代码
var dataset = ee.ImageCollection('OREGONSTATE/PRISM/AN81m').filter(ee.Filter.date('2018-07-01', '2018-07-31'));
var precipitation = dataset.select('ppt');
var precipitationVis = {min: 0.0,max: 300.0,palette: ['red', 'yellow', 'green', 'cyan', 'purple'],
};
Map.setCenter(-100.55, 40.71, 4);
Map.addLayer(precipitation, precipitationVis, 'Precipitation');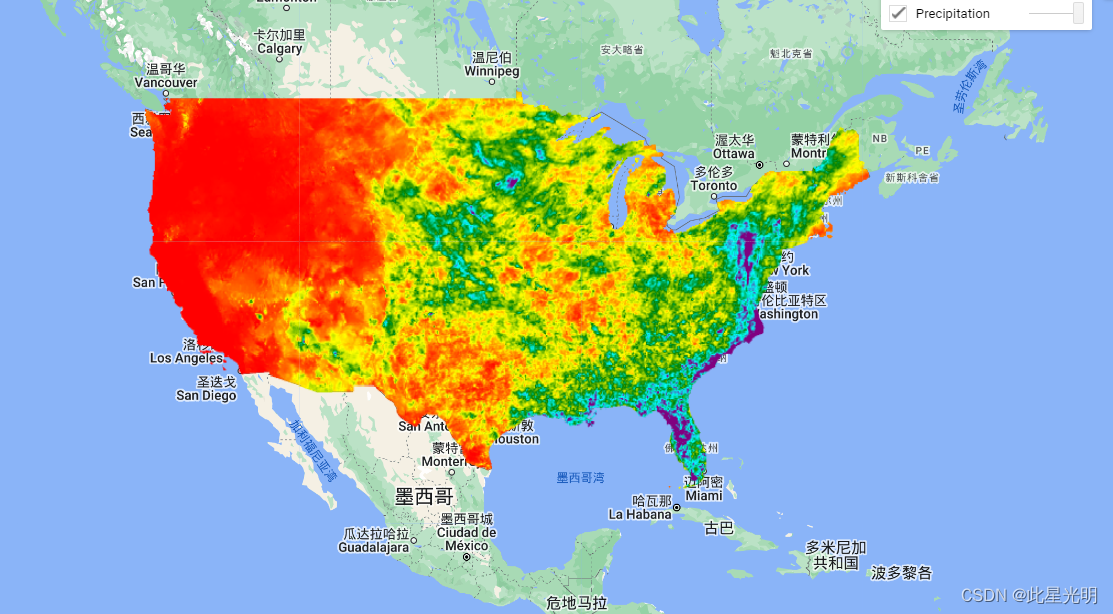
使用说明
这些 PRISM 数据集的使用或分发不受限制。PRISM 气候组织要求用户适当注明出处,并在适用情况下指明 PRISM 为数据来源。
数据引用
-
Daly, C., Halbleib, M., Smith, J.I., Gibson, W.P., Doggett, M.K., Taylor, G.H., Curtis, J., and Pasteris, P.A. 2008. Physiographically-sensitive mapping of temperature and precipitation across the conterminous United States. International Journal of Climatology, 28: 2031-2064
-
[Daly, C., J.I. Smith, and K.V. Olson. 2015. Mapping atmospheric moisture climatologies across the conterminous United States. PloS ONE 10(10):e0141140. doi:10.1371/journal.pone.0141140
-
网址推荐
-
国内专业的气象监测网站
- www.htdrought.com
- 慧天干旱监测与预警平台:基于风云卫星和机器学习方法的大面积干旱监测、气象预警平台_慧天卓特公司-CSDN博客
-
0代码在线构建地图应用
机器学习
这篇关于GEE数据集——美国大陆网格气候数据集PRISM 日数据集和月数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






