本文主要是介绍Elastic 网络爬虫:为你的网站添加搜索功能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:来自 Elastic Lionel Palacin
为了演示如何使用 Elastic 网络爬虫,我们将以一个具体的网站为例,讲解如何在该网站上添加搜索功能。我们将探讨发现网站的方法,并利用 Elastic 网络爬虫提供的功能,以最佳方式准备待搜索的数据。
在本文中,我们将使用 Elastic Cloud 8.13 版本。
有关网络爬虫的更多内容,请详细阅读:
- Enterprise:Web Crawler 基础 (一)(二)
-
ChatGPT 和 Elasticsearch:OpenAI 遇见私有数据(二)
Elastic 网络爬虫
是一个开箱即用的工具,使用户能够抓取网站内容并将其导入 Elasticsearch。
Elastic 网络爬虫从访问入口点 URL 开始每次爬取。从这里开始,爬虫获取网页内容并提取之。HTML 文档被转换成搜索文档并进行索引。
然后,它会跟随该页面指向的任何链接,遵守用户定义的规则集。使用相同的方法访问新的 URL,直到爬虫索引了所有可访问的网页。如果一个网页没有链接指向,爬虫就无法找到它。
网站发现
首次爬取
我们将以 “Books to Scrape” 网站作为爬取的简单网站示例,这是一个提供书籍信息选择的网站,专门为测试网络爬虫而设计。
如果你使用的是 Elastic Cloud,设置非常简单,因为 Elastic 网络爬虫是开箱即用的。如果你管理自己的 Elastic 部署,请确保检查此页面以了解需求。
让我们从 Kibana 首页开始。从那里,导航到搜索解决方案,然后创建一个新的网络爬虫。
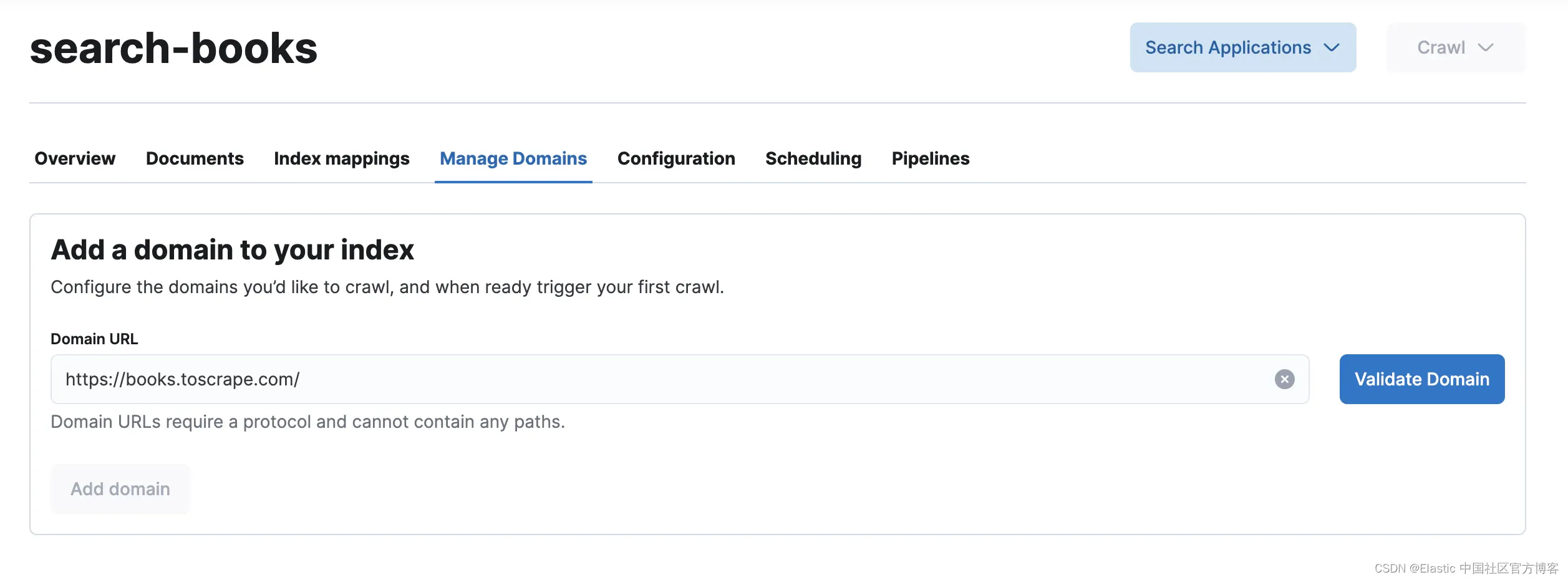
为索引提供一个名称,在我们的例子中是 search-books,并在下一个屏幕中输入主网站 URL:https://books.toscrape.com/。然后验证域名,并等待执行一些检查,以确保该域名可以被爬取。
在这一点上,让我们通过点击 “Crawl => Crawl all domains” 来使用默认配置爬取网站。这样做,我们将看到正在被爬取的链接以及如何为每个网页索引文档。
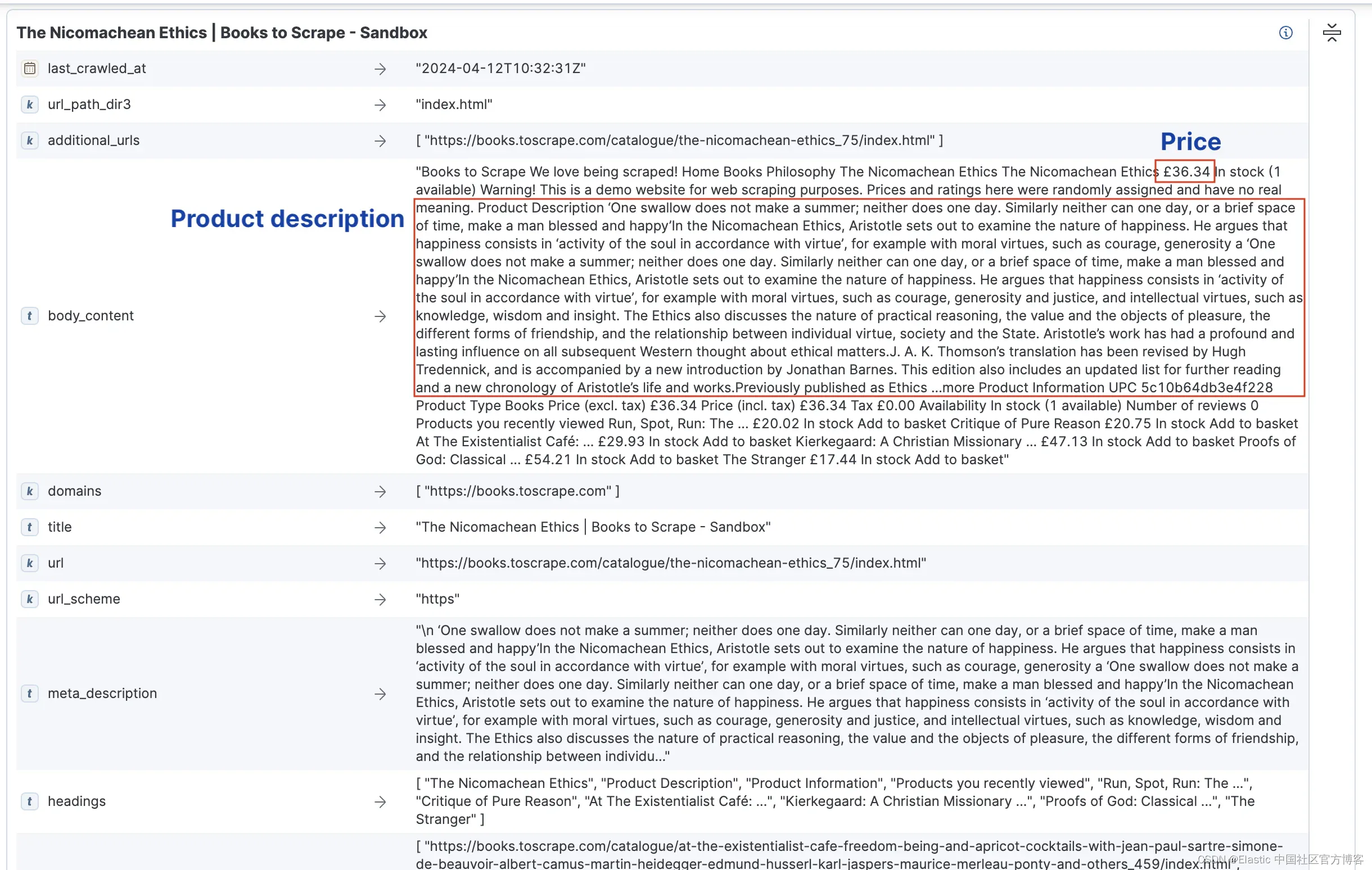
查看文档列表时,我们会看到一些类别页面也被爬取了,但我们对这些页面不感兴趣,因为我们只想爬取书籍详情页面。

另外一个我们在展开书籍文档时注意到的问题是,书籍的价格或摘要在 body_content 字段中混合在一起。这使得这些重要信息在搜索查询中不易使用。
定义爬取规则
从我们的第一次爬取中,我们注意到 category 页面也被爬取了,而我们对它们不感兴趣,所以让我们将它们排除在爬取之外。
在爬取规则下,添加一个新规则来禁止爬取以路径模式 /catalogue/category/ 开头 (Begins with) 的页面。
现在我们可以在新规则生效的情况下重新进行一次爬取。
注意:作为探索过程的一部分,每次更改网络爬虫配置时,我建议删除内容。在最后一章 “准备生产部署” 中,我们将看到如何在不手动删除数据的情况下重新运行网络爬虫。
# Delete all documents
POST search-books/_delete_by_query
{"query": {"match_all": {}}
}丰富数据
默认情况下,Elastic 网络爬虫使用默认模式从网页中提取所有信息。例如,HTML 标签 <title> 被提取到字段 title 中,而 <body> 标签被提取到字段 body_content 中。这是一个很好的基础,但大多数情况下,我们希望自定义数据的提取方式,并且丰富数据以在搜索应用程序中使用。
从自定义字段中提取数据
查看文档被索引的方式时,我们注意到我们想要将书籍摘要和价格分别提取到它们自己的字段中。
在探索新网站时,通常会自定义爬虫从网页中提取内容的方式,为此,提取规则是一个很好的工具。
使用浏览器检查工具,我们可以看到哪个 HTML 标签包含价格文本,这里是一个带有 class=price_color 的 HTML 标签 <p>。

提取规则使用 CSS 选择器或 XPath 来识别网页中的特定元素。我们可以使用浏览器控制台来测试它们。
要尝试 XPath,我们可以使用函数 $x。例如,要返回书籍摘要节点,我们可以在浏览器控制台中运行 $x("//article[@class='product_page']/p")[0]。

要尝试 CSS 选择器,我们可以使用 document.querySelectorAll。例如,要使用 CSS 选择器选择价格,我们可以在浏览器控制台中运行:document.querySelectorAll("div.product_main p.price_color")[0]。

根据我们在浏览器控制台测试的内容,让我们创建一个提取规则来添加两个新字段:summary 和 price。
提取规则:
- 名称:书页规则
- 适用于所有 URL
- 第一个字段:
- Field name:summary
- source:从 HTML 元素中提取内容
- CSS 选择器://article[@class='product_page']/p
- Content:使用从提取值中提取的内容
- 将提取的内容存储为字符串
- 第二个字段:
- 字段名称:price
- source:从 HTML 元素中提取内容
- CSS 选择器:div.product_main p.price_color
- Content:使用从提取值中提取的内容
- 将提取的内容存储为字符串

数据摄取管道用于转换数据
通常,从网页提取的数据格式并不完全适合用于搜索引擎。在我们的例子中,我们已经将书籍价格单独提取到一个 price 字段中,但如果仔细观察,会发现它被索引为字符串:“£18.03”,这并不理想,因为它不便于执行比较搜索(例如,获取所有价格低于 20 英镑的书籍)或聚合操作(例如,计算科幻书的平均价格)。
为了在数据摄取时进行一些小的转换,我们可以使用 Elasticsearch 中的摄取管道。有许多处理器可用于执行不同的任务,在我们的案例中,我们将使用脚本处理器执行一个自定义函数,该函数将为每个被索引的文档执行,去除价格中的第一个字符,仅保留数字部分。
要管理摄取管道,请转到 Pipelines 标签页,点击 “Copy and Customize”,然后点击 “编辑管道” 按钮开始编辑摄取管道。

在那里添加一个脚本处理器,使用以下代码:
ctx['price_float'] = ctx['price'].substring(1)保存所有更改,然后返回到网络爬虫索引配置页面。
我们添加的脚本将在摄取时创建一个名为 price_float 的新字段。我们需要编辑索引映射以提供正确的字段类型,在我们的情况下,我们希望将其索引为浮点型。
打开控制台并执行以下代码以更新索引映射:
# Add a new field with a type float
PUT search-books/_mapping
{"properties": {"price_float": {"type": "float"}}
}现在我们可以删除索引中的所有文档,然后再次运行爬取。所有文档中都会存在一个名为 price_float 的新字段,其类型为浮点型。
启用语义搜索的机器学习推理管道
我们可以使用的另一种管道是推理管道,它允许我们在被索引的数据上运行机器学习模型。
在我们的案例中,我们希望利用 Elastic 的专有机器学习模型 ELSER,该模型能够对任何英语文本启用语义搜索。
返回到 Pipelines 标签页,向下滚动到 Machine Learning Inference Pipelines 部分。如果还未部署和启动 ELSER 模型,此处可以进行部署和启动。

然后,通过单击 “Add Inference Pipeline” 按钮添加一个新的推理管道。在第一个屏幕上选择 ELSER 模型,然后转到下一个屏幕,在那里选择推理管道的输入和输出字段。在我们的案例中,我们想要在图书 summary 上启用语义搜索。我们选择该字段并将其添加到列表中。
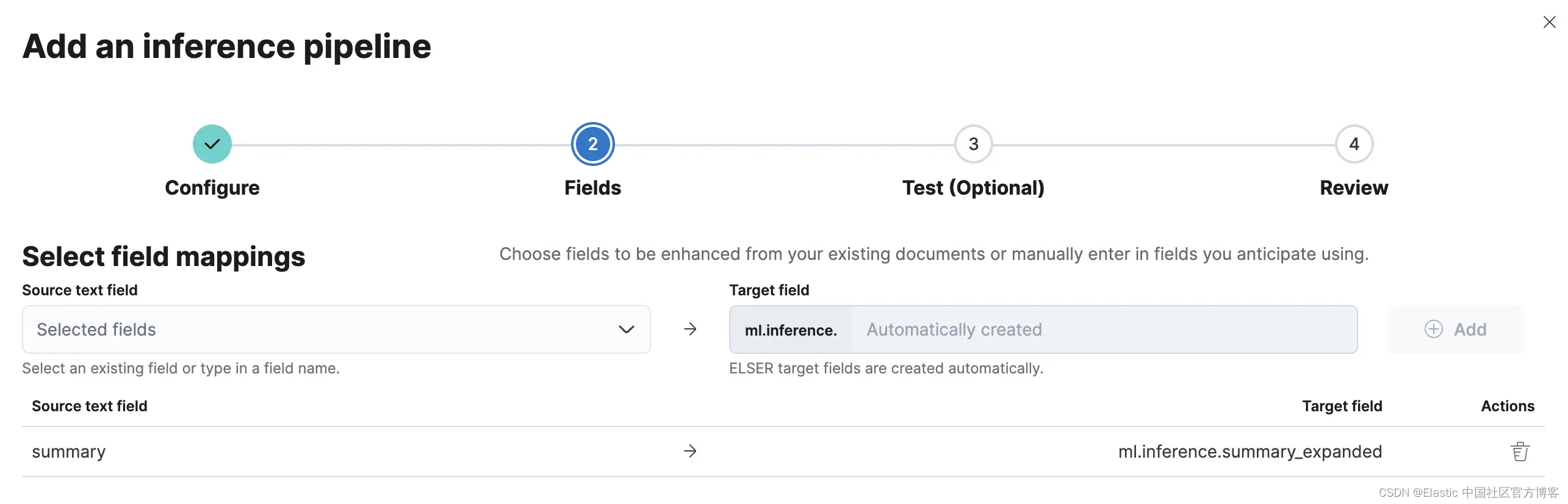
完成配置后,我们可以删除所有文档并再次运行网络爬虫。
测试查询
当我们使用提取规则和摄入管道配置网络爬虫后,我们的文档很容易进行搜索。
让我们看一个查询示例,该查询对书籍摘要执行语义搜索,并包含基于书籍价格的过滤器。
# Find books over £50 that talks about "Wars and family succession struggle on dry planets"
POST search-books/_search
{"_source": ["title", "summary", "price", "url"],"query": {"bool": {"should": [{"text_expansion": {"ml.inference.summary_expanded.predicted_value": {"model_id": ".elser_model_2_linux-x86_64","model_text": "Wars and family succession struggle on dry planets"}}}],"filter": [{"range": {"price_float": {"gte": 50}}}]}}
}准备生产部署
在本章中,我们将讨论在将网络爬虫投入生产时一些重要的网络爬虫特性。
定时任务
由于网站经常更新,保持 Elasticsearch 中的数据与网站同步更新可能很重要。为此,我们可以利用 Elastic 网络爬虫的调度功能,定期爬取网站。
Elastic 网络爬虫会自动检测自上次爬取以来网页是否已更新,并将在 Elasticsearch 中更新相应的文档。如果自上次爬取以来某个网页已被删除,则该文档也将从 Elasticsearch 中删除。
受保护的网站
另一个有用的功能是能够爬取非公开可用或位于认证后的网站。
此文档详细解释了如何爬取位于私有网络中的网站。
如果访问特定网页需要认证,我们可以在域配置屏幕下的认证部分添加凭据或特定头部。
总结
在这篇博客文章中,我们看到了如何从头到尾发现一个新网站进行爬取,如何利用 Elastic 网络爬虫的功能准备数据以用于搜索应用,以及最后如何准备将其部署到生产环境。
如果你有兴趣了解更多关于 Elastic 摄入能力的信息,请查看其他开箱即用的连接器。如果你想在 GenAI 应用程序中使用摄入数据,请查看我们的教程。
准备在你的应用中构建 RAG 吗?想尝试不同的 LLMs 与向量数据库吗? 查看我们在 Github 上的 LangChain、Cohere 等示例笔记本,并加入即将开始的 Elasticsearch工程师培训!
原文: Elasticsearch open inference API adds support for OpenAI chat completions — Elastic Search Labs
这篇关于Elastic 网络爬虫:为你的网站添加搜索功能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!