本文主要是介绍政安晨:【深度学习神经网络基础】(十二)—— 深度学习概要,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
概述
深度学习的概况
深度学习的组成部分
部分标记的数据
修正线性单元
卷积神经网络
神经元Dropout
GPU训练
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 政安晨的机器学习笔记
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
概述
深度学习是人工智能领域的一个重要分支,它主要通过神经网络模型来实现复杂的学习任务。
在深度学习中,神经网络通常由多个层次组成,每一层都包含多个神经元,这些神经元通过改变权重和偏差值来学习输入数据的特征。
深度学习的一个重要特点是它能够自动地从大量的数据中学习和提取特征,无需手工设计特征提取器。它利用了反向传播算法来计算误差梯度,进而通过梯度下降来优化神经网络的权重和偏差值,从而使得网络能够更好地逼近目标函数。
深度学习在许多领域中取得了突破性的进展,如图像识别、语音识别、自然语言处理等。
它的核心是通过构建多层的神经网络,可以实现更复杂的模型和更准确的预测。
然而,深度学习也存在一些挑战,例如需要大量的训练数据、计算资源较大、模型可解释性较差等。因此,研究者们一直在努力尝试改进深度学习的方法和算法,以解决这些问题并推动其应用的发展。
深度学习的概况
深度学习是神经网络编程中相对较新的进展,它代表了一种训练深度神经网络的方法。
本质上,任何具有两层以上的神经网络都是深度神经网络。
自从Pitts(1943)引入多层感知机(multilayer perceptron)以来,我们就已经具备创建深度神经网络的能力。
但是,直到Hinton(1984)成为第一个成功训练这些复杂神经网络的研究者之后,我们才能够有效地训练神经网络。
本文要点:
● 卷积神经网络和Dropout;
● 深度学习工具;
● 对比散度;
● 吉布斯采样。
深度学习的组成部分
深度学习由许多不同的技术组成,本文概述了这些技术。后文将包含有关这些技术的更多信息。
深度学习通常包括以下特征:
● 部分标记的数据;
● 修正线性单元;
● 卷积神经网络;
● 神经元Dropout。
以下概述这些技术。
部分标记的数据
大多数学习算法是有监督的或无监督的。
有监督的训练数据集为每个数据项提供了预期的结果;
无监督的训练数据集不提供预期的结果。
预期的结果称为标记。学习的问题在于大多数数据集是带标记的和未带标记的数据项的混合。
要理解标记和未标记数据之间的区别,请考虑以下真实世界的例子。
当你还是小孩子的时候,在成长过程中可能会看到许多车辆。
在生命的早期,你不知道自己在看轿车、卡车,还是货车,只知道看到的是某种车辆。
你可以将这种接触看成车辆学习过程中无监督的部分。
那时,你学习了这些车辆之间的共同特征。
在学习过程的后期,你将获得标记。
当你遇到不同的车辆时,一位成年人告诉你,你看的是汽车、卡车或货车。无监督的训练为你奠定了基础,而你会以这些知识为基础获得标记。
如你所见,有监督和无监督的学习在现实生活中非常普遍。
深度学习用它自己的方式,结合无监督和有监督的学习数据,很好地完成了工作。
一些深度学习架构使用不带结果的整个训练集,来处理部分标记的数据,并初始化权重。
你可以在没有标记的情况下,独立训练各个层。
因为你可以并行训练这些层,所以这个过程是可伸缩的。
一旦无监督阶段初始化了这些权重,监督阶段就可以对其进行调整。
修正线性单元
修正线性单元(ReLU)已成为深度神经网络隐藏层的标准激活函数,而受限玻尔兹曼机是深度置信神经网络的标准。
除了用于隐藏层的ReLU激活函数外,深度神经网络还将对输出层使用线性或Softmax激活函数,具体取决于神经网络是支持回归,还是分类。
我们在以前关于神经网络基础的文章中介绍了ReLU,并在“反向传播训练”中扩展了相关信息。
卷积神经网络
卷积是一项经常与深度学习结合的重要技术。Hinton(2014)引入了卷积,以使图像识别神经网络的工作方式类似于生物系统,并获得了更准确的结果。卷积的一种方法是稀疏连接,即不会产生所有可能的权重连接。
下图展示了稀疏连接:
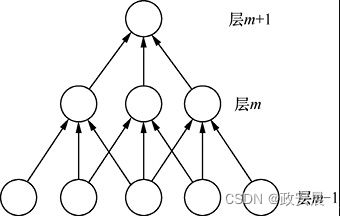
常规前馈神经网络通常会在两层之间创建所有可能的权重连接。在深度学习术语中,我们将这些层称为“稠密层”(dense layer)。
卷积神经网络不表示所有可能的权重,但其会共享权重,如下图所示:
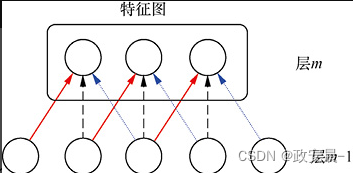
如上图所示,神经元只是共享3个独立的权重。红线(实线)、黑线(虚线)和蓝线(虚线)表示各个权重。权重共享使程序可以存储复杂的结构,同时保持内存使用和计算的效率。
神经元Dropout
Dropout是一种正则化算法,对深度学习有很多好处。和大多数正则化算法一样,Dropout可以防止过拟合。你也可以和卷积一样,以逐层的方式将Dropout应用于神经网络。
你必须将一个层指定为Dropout层。实际上,在神经网络中,你可以将这些Dropout层与常规层和卷积层混合使用。切勿将Dropout层和卷积层混合在单个层中。
Hinton(2012)引入了Dropout,将其作为一种简单有效的正则化算法,以减少过拟合。Dropout通过移除Dropout层中的特定神经元来发挥作用。丢弃这些神经元的行为可防止其他神经元过度依赖于被丢弃的神经元。程序将删除这些选定的神经元及其所有连接。
下图说明了这个过程:
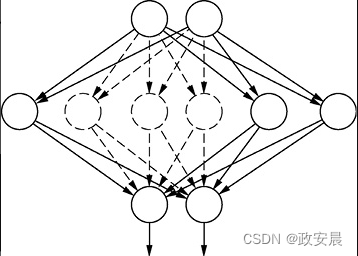
上图所示的神经网络从上至下包含一个输入层、一个Dropout层和一个输出层。Dropout层已删除了几个神经元。虚线圆圈表示Dropout算法删除的神经元,虚线连接线表示Dropout算法删除神经元时删除的权重。
Dropout和其他形式的正则化都是神经网络领域广泛讨论的主题。本质上,单个神经网络通常使用Dropout以及其他正则化算法。
GPU训练
Hinton(1987)提出了一种非常新颖的算法,来有效地训练深度信念神经网络。
在后文,我们将研究该算法和深度信念神经网络。如前所述,深度神经网络几乎与神经网络存在的时间一样长。但是,在Hinton的算法被提出之前,没有有效的算法来训练深度神经网络。反向传播算法非常慢,梯度消失问题阻碍了训练。
GPU,即计算机中负责图形显示的部分,是研究人员解决前馈神经网络训练问题的一种方法。
由于现代视频、游戏使用了3D图形,因此我们大多数人都熟悉GPU。渲染这些图形、图像在数学上运算量大,而且为了执行这些操作,早期的计算机依靠CPU。但是,这种方法效率不高。现代视频、游戏中的图形系统处理需要专用电路,这种电路集成到了GPU或视频卡上。
本质上,现代GPU是在计算机中运行的计算机。
研究人员发现,根据GPU的处理能力可以将其用于密集的数学任务,如神经网络训练。除了计算机图形学之外,我们将用于一般计算任务的GPU称为通用GPU(General-Purpose use of GPU,GPGPU)。当应用于深度学习时,GPU的表现异常出色。将它与ReLU激活函数、正则化和常规反向传播算法相结合,可以产生惊人的结果。
但是,GPGPU可能难以使用,因为为GPU编写的程序必须使用名为C99的编程语言。
该语言与常规C语言非常相似,但在许多方面,GPU所需的C99比常规C语言困难得多。此外,GPU仅擅长特定的任务,即使是对GPU有利的任务,也因为优化C99代码而变得具有挑战性。GPU必须平衡几类内存、寄存器,以及数百个处理器内核的同步。此外,GPU处理有两种相互竞争的标准:CUDA和OpenCL。两种标准为程序员学习制造了更多的困难。
幸运的是,你无须学习GPU编程,也可以利用它的处理能力。除非你愿意花费大量的精力,来学习一个复杂且不断发展的领域的细枝末节,否则我们不建议你学习GPU编程,因为它与CPU编程完全不同。产生有效的、基于CPU程序的好技术,通常会产生极其低效的GPU程序,反之亦然。如果你想使用GPU,就应该使用支持它的、已有的软件包。如果你的需求不适合深度学习软件包,则可以考虑使用线性代数软件包,如CUBLAS,其中包含许多高度优化的算法,以及针对机器学习通常需要的线性代数。
高度优化的深度学习框架和快速GPU的处理能力可能是惊人的。GPU可以凭借强大的处理能力获得出色的结果。2010年,瑞士AI实验室IDSIA证明,尽管有梯度消失问题,但GPU的出色处理能力,使得反向传播对深度前馈神经网络来说是可行的。在著名的MNIST手写数字识别问题上,该方法胜过了所有其他机器学习技术。
这篇关于政安晨:【深度学习神经网络基础】(十二)—— 深度学习概要的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



