本文主要是介绍GhostNetV3:探索紧凑型模型的训练策略学习笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码地址(coming soon):Efficient-AI-Backbones/ghostnetv3_pytorch at master · huawei-noah/Efficient-AI-Backbones · GitHub
论文地址:2404.11202v1.pdf (arxiv.org)
紧凑型神经网络是专门为边缘设备上的应用而设计的,具有更快的推理速度和适度的性能。然而,目前紧凑型模型的训练策略是从传统模型中借鉴的,这忽略了它们在模型容量上的差异,从而可能会阻碍紧凑模型的性能。在本文中,通过系统地研究不同训练成分的影响,作者为紧凑模型引入了一种强训练策略。重参数化和知识蒸馏的适当设计对于训练高性能紧凑型模型至关重要,而用于训练传统模型的一些常用数据增强,如Mixup和CutMix,会导致较差的性能。在ImageNet-1K数据集上的实验表明,针对紧凑模型的专门训练策略适用于各种架构,包括GhostNetV2、MobileNetV2和ShuffleNetV2。具体来说,配备作者的策略,GhostNetV3 1.3X在移动设备上仅用2.69M FLOPs和14.46毫秒的延迟就实现了79.1%的top-1准确率,大大超过了通常训练的同类产品。此外还可以扩展到目标检测场景。
简单总结
当前各种高效架构,如MobileNetV1、MobileNetV2、GhostNet等,被广泛应用于移动设备中。然而,由于边缘设备的有限内存和计算资源,需要设计一种同时具备高效推理和高精度的紧凑模型。虽然目前有很多方法可以提高模型的效率,但直接将这些方法应用于紧凑模型可能会导致性能下降。因此,需要探索新的训练策略来提高紧凑模型的性能。本文通过对不同训练策略的研究,提出了一种适用于紧凑模型的强大训练策略。该策略主要包括学习率调整策略、数据增强、知识蒸馏和重参数化等方法,在GhostNetV2上的实验结果超越了其他训练策略,在其他架构上也有一定的通用性。
1 Introduction
为了满足边缘设备(如手机)有限的内存和计算资源,已经开发了各种高效的架构。例如,MobileNetV1使用深度可分离卷积来降低计算成本。MobileNetV2引入了残差连接,MobileNetV3通过神经架构搜索(NAS)进一步优化了架构配置,显著提高了模型的性能。另一个典型的架构是GhostNet,它利用特征中的冗余,并通过使用廉价的操作来复制特征的通道。最近,GhostNetV2进一步引入了硬件友好的注意力模块,以捕捉长程像素之间的依赖性,并显著优于GhostNet。
除了精心设计的模型架构外,适当的训练策略对于显著的性能也是至关重要的。例如,Wightman等人通过集成先进的优化和数据增强方法,将ImageNet-1K上的ResNet-50的top-1精度从76.1%提高到80.4%。然而,尽管已经做出了相当大的努力来探索传统模型(例如,ResNet和Vision Transformer)的更先进的训练策略,但很少关注紧凑模型。由于具有不同能力的模型可能具有不同的学习偏好,因此直接应用为传统模型设计的策略来训练紧凑型模型是不合适的。
为了弥补这一差距,作者系统地研究了紧凑型模型的几种训练策略。具体而言,主要注意力集中在先前工作中讨论的关键训练设置上,包括重参数化、知识蒸馏(KD)、学习计划和数据增强。
Re-parameterization.深度卷积和1×1卷积是紧凑模型架构中的常见组件,因为它们的内存和计算消耗可以忽略不计。受训练传统模型的成功经验的启发,对这两个紧凑模块采用了重参数化方法,以获得更好的性能。在训练紧凑模型时,将线性并行分支引入深度卷积和1×1卷积。这些额外的并行分支可以在训练后重参数化,在推理时不会带来额外的成本。为了权衡整体培训成本与效果改进,作者比较了不同数量的新增分支机构的影响。此外,作者还发现1×1深度卷积分支对3×3深度卷积的重参数化有显著的积极影响。
Knowledge distillation.紧凑型模型由于其有限的模型容量,难以实现与传统模型相当的性能。因此,KD采用更大的模型作为教师来指导紧凑模型的学习,是提高性能的合适方法。实证研究了使用KD训练紧凑模型时几个典型因素的影响,如教师模型的选择和超参数的设置。结果表明,适当的教师模型可以显著提高紧凑模型的性能。
Learning schedule and data augmentation. 作者比较了紧凑模型的几种训练设置,包括学习率、权重衰减、指数移动平均(EMA)和数据扩充。有趣的是,并非所有为传统模型设计的技巧都适用于紧凑型模型。例如,一些广泛使用的数据增强方法,如Mixup和CutMix,实际上会降低紧凑型模型的性能。作者将在第5节中详细讨论它们的效果。
作者为紧凑型模型开发了一个专门的训练配方。在ImageNet-1K数据集上的实验验证了所提出的方法的优越性。具体而言,用作者方法训练的GhostNetV2模型在top-1精度和延迟方面显著优于用以前的策略训练的模型(图1)。在MobileNetV2和ShuffleNetV2等其他高效架构上的实验进一步证实了所提出的配方的可推广性。

2 Related works
2.1 Compact models
设计一种同时具有低推理延迟和高性能的紧凑模型架构是一项挑战。SqueezeNet提出了三种策略来设计紧凑的模型,即用1×1滤波器替换3×3滤波器,将输入通道的数量减少到3×3滤波器,以及在网络后期下采样以保持大的特征图。这些原理是有建设性的,尤其是1×1卷积的使用。MobileNetV1用1×1的核和深度可分离卷积替换了几乎所有的滤波器,这大大降低了计算成本。MobileNetV2进一步将残差连接引入紧凑模型,并构建了一个反向残差结构,其中块的中间层具有比其输入和输出更多的通道。为了保持表示能力,去除了一部分非线性函数。MobileNeXt重新思考了反向瓶颈的必要性,并声称经典的瓶颈结构也可以实现高性能。考虑到1×1卷积占了很大一部分计算成本,ShuffleNet将其替换为group卷积。channel shuffle操作有助于信息在不同组之间流动。通过研究影响实际运行速度的因素,ShuffleNetV2提出了一种新的硬件友好块。
MnasNet和MobileNetV3搜索架构参数,如模型宽度、模型深度、卷积滤波器的大小等。通过利用特征的冗余,GhostNet用廉价的操作取代了1×1卷积中的一半通道。GhostNetV2提出了一种基于全连接层的DFC注意力,它不仅可以在通用硬件上快速执行,还可以捕捉长程像素之间的依赖关系。到目前为止,GhostNet系列仍然是SOTA紧凑型,在精度和速度之间有着良好的平衡。
自从ViT(DeiT)在计算机视觉任务上取得了巨大成功以来,研究人员一直致力于为移动设备设计紧凑的transformer架构。MobileFormer提出了一种紧凑的交叉注意力来建模MobileNet和transformer之间的双向桥梁。MobileViT借鉴了紧凑型CNN的成功经验,用使用transformer的全局处理取代了卷积中的局部处理。然而,由于复杂的注意力操作,基于transformer的紧凑模型在移动设备上存在高推理延迟。
2.2 Bag of tricks for training CNNs
有一些工作侧重于改进训练策略,以提高各种模型的性能。He等人讨论了几种对硬件上的有效训练有用的技巧,并为ResNet提出了一种新的模型架构调整。Wrightman等人在使用新的优化和数据增强方法进行训练时,重新评估了最初ResNet-50的性能。他们共享timm开源库中的竞争性训练设置和预训练的模型。通过他们的训练配方,最初的ResNet-50模型达到了80.4%的top-1准确率。Chen等人研究了几个基本组件对训练自监督ViT的影响。然而,所有这些尝试都是为大型模型或自监督模型设计的。由于它们的模型容量不同,直接将它们转移到紧凑型模型是不合适的。
3 Preliminary
GhostNets(GhostNetV1和GhostNetV2)是为在移动设备上进行高效推理而设计的最先进的紧凑型模型。他们的关键架构是Ghost模块,它可以通过廉价的操作生成更多的特征图来取代原来的卷积。
在普通卷积中,输出特征由
获得,其中
是卷积核,
是输入特征。
和
分别表示输入和输出通道尺寸。
是核大小,∗ 表示卷积运算。Ghost 模块通过两步减少了普通卷积的参数数量和计算成本。它首先产生intrinsic特征
,其通道维数小于原始特征
。然后,将廉价运算(例如,深度卷积)应用于intrinsic特征
以生成ghost特征
。最终输出是通过沿通道维度连接intrinsic特征和ghost特征获得的,可以表示为:

其中和
分别表示primary卷积和廉价运算中的参数。“Cat”表示连续操作。一个完整的 GhostNet 模型是通过堆叠多个 Ghost 模块来构建的。
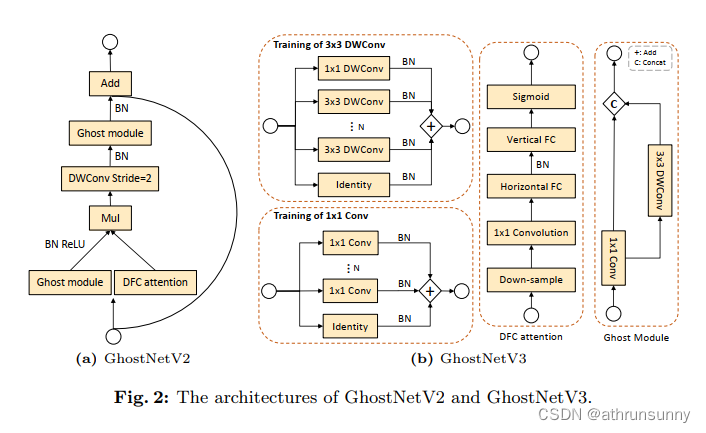
GhostNetV2 通过设计一个高效的注意力模块(即 DFC 注意力)来增强紧凑的模型。考虑到像 GhostNet 这样的紧凑模型通常使用小核卷积,例如 1×1 和 3×3,它们从输入特征中提取全局信息的能力较弱。GhostNetV2 采用简单的全连接层来捕获远距离空间信息并生成注意力图。为了提高计算效率,它将全局信息解耦为水平和垂直方向,并分别在两个方向聚合像素。如图2a所示,通过为Ghost模块配备DFC注意力,GhostNetV2可以有效地提取全局和局部信息,同时在精度和计算复杂度之间实现更好的权衡。
4 Training strategies
作者的目标是在不改变推理网络架构的情况下探索训练策略,以保持紧凑模型的小模型大小和快速度。实证研究了训练神经网络的关键因素,包括学习计划、数据增强、重参数化和知识蒸馏。
4.1Re-parameterization
重参数化在传统的卷积模型中已经证明了它的有效性。受到他们成功的启发,作者通过添加配备 BatchNorm层的重复分支,将重新参数化引入紧凑模型。作者的重新参数化 GhostNetV2 设计如图 2b 所示。值得注意的是,作者将 1×1 深度卷积分支引入到重参数化的 3×3 深度卷积中。实验结果证实了其对紧凑模型性能的积极影响。此外,实验还彻底探索了重复分支的最佳数量。
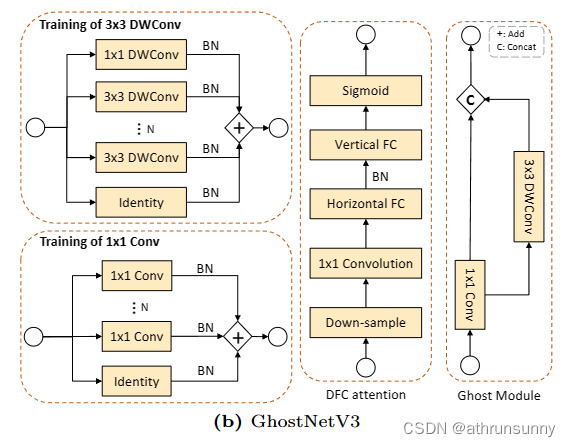
在推理时,可以通过逆向重参数化过程删除重复的分支。由于卷积和BatchNorm运算在推理过程中都是线性的,因此它们可以折叠成单个卷积层,其权重矩阵表示为偏置表示为
。之后,所有分支中的折叠权重和偏差可以重参数化为
和偏置
其中i是重复分支的索引。
4.2 Knowledge distillation
KD是一种广泛使用的模型压缩方法,其中大型预训练教师模型的预测被视为小型学生模型的学习目标。给定一个带有标签 y 的样本 x,分别表示学生和教师模型使用和
预测的相应对数,KD 的总损失函数可以表述为:

其中和
分别表示交叉熵损失和KD损失。
是一个平衡超参数。
通常采用Kullback-Leibler散度函数作为KD损失,可以表示为:
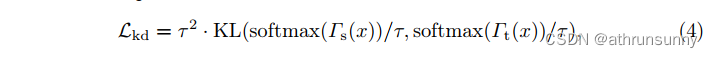
其中是称为温度的标签平滑超参数。实验中,研究了超参数
和
的不同设置对紧凑模型性能的影响。
4.3 Learning schedule
学习率是神经网络优化的关键参数。有两种常用的学习率调整策略:step和cosine。step策略线性降低学习率,而cosine策略开始时缓慢降低学习率,中间几乎呈线性,最后再次减慢。这项工作广泛研究了学习率和学习率调整策略对紧凑模型的影响。
指数移动平均线 (EMA) 最近已成为提高验证准确性和提高模型鲁棒性的有效方法。具体来说,它在训练期间逐渐平均模型的参数。假设step t的模型参数为,则模型的EMA计算为:
![]()
其中表示step t处 EMA 模型的参数,
是超参数。在第 5.3 节中研究了 EMA 的影响。
4.4 Data augmentation
已经提出了各种数据增强方法来提高传统模型的性能。其中,AutoAug方案采用25个子策略组合,每个子策略包含两个变换。对于每个输入图像,随机选择一个子策略组合,并决定是否在子策略中应用每个转换,该方法由一定的概率决定。RandomAug方法提出了一种随机增强方法,其中所有子策略都以相同的概率进行选择。Mixup和CutMix等融合两个图像以生成新图像。具体来说,Mixup在成对示例及其标签的组合上训练神经网络,而CutMix会随机从一张图像中删除一个区域,并用另一张图像中的patch替换相应的区域。RandomErasing随机选择图像中的矩形区域,并将其像素替换为随机值。
在本文中,评估了上述数据增强方法的各种组合,发现一些用于训练传统模型的常用数据增强方法,如Mixup和CutMix,并不适合训练紧凑模型。
5 Experimental results
在基本训练策略中,使用2048的小批量大小,并使用LAMB在600个epoch进行模型优化。初始学习率为0.005,采用余弦学习率调整策略。权重衰减和动量分别设置为0.05和0.9。对指数移动平均(EMA)使用0.9999的衰减因子,其中应用随机增强和随机擦除来进行数据增强。在本节中,将探讨这些训练策略,并揭示训练紧凑型模型的见解。所有实验都是在ImageNet数据集上使用8个NVIDIA特斯拉V100 GPU进行的。
5.1 Re-parameterization
为了更好地理解将重参数化集成到紧凑模型训练中的优势,进行了一项消融研究,以评估重参数化对不同大小的 GhostNetV2 的影响。结果如表1所示。与直接训练原始 GhostNetV2 模型相比,采用重参数化,同时保持其他训练设置不变,从而显著提高了性能。

此外,比较了重参数化因子N的不同配置,结果如表2所示。如结果所示,1×1深度卷积在重新参数化中起着至关重要的作用。如果在重新参数化模型中不使用 1×1 深度卷积,则其性能甚至会随着分支数量的增加而降低。相比之下,当配备 1×1 深度卷积时,GhostNetV3 模型在N为3时实现了 77.6% 的峰值top-1准确率,并且进一步增加N值不会带来额外的性能改进。因此,在随后的实验中将重新参数化因子N设置为 3,以获得更好的性能。
5.2 Knowledge distillation
在本节中,评估了知识蒸馏对GhostNetV3性能的影响。具体而言,采用ResNet-101、DeiT-B和BeiTV2B作为教师,分别获得77.4%、81.8%和86.5%的准确率。表3中的结果突出了不同教师模型的绩效差异。值得注意的是,出色的教师表现与GhostNetV3表现的改善相关,强调了性能良好的教师模型在使用紧凑模型进行知识蒸馏中的重要性。
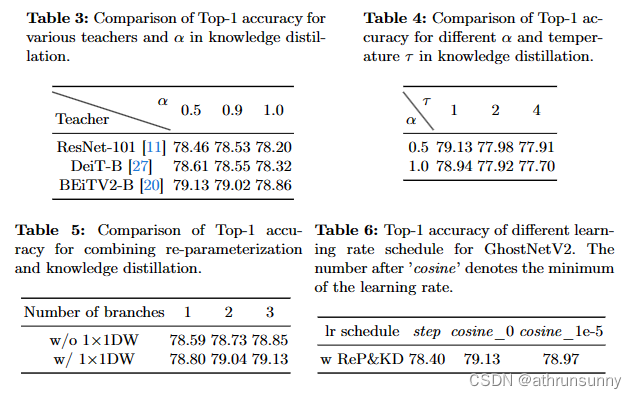
此外,还比较了以 BEiTV2-B 为教师的KD损失中不同超参数设置。表4中的结果表明,对于紧凑型模型,low temperature更可取。此外,值得注意的是,当单独使用KD损失时(即α=1.0),top-1精度明显下降。
还探讨了将重参数化和知识蒸馏相结合对GhostNetV2性能的影响。如表5所示,结果表明,由于利用了知识蒸馏,性能得到了显着提高(高达79.13%)。此外,它还强调了1×1深度卷积在重参数化中的重要性。这些发现强调了研究各种技术及其潜在组合以提高紧凑模型性能的重要性。
5.3 Learning schedule
Learning rate schedule. 图3显示了采用不同学习率调整策略的实验结果,包括重参数化和不重参数化和知识蒸馏。据观察,小学习率和高学习率都会对效果产生不利影响。因此,最终实验的学习率为5e-3。
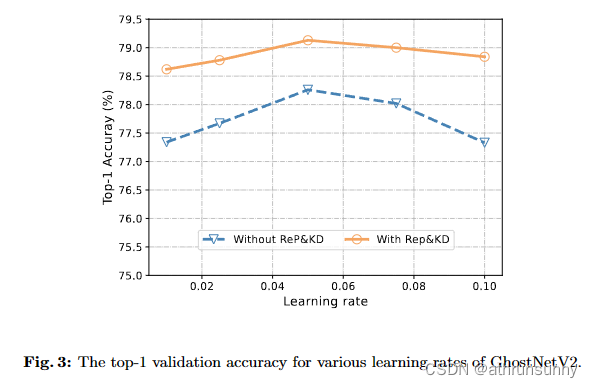
表6比较了step和cosine学习率调整策略。据观察,cosine学习率调整策略达到了最高的 top-1精度。这凸显了精心设计的cosine学习率调整策略在提高紧凑模型性能方面的有效性。
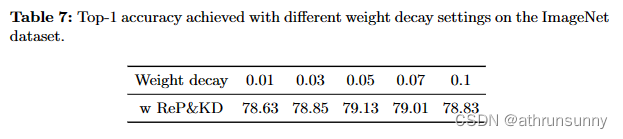
Weight decay. 权重衰减对 GhostNetV2 top-1精度的影响如表 7 所示。结果表明,较大的权重衰减会显著降低模型的性能。因此,鉴于GhostNetV2对紧凑模型的有效性,保留了 0.05 的权重衰减值。
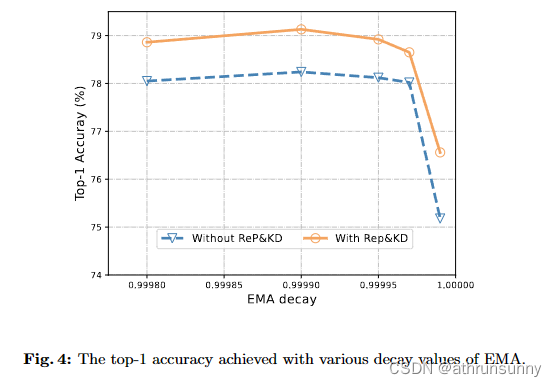
EMA.在图 4 中,可以观察到,当 EMA 衰减为 0.99999 时,无论是否使用重参数化和知识蒸馏技术,性能都会下降。推测这是由于当衰减值过大时当前迭代的减弱效应所致。对于紧凑模型,0.9999 或 0.99995 的衰减值被认为是合适的,这与传统模型的衰减值相似。
5.4 Data Augmentation
为了比较不同数据增强方案对轻量级模型性能的影响,训练了基于cnn的GhostNetV2和基于ViT的不同增强策略下的DeiT-tiny模型。结果如表8所示。据观察,随机增强和随机擦除对GhostNetV2 和DeiT-tiny都是有利的。相反,Mixup和CutMix具有不利影响,因此被认为不适合紧凑型模型。

5.5 Comparison with other compact models
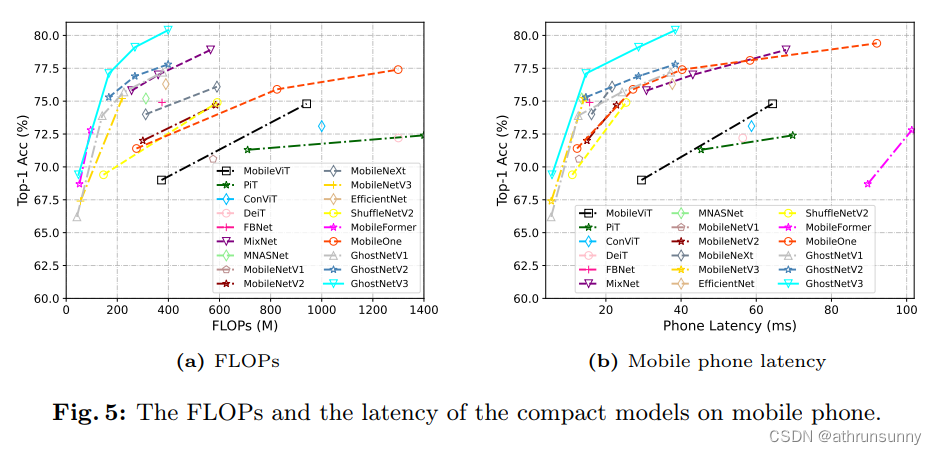
在本节中,将GhostNetV3与其他紧凑型模型在参数、FLOPs、CPU和手机延迟方面进行比较。具体来说,在配备3.2GHz Intel i7-8700 处理器的Windows桌面上运行这些模型来测量CPU延迟,并使用配备麒麟9000CPU的华为Mate40Pro以评估输入分辨率为224×224配置下的手机延迟。为了确保最低的延迟和最高的一致性,CPU和移动电话上的所有其他应用程序都将关闭。每个模型执行 100 次以获得可靠的结果。
表 9 提供了GhostNetV3与其他参数计数低于20M的紧凑型模型的详细比较。从结果来看,最小的基于Transformer的架构在移动设备上的推理需要12.5毫秒的延迟,而其top-1的准确率仅为 69.0%。相比之下,GhostNetV3实现了77.1%的top-1准确率,延迟显着降低至7.81毫秒。目前最先进的模型MobileFormer实现了79.3%的top-1准确率和129.58毫秒的延迟,这在实际应用中是无法承受的。相比之下,GhostNetV3 1.6× 实现了80.4%的更高准确率,延迟显着降低18.87ms,比 MobileFormer快6.8×。

接下来,将GhostNetV3与其他基于CNN的紧凑模型进行比较,包括 MobileNets、ShuffleNets、MixNet、MNASNet、FBNet、EfficientNet和MobileOne,其中FBNet、MNASNet和MobileNetV3 是基于搜索的模型,其他是手动设计的模型。具体来说,FBNet采用硬件搜索策略,而 MNASNet 和MobileNetV3搜索架构参数,例如模型宽度、模型深度、卷积滤波器的大小等。
与 MobileNetV2相比,GhostNetV2 1.0× 实现了 5.1% 的改进,同时保持了几乎相同的延迟(7.81 毫秒对 7.96 毫秒)。与 MobileNeXt 和 EfficientNet-B0 相比,GhostNetV2 1.3× 的 top-1 准确率也有所提高,分别为 3.0% 和 2.8%。特别是,与功能强大的手动设计的 MobileOne 型号相比,GhostNetV3 1.0× 在 top-1 精度方面比 MobileOne-S1 高出 1.2%,所需的延迟仅为一半。GhostNetV3 1.3× 的性能也比 MobileOne-S2 高出 1.7%,而延迟成本仅为 60%。此外,当 GhostNet 1.6× 达到比 MobileOne-S4 更高的 top-1 准确率(80.4% vs. 79.4%)时,MobileOne 的延迟在 CPU 上比 GhostNetV3 慢 2.8× 。
将 GhostNetV3 1.0× 与基于搜索的紧凑型模型进行比较时,它在 CPU 和手机上的推理速度都比 FBNet-C citefbnet 高出 2.2%。此外,与 MobileNetV3 和 MNASNet 相比,GhostNetV3 1.0× 提供了 1.9% 的 top-1 精度优势,同时保持了相似的延迟。结果表明,提出的训练策略在获得优秀的紧凑模型方面优于现有的手动设计和基于搜索的架构设计方法。
图 5 显示了各种紧凑型模型的综合性能比较。左图和右图分别说明了在移动电话上测量的 FLOPs 和延迟。值得注意的是,训练的 GhostNetV2 在移动设备上表现出延迟和 top-1 精度之间的最佳平衡,从而脱颖而出。
5.6 Extend to object detection
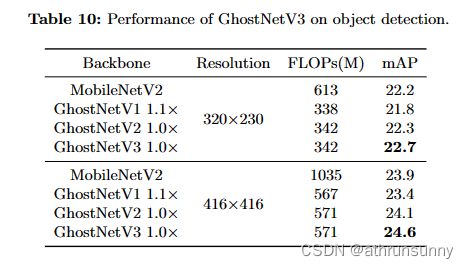
为了研究训练接收是否适用于其他数据集,将实验扩展到COCO上的目标检测任务,以验证它们的泛化。结果如表10所示。值得注意的是,分类任务中的见解适用于目标检测任务。例如,在两种使用的分辨率设置下,GhostNetV3模型分别比GhostNetV2高0.4和0.5的mAP。此外,GhostNetV3 的性能优于 MobileNetV2,同时需要更少的 FLOPs 进行推理。
这篇关于GhostNetV3:探索紧凑型模型的训练策略学习笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





