本文主要是介绍解决NVIDIA GeForce系列显卡NVENC并发Session数目限制问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
NVIDIA NVENC是NVIDIA显卡从2012年3月发布的Kepler-based GeForce 600系列引入的在视频编码方面的一个特性。较好地支持了显卡硬解码能力,加快视频解码速度。

我们在使用支持硬编码的NVIDIA GPU进行视频编码时,一般是支持多路并发的,但是对于不同系列的显卡并发数支持不一样。通过官网可以看到不同系列对多路编码的支持。
问题分析
在使用GeForce系列做多路并发编码时,发现一旦并发数目超过3个,则超过3个的线程在创建编码Session时会直接报错。
RuntimeError: NvEncoder : m_nvenc.nvEncOpenEncodeSessionEx(&encodeSessionExParams, &hEncoder) returned error 10
Description: EncodeAPI Internal Error.
很明显,这是编码Session创建失败了。
通过查表可知,消费级显卡诸如2080、3080系列均有编码并发数的限制。

具体对于2080Ti而言,可以看到Max # of concurrent sessions值为3,也就是最多支持3路并发。
而对于服务器型显卡,诸如A100、V100、T4等的编码并发数均没有相应的限制。

从算力程度对比看,这种并发数的限制应该不是由算力造成的,更可能是英伟达对消费级显卡故意设的一个槛。于是得想办法跨过这个人为设置的槛。

从维基百科词条“Nvidia NVENC”看到这样一段话:

Consumer targeted GeForce graphics cards officially support no more than 3 simultaneously encoding video streams, regardless of the count of the cards installed, but this restriction can be circumvented on Linux and Windows systems by applying an unofficial patch to the drivers. Professional cards support between 3 and unrestricted simultaneous streams per card, depending on card model and compression quality.
也就是说消费级显卡的硬编码并发数最多不超过3路,这个限制不是针对GPU的,而是针对整个系统的,即使你插了2张、4张甚至8张卡,那也最多只有3路编码能得到支持。而专业级(服务器级)显卡则不受此限制。
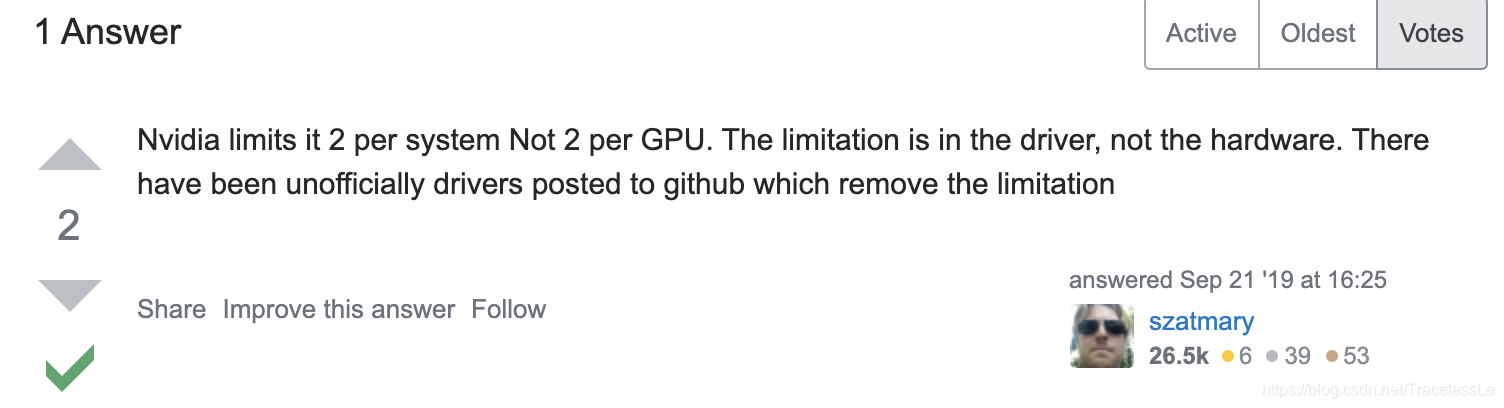
同时维基百科这段内容还提到,可以通过非官方的补丁包修复这一“bug”。
问题解决
从维基百科提供的链接找到该补丁包,可以看到描述如下:

这个补丁包能够移除相应的NVENC并发数限制,另外还提供了NVFBC的功能破解。由于暂时只用到NVENC,所以这里不管NVFBC。
作者也给出了受支持的驱动版本(详细版见相应网站):
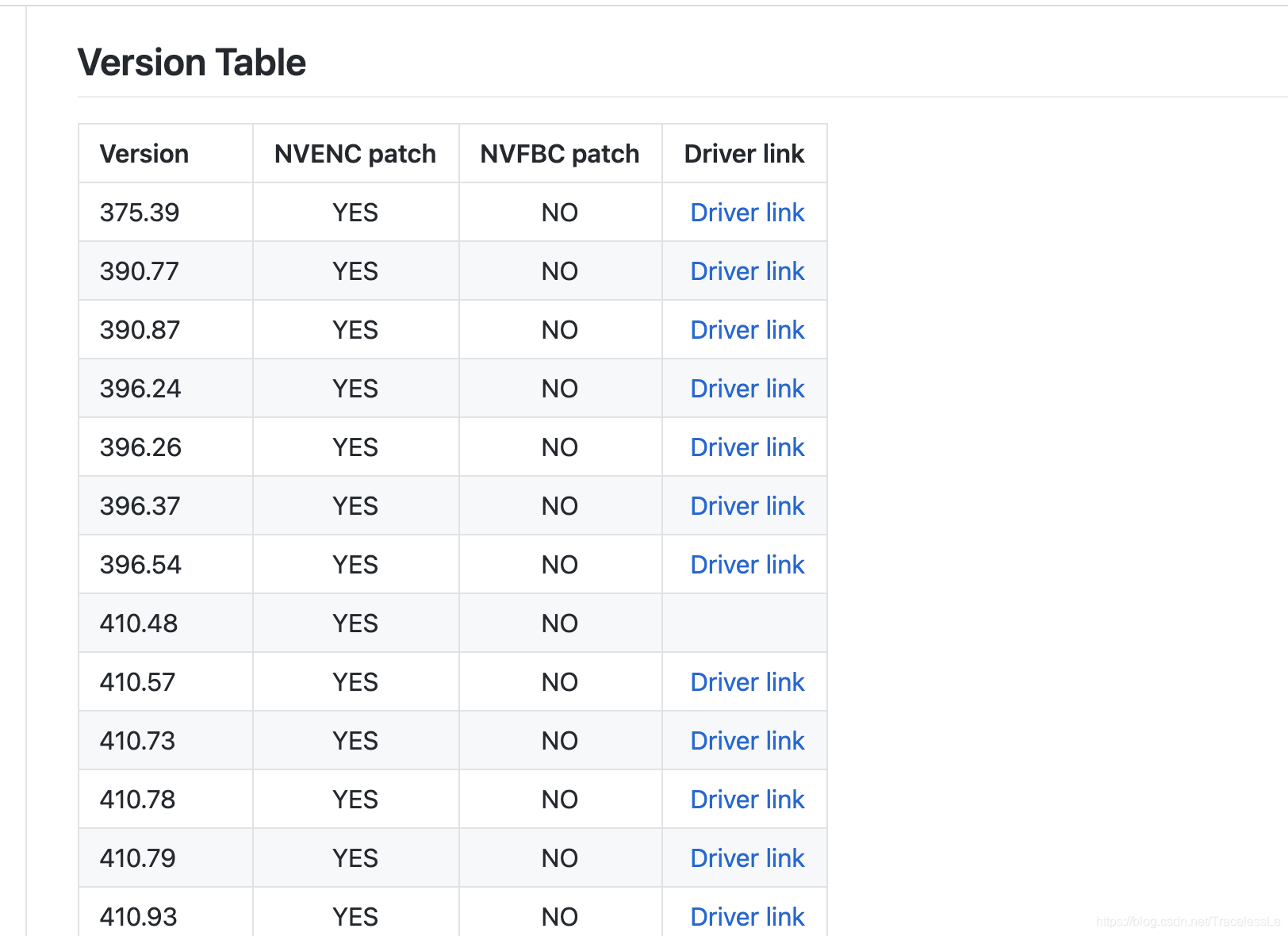
原理是根据不同版本驱动索引到“libnvcuvid.so”或者“libnvidia-encode.so”文件,对其中的相应限制部分的汇编代码做修改。
使用起来也很方便:
git clone https://github.com/keylase/nvidia-patch.git
给驱动打补丁:(注:这个补丁会先备份原始文件,避免出错以及便于还原。)
bash ./patch.sh
提示以下信息则说明打补丁完成:
Detected nvidia driver version: 455.23.05
Attention! Backup not found. Copying current libnvidia-encode.so to backup.
59f42f088a9585828b7f11622fc1ed4b32de80ed /opt/nvidia/libnvidia-encode-backup/libnvidia-encode.so.455.23.05
f9cb2306cb8b41eae74b7ed9f0adacf0409e8675 /usr/lib/x86_64-linux-gnu/libnvidia-encode.so.455.23.05Patched!
回滚(如果出问题可以回滚到原始版本):
bash ./patch.sh -r
打补丁后进行测试,发现原先的报错消失了。多个视频均能够被正常编码。

参考资料
[1] Video Encode and Decode GPU Support Matrix
[2] NVIDIA Video Codec SDK
[3] Nvidia NVENC - From Wikipedia, the free encyclopedia
[4] github - keylase / nvidia-patch
[5] github - keylase / nvidia-patch / patch.sh
[6] 突破NVIDIA NVENC并发Session数目限制
[7] NVIDIA Silently Increases GeForce NVENC Concurrent Sessions Limit to 3
[8] github - NVIDIA / NvPipe - Multiple encoder session for multiple users - best practice? #41
[9] Nvenc session limit per GPU
这篇关于解决NVIDIA GeForce系列显卡NVENC并发Session数目限制问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






