本文主要是介绍使用共振峰提取元音音素/从声音生成口型动画,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
视频效果
我前段时间研究了下从声音提取共振峰的方法。今天测试了下实际效果。
我使用一段33秒的女声视频,提取元音后使用静态视位图序列生成了一个视频,效果如下:
b站视频:
https://www.bilibili.com/video/BV1JD421H7m9/?vd_source=8abb7f0122649239c41b4c8acf458e47
https://www.bilibili.com/video/BV1i1421d7xU/?vd_source=8abb7f0122649239c41b4c8acf458e47
提取元音,生成视位序列
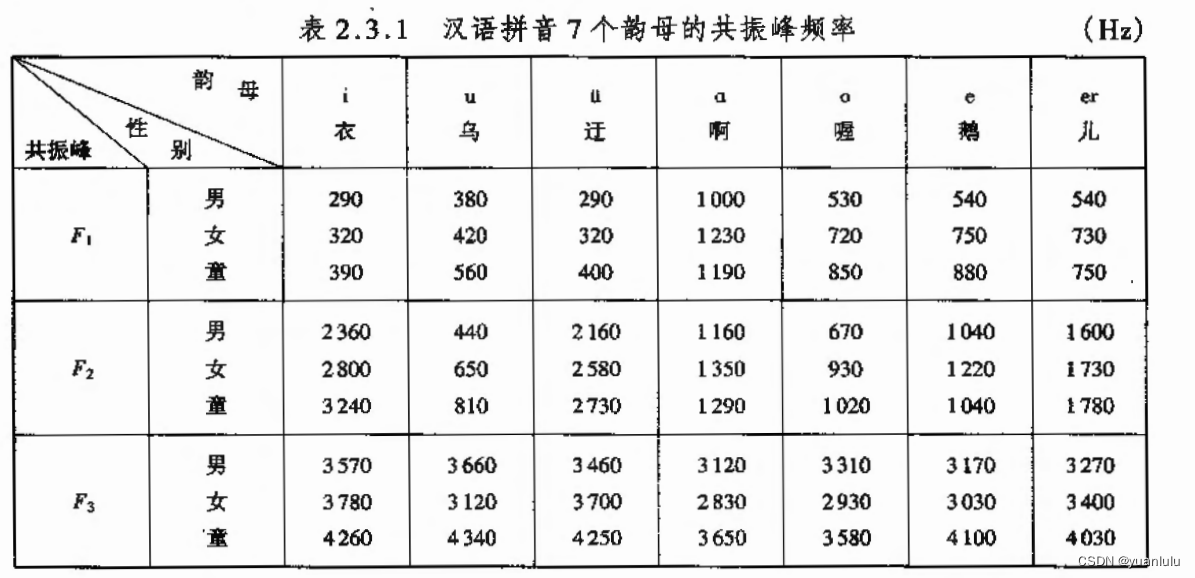
使用我前面一篇博客《使用python+librosa提取共振峰》中的方法可以提取音频文件的共振峰,使用三个共振峰作为三个坐标,和标准的元音共振峰求欧氏距离,距离最近的就是对应的元音。我使用了a\o\e\i\u五个元音。标准的元音共振峰数据我是参考的《实用语音识别基础—王炳锡》这本书的内容。
提取元音的代码如下:
import librosa
import numpy as np
from scipy.signal import lfilter, get_window
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
import mathdef func_format(x, pos):return "%d" % (1000 * x)class RhythmFeatures:"""韵律学特征"""def __init__(self, input_file, sr=None, frame_len=512, n_fft=None, win_step=2 / 3, window="hamming"):"""初始化:param input_file: 输入音频文件:param sr: 所输入音频文件的采样率,默认为None:param frame_len: 帧长,默认512个采样点(32ms,16kHz),与窗长相同:param n_fft: FFT窗口的长度,默认与窗长相同:param win_step: 窗移,默认移动2/3,512*2/3=341个采样点(21ms,16kHz):param window: 窗类型,默认汉明窗"""self.input_file = input_fileself.frame_len = frame_len # 帧长,单位采样点数self.wave_data, self.sr = librosa.load(self.input_file, sr=sr)self.window_len = frame_len # 窗长512if n_fft is None:self.fft_num = self.window_len # 设置NFFT点数与窗长相等else:self.fft_num = n_fftself.win_step = win_stepself.hop_length = round(self.window_len * win_step) # 重叠部分采样点数设置为窗长的1/3(1/3~1/2),即帧移(窗移)2/3self.window = windowdef energy(self):"""每帧内所有采样点的幅值平方和作为能量值:return: 每帧能量值,np.ndarray[shape=(1,n_frames), dtype=float64]"""mag_spec = np.abs(librosa.stft(self.wave_data, n_fft=self.fft_num, hop_length=self.hop_length,win_length=self.frame_len, window=self.window))pow_spec = np.square(mag_spec)energy = np.sum(pow_spec, axis=0)energy = np.where(energy == 0, np.finfo(np.float64).eps, energy) # 避免能量值为0,防止后续取log出错(eps是取非负的最小值)return energyclass Spectrogram:"""声谱图(语谱图)特征"""def __init__(self, input_file, sr=None, frame_len=512, n_fft=None, win_step=2 / 3, window="hamming", preemph=0.97):"""初始化:param input_file: 输入音频文件:param sr: 所输入音频文件的采样率,默认为None:param frame_len: 帧长,默认512个采样点(32ms,16kHz),与窗长相同:param n_fft: FFT窗口的长度,默认与窗长相同:param win_step: 窗移,默认移动2/3,512*2/3=341个采样点(21ms,16kHz):param window: 窗类型,默认汉明窗:param preemph: 预加重系数,默认0.97"""self.input_file = input_fileself.wave_data, self.sr = librosa.load(self.input_file, sr=sr) # 音频全部采样点的归一化数组形式数据self.wave_data = librosa.effects.preemphasis(self.wave_data, coef=preemph) # 预加重,系数0.97self.window_len = frame_len # 窗长512if n_fft is None:self.fft_num = self.window_len # 设置NFFT点数与窗长相等else:self.fft_num = n_fftself.hop_length = round(self.window_len * win_step) # 重叠部分采样点数设置为窗长的1/3(1/3~1/2),即帧移(窗移)2/3self.window = windowdef get_magnitude_spectrogram(self):"""获取幅值谱:fft后取绝对值:return: np.ndarray[shape=(1 + n_fft/2, n_frames), dtype=float32],(257,全部采样点数/(512*2/3)+1)"""# 频谱矩阵:行数=1 + n_fft/2=257,列数=帧数n_frames=全部采样点数/(512*2/3)+1(向上取整)# 快速傅里叶变化+汉明窗mag_spec = np.abs(librosa.stft(self.wave_data, n_fft=self.fft_num, hop_length=self.hop_length,win_length=self.window_len, window=self.window))return mag_specclass QualityFeatures:"""声音质量特征(音质)"""def __init__(self, input_file, sr=None, frame_len=512, n_fft=None, win_step=2 / 3, window="hamming"):"""初始化:param input_file: 输入音频文件:param sr: 所输入音频文件的采样率,默认为None:param frame_len: 帧长,默认512个采样点(32ms,16kHz),与窗长相同:param n_fft: FFT窗口的长度,默认与窗长相同:param win_step: 窗移,默认移动2/3,512*2/3=341个采样点(21ms,16kHz):param window: 窗类型,默认汉明窗"""self.input_file = input_fileself.frame_len = frame_len # 帧长,单位采样点数self.wave_data, self.sr = librosa.load(self.input_file, sr=sr)print(f"wave_data.shape:{self.wave_data.shape}")self.n_fft = n_fftself.window_len = frame_len # 窗长512self.win_step = win_step# 重叠部分采样点数设置为窗长的1/3(1/3~1/2),即帧移(窗移)2/3self.hop_length = round(self.window_len * win_step)self.window = windowdef formant(self, ts_e=0.01, ts_f_d=200, ts_b_u=2000):"""LPC求根法估计每帧前三个共振峰的中心频率及其带宽:param ts_e: 能量阈值:默认当能量超过0.01时认为可能会出现共振峰:param ts_f_d: 共振峰中心频率下阈值:默认当中心频率超过200,小于采样频率一半时认为可能会出现共振峰:param ts_b_u: 共振峰带宽上阈值:默认低于2000时认为可能会出现共振峰:return: F1/F2/F3、B1/B2/B3,每一列为一帧 F1/F2/F3或 B1/B2/B3,np.ndarray[shape=(3, n_frames), dtype=float64]"""_data = lfilter([1., 0.83], [1], self.wave_data) # 预加重0.83:高通滤波器inc_frame = self.hop_length # 窗移n_frame = int(np.ceil(len(_data) / inc_frame)) # 分帧数n_pad = n_frame * self.window_len - len(_data) # 末端补零数_data = np.append(_data, np.zeros(n_pad)) # 无法整除则末端补零win = get_window(self.window, self.window_len, fftbins=False) # 获取窗函数formant_frq = [] # 所有帧组成的第1/2/3共振峰中心频率formant_bw = [] # 所有帧组成的第1/2/3共振峰带宽rym = RhythmFeatures(self.input_file, self.sr,self.frame_len, self.n_fft, self.win_step, self.window)e = rym.energy() # 获取每帧能量值e = e / np.max(e) # 归一化for i in range(n_frame):f_i = _data[i * inc_frame:i * inc_frame + self.window_len] # 分帧if np.all(f_i == 0): # 避免上面的末端补零导致值全为0,防止后续求LPC线性预测误差系数出错(eps是取非负的最小值)f_i[0] = np.finfo(np.float64).epsf_i_win = f_i * win # 加窗# 获取LPC线性预测误差系数,即滤波器分母多项式,阶数为 预期共振峰数3 *2+2,即想要得到F1-3a = librosa.lpc(f_i_win, order=8)rts = np.roots(a) # 求LPC返回的预测多项式的根,为共轭复数对# 只保留共轭复数对一半,即虚数部分为+或-的根rts = np.array([r for r in rts if np.imag(r) >= 0])rts = np.where(rts == 0, np.finfo(np.float64).eps,rts) # 避免值为0,防止后续取log出错(eps是取非负的最小值)ang = np.arctan2(np.imag(rts), np.real(rts)) # 确定根对应的角(相位)# F(i) = ang(i)/(2*pi*T) = ang(i)*f/(2*pi)# 将以角度表示的rad/sample中的角频率转换为赫兹sample/sfrq = ang * (self.sr / (2 * np.pi))indices = np.argsort(frq) # 获取frq从小到大排序索引frequencies = frq[indices] # frq从小到大排序# 共振峰的带宽由预测多项式零点到单位圆的距离表示: B(i) = -ln(r(i))/(pi*T) = -ln(abs(rts[i]))*f/pibandwidths = -(self.sr / np.pi) * np.log(np.abs(rts[indices]))formant_f = [] # F1/F2/F3formant_b = [] # B1/B2/B3if e[i] > ts_e: # 当能量超过ts_e时认为可能会出现共振峰# 采用共振峰频率大于ts_f_d小于self.sr/2赫兹,带宽小于ts_b_u赫兹的标准来确定共振峰for j in range(len(frequencies)):if (ts_f_d < frequencies[j] < self.sr/2) and (bandwidths[j] < ts_b_u):formant_f.append(frequencies[j])formant_b.append(bandwidths[j])# 只取前三个共振峰if len(formant_f) < 3: # 小于3个,则补nanformant_f += ([np.nan] * (3 - len(formant_f)))else: # 否则只取前三个formant_f = formant_f[0:3]formant_frq.append(np.array(formant_f)) # 加入帧列表if len(formant_b) < 3:formant_b += ([np.nan] * (3 - len(formant_b)))else:formant_b = formant_b[0:3]formant_bw.append(np.array(formant_b))else: # 能量过小,认为不会出现共振峰,此时赋值为nanformant_frq.append(np.array([np.nan, np.nan, np.nan]))formant_bw.append(np.array([np.nan, np.nan, np.nan]))formant_frq = np.array(formant_frq).Tformant_bw = np.array(formant_bw).T# print(formant_frq.shape, np.nanmean(formant_frq, axis=1))# print(formant_bw.shape, np.nanmean(formant_bw, axis=1))return formant_frq, formant_bwdef plot(self, show=True):"""绘制语音波形曲线和log功率谱、共振峰叠加图:param show: 默认最后调用plt.show(),显示图形:return: None"""plt.figure(figsize=(8, 6))# 以下绘制波形图plt.subplot(2, 1, 1)plt.title("Wave Form")plt.ylabel("Normalized Amplitude")plt.xticks([])audio_total_time = int(len(self.wave_data) / self.sr * 1000) # 音频总时间msplt.xlim(0, audio_total_time)plt.ylim(-1, 1)x = np.linspace(0, audio_total_time, len(self.wave_data))plt.plot(x, self.wave_data, c="b", lw=1) # 语音波形曲线plt.axhline(y=0, c="pink", ls=":", lw=1) # Y轴0线# 以下绘制灰度对数功率谱图plt.subplot(2, 1, 2)spec = Spectrogram(self.input_file, self.sr, self.frame_len,self.n_fft, self.win_step, self.window, 0.83)log_power_spec = librosa.amplitude_to_db(spec.get_magnitude_spectrogram(), ref=np.max)librosa.display.specshow(log_power_spec[:, 1:], sr=self.sr, hop_length=self.hop_length,x_axis="s", y_axis="linear", cmap="gray_r")plt.title("Formants on Log-Power Spectrogram")plt.xlabel("Time/ms")plt.ylabel("Frequency/Hz")plt.gca().xaxis.set_major_formatter(mtick.FuncFormatter(func_format))# 以下在灰度对数功率谱图上叠加绘制共振峰点图formant_frq, __ = self.formant() # 获取每帧共振峰中心频率color_p = {0: ".r", 1: ".y", 2: ".g"} # 用不同颜色绘制F1-3点,对应红/黄/绿# X轴为对应的时间轴ms 从第0帧中间对应的时间开始,到总时长结束,间距为一帧时长x = np.linspace(0.5 * self.hop_length / self.sr,audio_total_time / 1000, formant_frq.shape[1])for i in range(formant_frq.shape[0]): # 依次绘制F1/F2/F3plt.plot(x, formant_frq[i, :], color_p[i], label="F" + str(i + 1))plt.legend(prop={'family': 'Times New Roman', 'size': 10}, loc="upper right",framealpha=0.5, ncol=3, handletextpad=0.2, columnspacing=0.7)plt.tight_layout()if show:plt.show()#男、女、儿童的标准元音共振峰位置,顺序:a\o\e\i\u
man_stand_f1 = [1000, 530, 540, 290, 380]
man_stand_f2 = [1160, 670, 1040, 2360, 440]
man_stand_f3 = [3120, 3310, 3170, 3570, 3660]
woman_stand_f1 = [1230, 720, 750, 320, 420]
woman_stand_f2 = [1350, 930, 1220, 2800, 650]
woman_stand_f3 = [2830, 2930, 3030, 3780, 3120]
child_stand_f1 = [1190, 850, 880, 390, 560]
child_stand_f2 = [1290, 1020, 1040, 3240, 810]
child_stand_f3 = [3650, 3580, 4100, 4260, 4340]def Distance(f1, f2, f3, stand_f1, stand_f2, stand_f3):return math.sqrt(math.pow(f1-stand_f1, 2) + math.pow(f2-stand_f2, 2) + math.pow(f3-stand_f3, 2)) #欧式距离#return math.sqrt(math.pow(f1-stand_f1, 2) + math.pow(f2-stand_f2, 2)) #欧式距离#根据和五个元音的共振峰的距离,返回对应的视位id, 1-5对应a\o\e\i\u
def Distance2Viseme(f1, f2, f3, stand_f1_vect, stand_f2_vect, stand_f3_vect):min_distance = 0min_index = 0dist_list = []for i in range(5):dist = Distance(f1, f2, f3, stand_f1_vect[i], stand_f2_vect[i], stand_f3_vect[i])dist_list.append(dist)if i == 0:min_distance = distmin_index = 0elif dist < min_distance:min_distance = distmin_index = i#print(f"f1:{f1}, f2:{f2}, f3:{f3}, min_index:{min_index}, min_distance:{min_distance}, dist_list:{dist_list}")return min_index+1, min_distance# 将共振峰序列转化为视素序列
def Formants2Viseme(fmt_frq, voice_type="child"):stand_f1 = man_stand_f1stand_f2 = man_stand_f2stand_f3 = man_stand_f3if voice_type == "men":stand_f1 = man_stand_f1stand_f2 = man_stand_f2stand_f3 = man_stand_f3elif voice_type == "women":stand_f1 = woman_stand_f1stand_f2 = woman_stand_f2stand_f3 = woman_stand_f3elif voice_type == "child":stand_f1 = child_stand_f1stand_f2 = child_stand_f2stand_f3 = child_stand_f3viseme_list = []dist_list = []for index in range(fmt_frq.shape[1]): #遍历每一帧if np.isnan(fmt_frq[0][index]) or np.isnan(fmt_frq[1][index]) or np.isnan(fmt_frq[2][index]):viseme_list.append(0) #静止视位dist_list.append(-1)else:idv, dist = Distance2Viseme(fmt_frq[0][index], fmt_frq[1][index], fmt_frq[2][index], stand_f1, stand_f2, stand_f3)if 1:#dist < 1500: #距离大于1000则认为是viseme_list.append(idv)dist_list.append(dist)else:viseme_list.append(0) #静止视位dist_list.append(-1)return viseme_list, dist_list# 调用声音质量特征,获取共振峰
#quality_features = QualityFeatures("audios/audio_raw.wav")
quality_features = QualityFeatures("xxx_00004.wav", frame_len=600, win_step=2/3) #窗口长度600, 步长400, 16K采样率下每秒40帧
#quality_features = QualityFeatures("audios/ae.wav")
fmt_frq, fmt_bw = quality_features.formant() # 3个共振峰中心频率及其带宽# 绘制波形图、功率谱,并叠加共振峰
#quality_features.plot(True)
print(f"fmt_frq.shape:{fmt_frq.shape}")
# print(f"fmt_frq:{fmt_frq}")#将共振峰序列转换为视位序列。 视位0~5分别对应:sil\a\o\e\i\u
viseme_list, dist_list = Formants2Viseme(fmt_frq, voice_type="child")
print(f"viseme_list.len:{len(viseme_list)}")
print(f"dist_list.len:{len(dist_list)}")print(f"viseme_list:{viseme_list}")
# print(f"dist_list:{dist_list}")
代码执行结果输出:
> python.exe .\test.py
wave_data.shape:(535200,)
fmt_frq.shape:(3, 1338)
viseme_list.len:1338
dist_list.len:1338
viseme_list:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 2, 4, 4, 4, 4, 4, 4, 2, 4, 0, 1, 4, 4, 4, 2, 4, 0, 0, 3, 3, 3, 5, 5, 3, 5, 0, 0, 0, 3, 3, 3, 3, 3, 4, 4, 4, 0, 4, 3, 2, 3, 3, 5, 3, 1, 2, 2, 1, 0, 0, 0, 0, 4, 4, 4, 3, 3, 3, 3, 3, 3, 3, 3, 3, 0, 4, 4, 2, 1, 1, 4, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 4, 2, 2, 4, 4, 4, 4, 5, 4, 4, 0, 4, 1, 2, 2, 4, 4, 4, 4, 4, 4, 1, 0, 0, 0, 3, 3, 2, 4, 4, 4, 4, 4, 2, 3, 2, 2, 3, 3, 3, 2, 2, 1, 1, 1, 4, 4, 0, 4, 0, 0, 0, 4, 4, 4, 0, 4, 0, 0, 2, 0, 4, 0, 0, 0, 0, 2, 2, 2, 2, 1, 1, 1, 1, 1, 4, 4, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 3, 3, 3, 4, 0, 0, 4, 4, 4, 2, 2, 2, 2, 3, 3, 3, 3, 3, 0, 0, 2, 2, 2, 2, 2, 4, 4, 4, 4, 4, 2, 4, 4, 0, 4, 1, 1, 5, 5, 0, 0, 2, 2, 2, 5, 2, 3, 3, 5, 4, 0, 4, 4, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 4, 4, 1, 4, 0, 4, 0, 2, 1, 3, 2, 0, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 0, 0, 4, 4, 4, 4, 4, 4, 4, 0, 0, 0, 0, 0, 4, 4, 4, 4, 5, 2, 2, 4, 4, 0, 0, 4, 4, 4, 1, 3, 3, 3, 2, 2, 3, 5, 3, 4, 0, 0, 0, 0, 3, 4, 0, 0, 0, 2, 1, 4, 0, 0, 0, 0, 0, 4, 4, 4, 4, 4, 4, 4, 3, 0, 5, 4, 4, 4, 0, 4, 0, 3, 3, 3, 5, 4, 4, 5, 5, 5, 5, 0, 4, 0, 4, 3, 1, 3, 3, 3, 5, 5, 4, 0, 0, 0, 3, 3, 3, 4, 0, 3, 3, 3, 0, 0, 4, 0, 4, 4, 3, 2, 3, 3, 3, 3, 3, 3, 0, 0, 0, 0, 4, 4, 3, 5, 5, 5, 0, 0, 4, 4, 4, 4, 4, 4, 4, 0, 3, 1, 3, 5, 2, 5, 5, 5, 3, 3, 3, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 0, 0, 4, 1, 1, 1, 2, 4, 4, 0, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 0, 0, 3, 2, 2, 3, 3, 5, 4, 2, 2, 0, 0, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 0, 0, 0, 0, 0, 3, 3, 3, 3, 4, 4, 0, 0, 0, 0, 0, 4, 4, 4, 4, 4, 4, 4, 0, 0, 0, 4, 4, 4, 4, 4, 4, 0, 0, 4, 4, 4, 4, 4, 4, 4, 4, 4, 2, 2, 0, 4, 0, 0, 0, 0, 3, 5, 5, 5, 5, 5, 0, 0, 5, 3, 3, 3, 3, 5, 3, 3, 3, 3, 3, 1, 3, 3, 0, 0, 4, 3, 3, 2, 2, 4, 4, 4, 4, 4, 4, 4, 4, 0, 0, 4, 4, 1, 5, 4, 0, 0, 0, 3, 3, 3, 2, 2, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 4, 3, 5, 2, 2, 2, 1, 1, 1, 1, 1, 1, 2, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 3, 3, 3, 3, 3, 3, 3, 4, 0, 0, 4, 2, 1, 3, 3, 3, 3, 3, 5, 4, 0, 0, 0, 0, 5, 5, 0, 0, 0, 4, 2, 2, 2, 2, 4, 4, 0, 0, 0, 0, 4, 4, 4, 4, 4, 0, 0, 3, 3, 5, 5, 2, 5, 0, 0, 1, 1, 2, 3, 5, 2, 2, 2, 4, 0, 0, 0, 4, 4, 4, 4, 4, 0, 0, 4, 2, 2, 2, 4, 5, 0, 0, 0, 4, 2, 2, 2, 5, 5, 5, 5, 3, 0, 0, 0, 0, 4, 1, 3, 3, 3, 5, 0, 0, 0, 0, 5, 5, 3, 3, 4, 0, 0, 4, 1, 3, 3, 3, 2, 3, 4, 0, 4, 0, 4, 4, 3, 2, 2, 2, 3, 0, 0, 0, 0, 0, 3, 3, 5, 5, 3, 3, 5, 5, 4, 4, 0, 0, 0, 0, 4, 4, 4, 0, 3, 3, 3, 3, 3, 0, 4, 4, 4, 4, 4, 4, 1, 1, 1, 2, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 4, 0, 0, 4, 4, 4, 4, 0, 0, 0, 4, 4, 4, 4, 4, 4, 0, 0, 0, 5, 0, 3, 3, 2, 5, 5, 0, 0, 0, 5, 5, 5, 4, 0, 0, 0, 4, 4, 0, 0, 0, 3, 5, 3, 3, 3, 3, 5, 3, 3, 3, 3, 3, 2, 4, 0, 0, 0, 0, 0, 2, 2, 2, 3, 5, 5, 5, 2, 2, 0, 5, 0, 3, 3, 3, 3, 2, 0, 4, 0, 4, 0, 2, 2, 2, 3, 3, 3, 0, 0, 1, 2, 3, 3, 3, 4, 4, 4, 4, 4, 4, 0, 0, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 2, 5, 0, 0, 5, 5, 3, 2, 2, 4, 0, 0, 0, 2, 2, 3, 3, 3, 2, 4, 0, 0, 4, 4, 4, 4, 4, 0, 0, 4, 0, 0, 0, 5, 0, 0, 0, 3, 3, 3, 3, 4, 4, 0, 0, 4, 4, 3, 5, 5, 5, 3, 4, 4, 4, 4, 0, 0, 3, 2, 3, 3, 5, 0, 0, 0, 0, 4, 3, 3, 3, 3, 3, 2, 3, 3, 2, 2, 4, 4, 0, 4, 4, 0, 4, 4, 1, 4, 4, 0, 0, 3, 5, 5, 0, 4, 0, 0, 3, 3, 3, 5, 5, 5, 0, 0, 0, 0, 4, 4, 4, 4, 4, 4, 0, 1, 1, 4, 0, 1, 2, 2, 2, 1, 4, 4, 4, 4, 0, 4, 0, 3, 3, 3, 3, 3, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 3, 3, 3, 3, 5, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 4, 4, 1, 4, 4, 0, 1, 3, 2, 2, 3, 5, 4, 0, 0, 5, 3, 3, 3, 0, 0, 1, 4, 2, 2, 4, 4, 0, 0, 0, 4, 1, 1, 3, 3, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 3, 3, 5, 0, 0, 3, 2, 2, 5, 3, 3, 3, 2, 2, 3, 3, 1, 1, 1, 3, 3, 4, 0, 0, 4, 4, 4, 4, 3, 3, 3, 3, 5, 4, 0, 0, 0, 3, 3, 5, 5, 5, 0, 0, 5, 2, 2, 2, 2, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
上面代码中检测共振峰的是这么一行:
quality_features = QualityFeatures("xxx_00004.wav", frame_len=600, win_step=2/3) #窗口长度
由于音频采样率是16000,frame_len传入的是600, 则音频分帧后每一个音频切片对应(600/16000)*1000=37.5ms。win_step为2/3,也就是音频帧中心间隔400次采样,对应25ms,所以每秒音频会产生40个语音切片,最终生成的视位fps对应40fps。
音频文件中共535200次采样,最终分帧数为1338。算出音频时长是1338x25ms=33450ms。
输出结果中最重要的就是viseme_list这个变量,它就是我们的视位序列。他的长度是1338,也就是共1338个视位。这个变量是下一步要用的。视位序列内容是0~5的数字,0表示静音状态,1-5分别表示a\o\e\i\u的嘴型视位。
代码中我同时列出了男性、女性和儿童的参考共振峰,发现我的这段测试音频用儿童的参考共振峰效果最好。
视位静止图片
从微软:将音素映射到视素可以看到很多因素对应的视位。我选取了a\o\e\i\u的对应的5张图片对应的视位,存到一个名称为viseme的目录下,如下
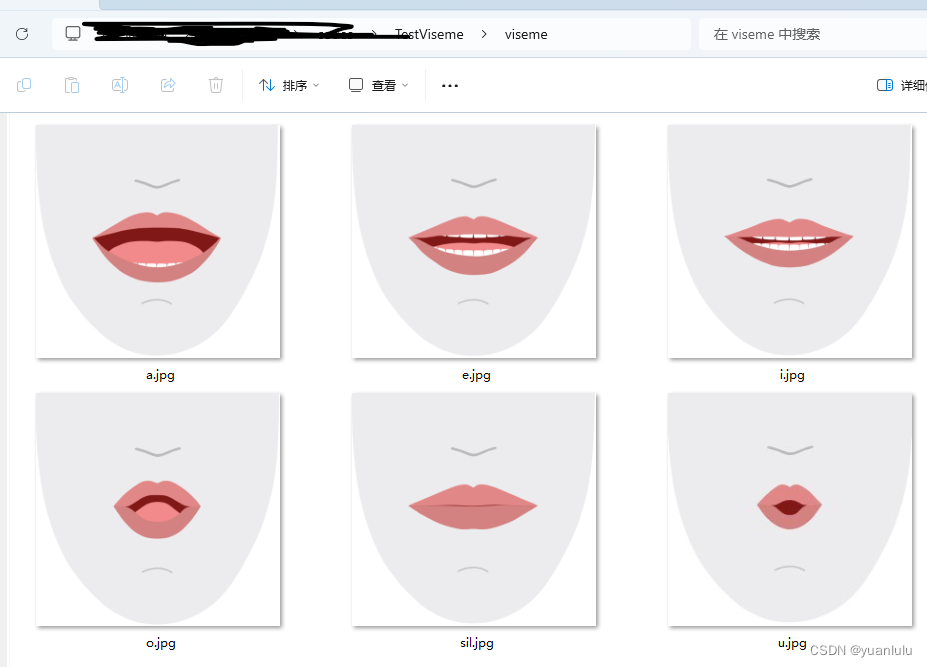
这里有个坑,那就是这些图片的像素尺寸不是严格一致的,需要在画图板中手工调整尺寸统一。我统一调整到(901, 859)。
将视位序列保存为视频
将上面执行输出的viseme_list复制过来,使用opencv将视位图片保存成视频。
由于上面生成的视位fps是40,我在生成视频前将视位id做了滤波,也就是每4个位置进行统计,压缩为一个视位,压缩后的视位就是4个位置上出现最多的视位。所以我生成的视频是10fps的。
从视位序列生成视位视频的代码如下
import cv2
import math#将上一步的元音分析结果拷贝过来
# child, 3fs
viseme_list = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 2, 4, 4, 4, 4, 4, 4, 2, 4, 0, 1, 4, 4, 4, 2, 4, 0, 0, 3, 3, 3, 5, 5, 3, 5, 0, 0, 0, 3, 3, 3, 3, 3, 4, 4, 4, 0, 4, 3, 2, 3, 3, 5, 3, 1, 2, 2, 1, 0, 0, 0, 0, 4, 4, 4, 3, 3, 3, 3, 3, 3, 3, 3, 3, 0, 4, 4, 2, 1, 1, 4, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 4, 2, 2, 4, 4, 4, 4, 5, 4, 4, 0, 4, 1, 2, 2, 4, 4, 4, 4, 4, 4, 1, 0, 0, 0, 3, 3, 2, 4, 4, 4, 4, 4, 2, 3, 2, 2, 3, 3, 3, 2, 2, 1, 1, 1, 4, 4, 0, 4, 0, 0, 0, 4, 4, 4, 0, 4, 0, 0, 2, 0, 4, 0, 0, 0, 0, 2, 2, 2, 2, 1, 1, 1, 1, 1, 4, 4, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 3, 3, 3, 4, 0, 0, 4, 4, 4, 2, 2, 2, 2, 3, 3, 3, 3, 3, 0, 0, 2, 2, 2, 2, 2, 4, 4, 4, 4, 4, 2, 4, 4, 0, 4, 1, 1, 5, 5, 0, 0, 2, 2, 2, 5, 2, 3, 3, 5, 4, 0, 4, 4, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 4, 4, 1, 4, 0, 4, 0, 2, 1, 3, 2, 0, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 0, 0, 4, 4, 4, 4, 4, 4, 4, 0, 0, 0, 0, 0, 4, 4, 4, 4, 5, 2, 2, 4, 4, 0, 0, 4, 4, 4, 1, 3, 3, 3, 2, 2, 3, 5, 3, 4, 0, 0, 0, 0, 3, 4, 0, 0, 0, 2, 1, 4, 0, 0, 0, 0, 0, 4, 4, 4, 4, 4, 4, 4, 3, 0, 5, 4, 4, 4, 0, 4, 0, 3, 3, 3, 5, 4, 4, 5, 5, 5, 5, 0, 4, 0, 4, 3, 1, 3, 3, 3, 5, 5, 4, 0, 0, 0, 3, 3, 3, 4, 0, 3, 3, 3, 0, 0, 4, 0, 4, 4, 3, 2, 3, 3, 3, 3, 3, 3, 0, 0, 0, 0, 4, 4, 3, 5, 5, 5, 0, 0, 4, 4, 4, 4, 4, 4, 4, 0, 3, 1, 3, 5, 2, 5, 5, 5, 3, 3, 3, 1, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 0, 0, 4, 1, 1, 1, 2, 4, 4, 0, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 0, 0, 3, 2, 2, 3, 3, 5, 4, 2, 2, 0, 0, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 0, 0, 0, 0, 0, 3, 3, 3, 3, 4, 4, 0, 0, 0, 0, 0, 4, 4, 4, 4, 4, 4, 4, 0, 0, 0, 4, 4, 4, 4, 4, 4, 0, 0, 4, 4, 4, 4, 4, 4, 4, 4, 4, 2, 2, 0, 4, 0, 0, 0, 0, 3, 5, 5, 5, 5, 5, 0, 0, 5, 3, 3, 3, 3, 5, 3, 3, 3, 3, 3, 1, 3, 3, 0, 0, 4, 3, 3, 2, 2, 4, 4, 4, 4, 4, 4, 4, 4, 0, 0, 4, 4, 1, 5, 4, 0, 0, 0, 3, 3, 3, 2, 2, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 4, 3, 5, 2, 2, 2, 1, 1, 1, 1, 1, 1, 2, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 3, 3, 3, 3, 3, 3, 3, 4, 0, 0, 4, 2, 1, 3, 3, 3, 3, 3, 5, 4, 0, 0, 0, 0, 5, 5, 0, 0, 0, 4, 2, 2, 2, 2, 4, 4, 0, 0, 0, 0, 4, 4, 4, 4, 4, 0, 0, 3, 3, 5, 5, 2, 5, 0, 0, 1, 1, 2, 3, 5, 2, 2, 2, 4, 0, 0, 0, 4, 4, 4, 4, 4, 0, 0, 4, 2, 2, 2, 4, 5, 0, 0, 0, 4, 2, 2, 2, 5, 5, 5, 5, 3, 0, 0, 0, 0, 4, 1, 3, 3, 3, 5, 0, 0, 0, 0, 5, 5, 3, 3, 4, 0, 0, 4, 1, 3, 3, 3, 2, 3, 4, 0, 4, 0, 4, 4, 3, 2, 2, 2, 3, 0, 0, 0, 0, 0, 3, 3, 5, 5, 3, 3, 5, 5, 4, 4, 0, 0, 0, 0, 4, 4, 4, 0, 3, 3, 3, 3, 3, 0, 4, 4, 4, 4, 4, 4, 1, 1, 1, 2, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 4, 4, 0, 0, 4, 4, 4, 4, 0, 0, 0, 4, 4, 4, 4, 4, 4, 0, 0, 0, 5, 0, 3, 3, 2, 5, 5, 0, 0, 0, 5, 5, 5, 4, 0, 0, 0, 4, 4, 0, 0, 0, 3, 5, 3, 3, 3, 3, 5, 3, 3, 3, 3, 3, 2, 4, 0, 0, 0, 0, 0, 2, 2, 2, 3, 5, 5, 5, 2, 2, 0, 5, 0, 3, 3, 3, 3, 2, 0, 4, 0, 4, 0, 2, 2, 2, 3, 3, 3, 0, 0, 1, 2, 3, 3, 3, 4, 4, 4, 4, 4, 4, 0, 0, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 2, 5, 0, 0, 5, 5, 3, 2, 2, 4, 0, 0, 0, 2, 2, 3, 3, 3, 2, 4, 0, 0, 4, 4, 4, 4, 4, 0, 0, 4, 0, 0, 0, 5, 0, 0, 0, 3, 3, 3, 3, 4, 4, 0, 0, 4, 4, 3, 5, 5, 5, 3, 4, 4, 4, 4, 0, 0, 3, 2, 3, 3, 5, 0, 0, 0, 0, 4, 3, 3, 3, 3, 3, 2, 3, 3, 2, 2, 4, 4, 0, 4, 4, 0, 4, 4, 1, 4, 4, 0, 0, 3, 5, 5, 0, 4, 0, 0, 3, 3, 3, 5, 5, 5, 0, 0, 0, 0, 4, 4, 4, 4, 4, 4, 0, 1, 1, 4, 0, 1, 2, 2, 2, 1, 4, 4, 4, 4, 0, 4, 0, 3, 3, 3, 3, 3, 3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 3, 3, 3, 3, 5, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 4, 4, 1, 4, 4, 0, 1, 3, 2, 2, 3, 5, 4, 0, 0, 5, 3, 3, 3, 0, 0, 1, 4, 2, 2, 4, 4, 0, 0, 0, 4, 1, 1, 3, 3, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 3, 3, 5, 0, 0, 3, 2, 2, 5, 3, 3, 3, 2, 2, 3, 3, 1, 1, 1, 3, 3, 4, 0, 0, 4, 4, 4, 4, 3, 3, 3, 3, 5, 4, 0, 0, 0, 3, 3, 5, 5, 5, 0, 0, 5, 2, 2, 2, 2, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]# 视位帧间隔,单位ms. 25对应fps是40
viseme_time = 25
# 对视位进行滤波的时候,会对每filter_interval个进行投票,得票多的视位为当前的视位
filter_interval = 4#读取视位的图片
viseme_sil_mat = cv2.imread("./viseme/sil.jpg")
viseme_a_mat = cv2.imread("./viseme/a.jpg")
viseme_o_mat = cv2.imread("./viseme/o.jpg")
viseme_e_mat = cv2.imread("./viseme/e.jpg")
viseme_i_mat = cv2.imread("./viseme/i.jpg")
viseme_u_mat = cv2.imread("./viseme/u.jpg")viseme_mat = [viseme_sil_mat, viseme_a_mat, viseme_o_mat, viseme_e_mat, viseme_i_mat, viseme_u_mat]#这里实现滤波,在filter_interval个帧中选投票个数最多的视位作为滤波后的新视位
#假设输入视位是N个,滤波后的视位是N/filter_interval个
def filter4viseme(old_viseme_list, filter_interval=5):new_viseme_list = []new_frame_num = math.ceil(len(old_viseme_list)/filter_interval) # 向上取整for i in range(new_frame_num):vote_list = [0, 0, 0, 0, 0, 0] #6个视位的投票箱for x in range(i*filter_interval, (i+1)*filter_interval):if x >= len(old_viseme_list): #如果超出范围则停止循环breakviseme_id = old_viseme_list[x]vote_list[viseme_id] += 1max_vote = max(vote_list) #求列表最大值max_viseme_id = vote_list.index(max_vote) #求最大值对应的下标print(f"max_viseme_id:{max_viseme_id}, max_vote:{max_vote}, vote_list:{vote_list}")new_viseme_list.append(max_viseme_id)print(f"len(new_viseme_list):{len(new_viseme_list)}")print(f"new_viseme_list:{new_viseme_list}")return new_viseme_list# 对视位进行滤波平滑,每filter_interval压缩为1个
filted_viseme_list = filter4viseme(viseme_list, filter_interval)fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter('testwrite-child10fps3f.mp4', fourcc, 1000/viseme_time/filter_interval, (901, 859), True)
# out = cv2.VideoWriter('testwrite-new.avi', fourcc, 20, (901, 859), True)#读取压缩后的视位id,按照顺序写入视频文件
for index in range(len(filted_viseme_list)):viseme_id = filted_viseme_list[index]frame = viseme_mat[viseme_id]out.write(frame)cv2.imshow("viseme", frame)print(f"{index}/{len(filted_viseme_list)}, viseme_id={viseme_id} | ")if cv2.waitKey(1) == 27:breakout.release()
cv2.destroyAllWindows()
代码运行后在代码目录下生成estwrite-child10fps3f.mp4文件,使用剪辑软件加上声音,就做成了一个完整的视频了。
参考资料
使用python+librosa提取共振峰
《实用语音识别基础—王炳锡》
微软:将音素映射到视素
这篇关于使用共振峰提取元音音素/从声音生成口型动画的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

